
解鎖GPT-4與Claude2.1:一句話帶你實現100k+上下文大模型的真實力,將27分提升至98

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-12-15 11:37:37827瀏覽
各家大模型紛紛捲起上下文窗口,Llama-1時標配還是2k,現在不超過100k的已經不好意思出門了。
然鵝一項極限測試卻發現,大部分人用法都不對,沒發揮出AI應有的實力。
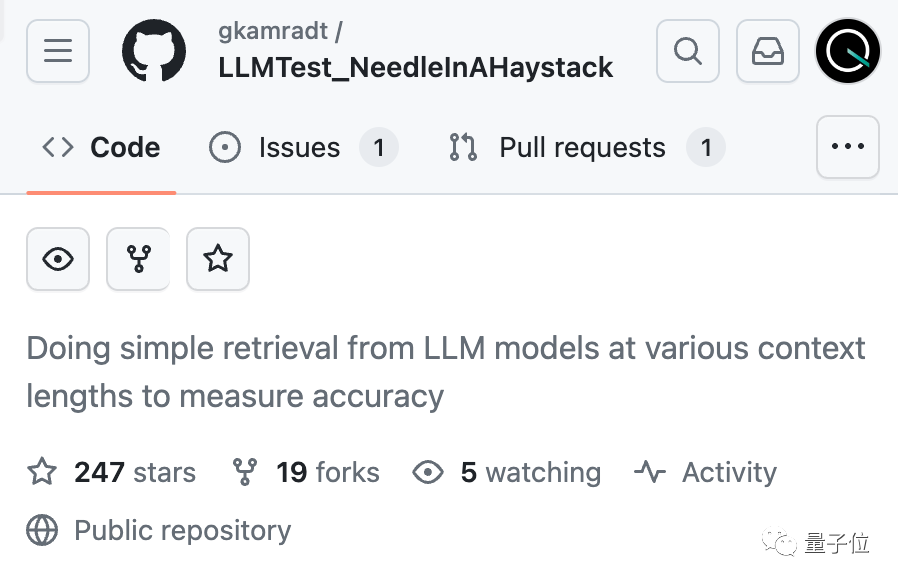
AI真的能從幾十萬字中準確找到關鍵事實嗎? 顏色越紅代表AI犯的錯越多。
