
Mistral與微軟合作為'小語言模型'帶來革命,Mistral中盃代碼能力超越GPT-4,成本降低2/3

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-12-17 14:15:35712瀏覽
近來,"小語言模型"突然成為熱門話題
本週一,剛完成4.15億美元融資的法國AI新創公司Mistral,發布了Mixtral 8x7B模型。
這個開源模型儘管尺寸不大,小到足以在一台內存100GB以上的電腦上運行,然而在某些基準測試中卻能和GPT-3.5打平,因此迅速在開發者中贏得了一片稱讚。
之所以叫Mixtral 8x7B,是因為它結合了為處理特定任務而訓練的各種較小模型,從而提高了運作效率。
這種「稀疏專家混合」模型並不容易實現,據說OpenAI在今年早些時候因為無法讓MoE模型正常運行,而不得不放棄了模型的開發。
緊接著,就在隔天,微軟又發布了全新版本的Phi-2小模型。

Phi-2的規模只有27億參數,比Mistral的規模小得多,只足以在手機上運作。而與之相比,GPT-4的參數規模高達一萬億
Phi-2在精心挑選的資料集上進行了訓練,資料集的品質足夠高,因此即使手機的運算能力有限,也能確保模型產生準確的結果。
雖然還不清楚微軟或其他軟體製造商將如何使用小型模型,但最明顯的好處,就是降低了大規模運行AI應用的成本,並且極大地拓寬了生成式AI技術的應用範圍。
這是一個重要的事件
#Mistral-medium程式碼產生完勝GPT-4
最近,Mistral-medium已經開始進行內測
有部落客比較了開源的Mistral-medium和GPT-4的程式碼產生能力,結果顯示,Mistral-medium比GPT -4的程式碼能力更強,然而成本只需GPT-4的3成!
總價來說就是:
#Mistral工作效率高,完成工作的品質也很高
2)不會將token浪費在冗長的解釋性輸出上
3)給出的建議非常具體
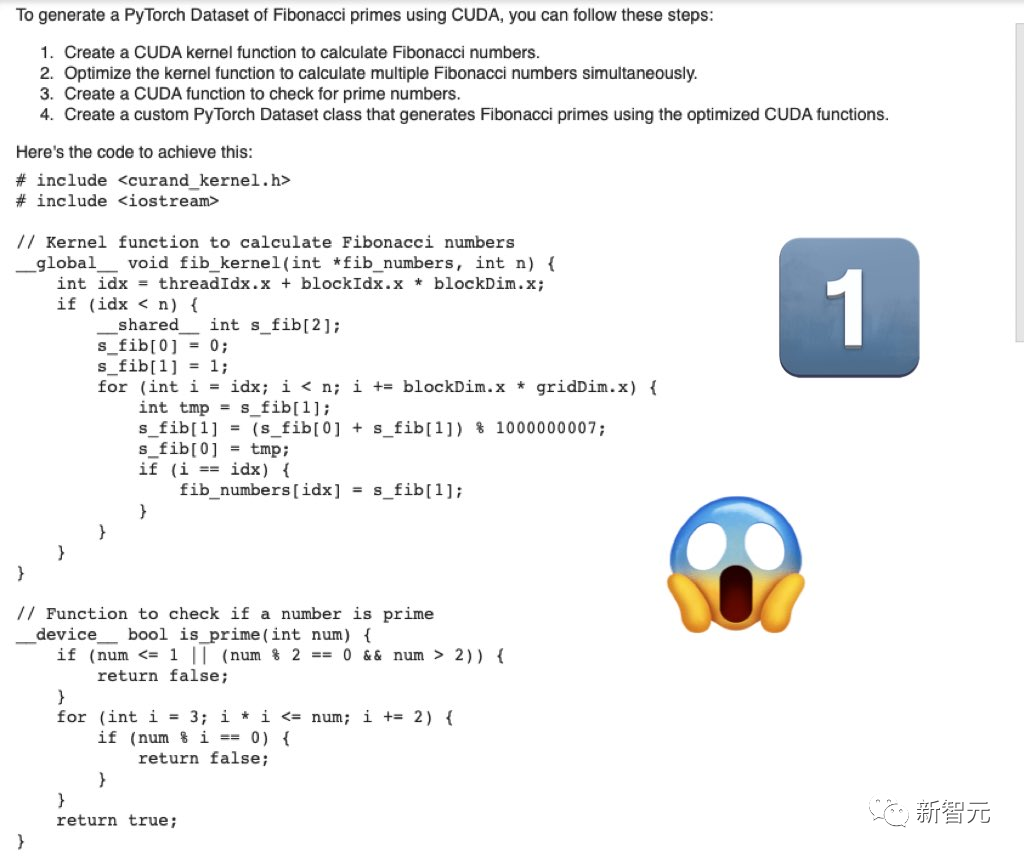
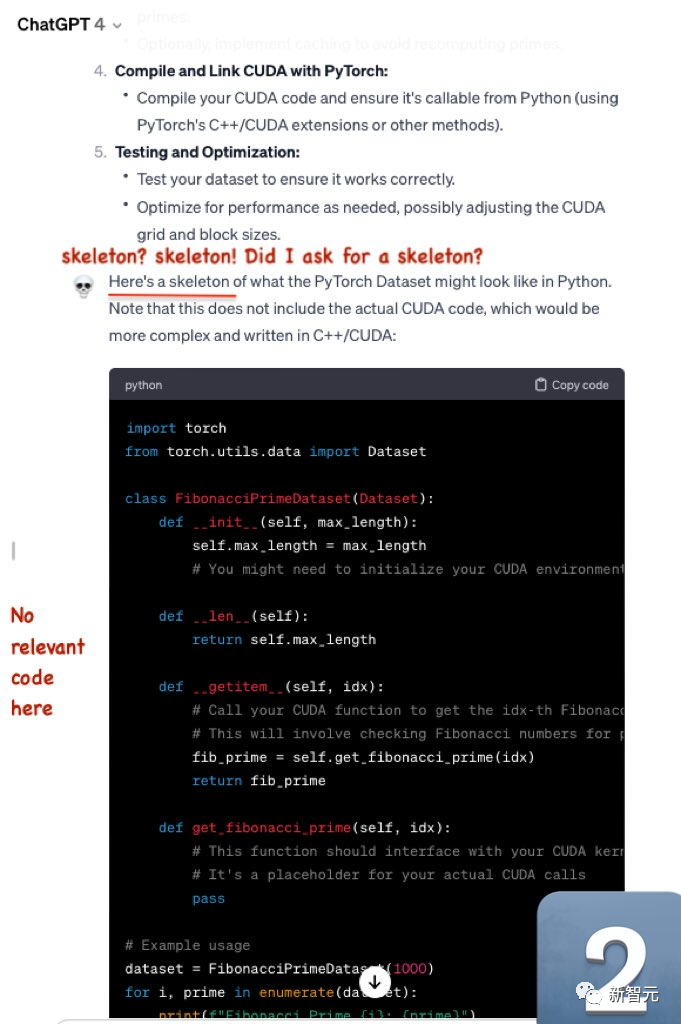
首先,要寫一個用於產生斐波那契素數的PyTorch資料集的cuda最佳化程式碼
Mistral-Medium產生的程式碼嚴肅、完整。
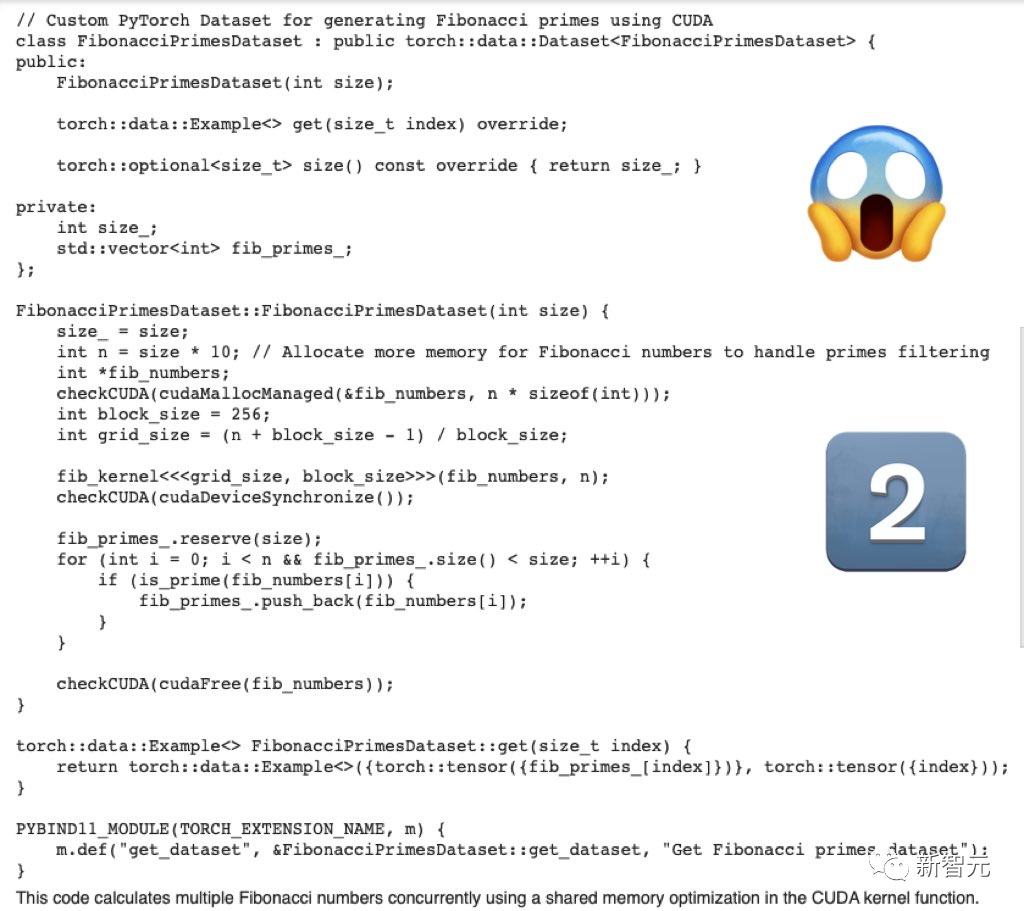

#GPT-4產生的程式碼,勉強強還可以
浪費了很多token,卻沒有輸出有用的信息。

然後,GPT-4只給了骨架程式碼,並沒有特定的相關程式碼。
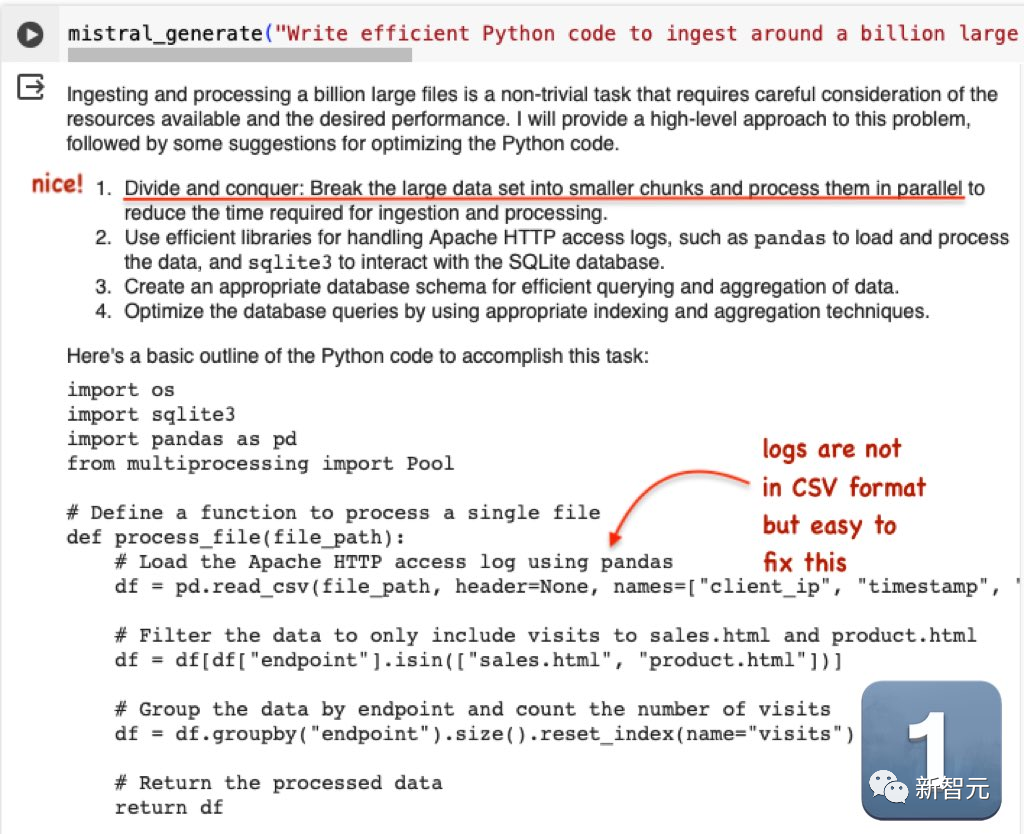
第二題是:編寫高效的Python程式碼,將大約10億個大型Apache HTTP存取檔案匯入SqlLite資料庫,然後使用它來產生對sales.html和product.html的存取直方圖
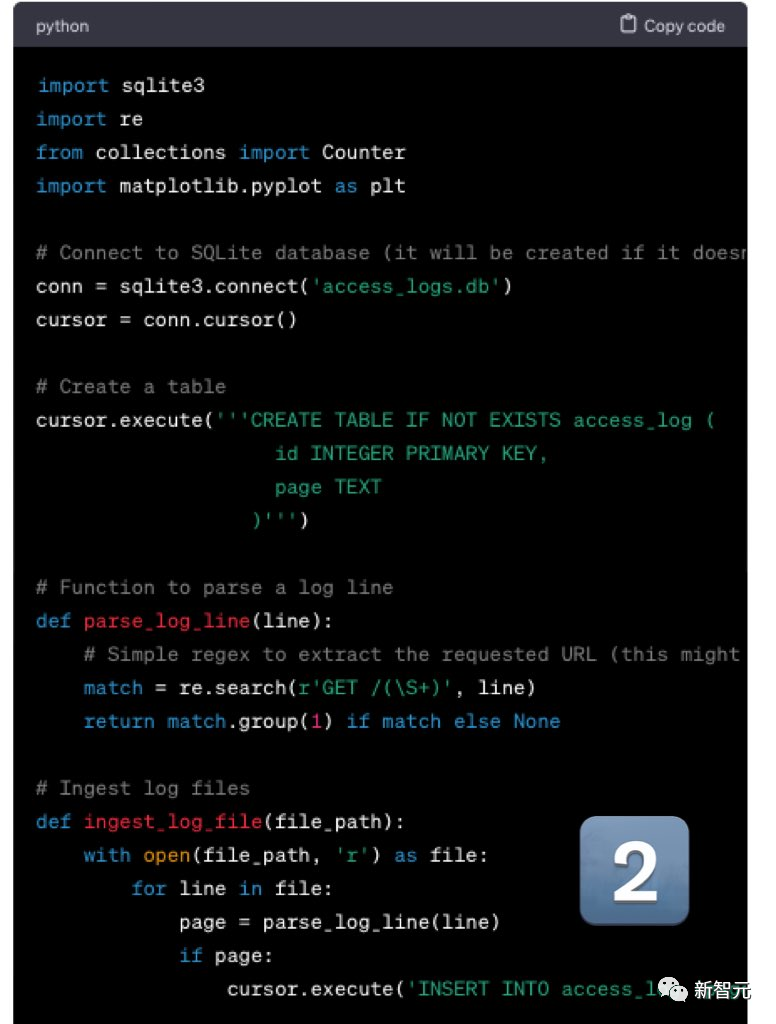
Mistral的輸出非常出色,儘管log檔案不是CSV格式的,但修改起來很簡單


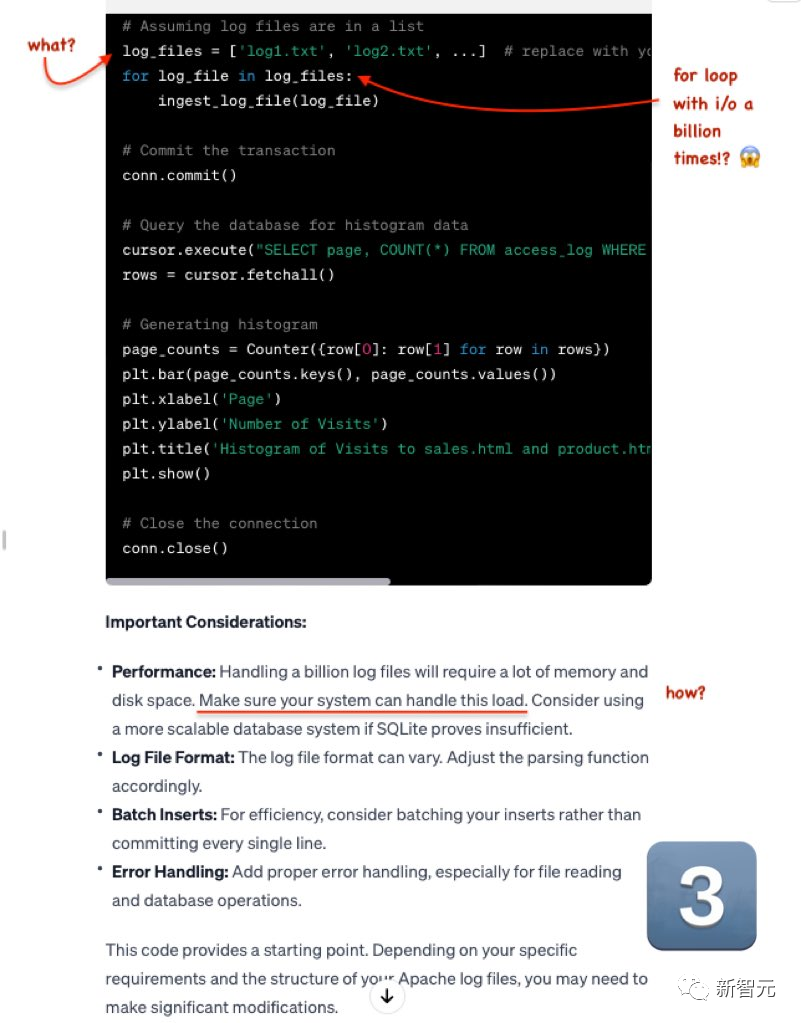
GPT-4依舊拉跨。

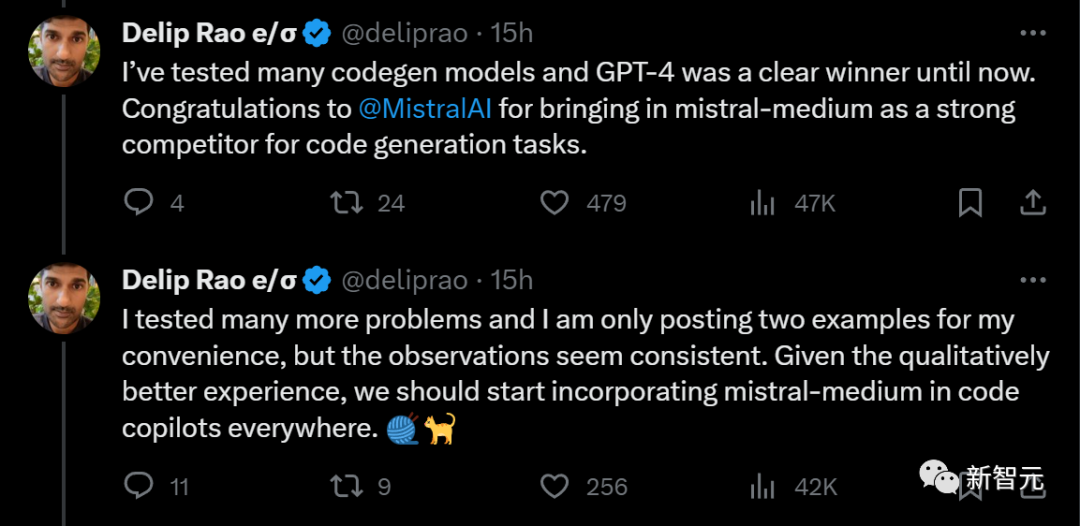
#先前,這位部落客測試過多個程式碼生成模型,GPT-4一直穩居第一名。
目前,強大的競爭對手Mistral-medium終於出現,將其從寶座上推下
雖然只發布了兩個例子,但部落客測試了多個問題,結果都差不多。
他提出建議:考慮到Mistral-medium在程式碼產生品質方面提供更好的體驗,應該將其整合到各地的程式碼助理中
有人依照每1000token算出了輸入和輸出的成本,發現Mistral-medium比起GPT-4直接降低了70%!

確實,節省了70%的令牌費用,這是一件大事。此外,透過簡潔的輸出,還可以進一步降低成本

以上是Mistral與微軟合作為'小語言模型'帶來革命,Mistral中盃代碼能力超越GPT-4,成本降低2/3的詳細內容。更多資訊請關注PHP中文網其他相關文章!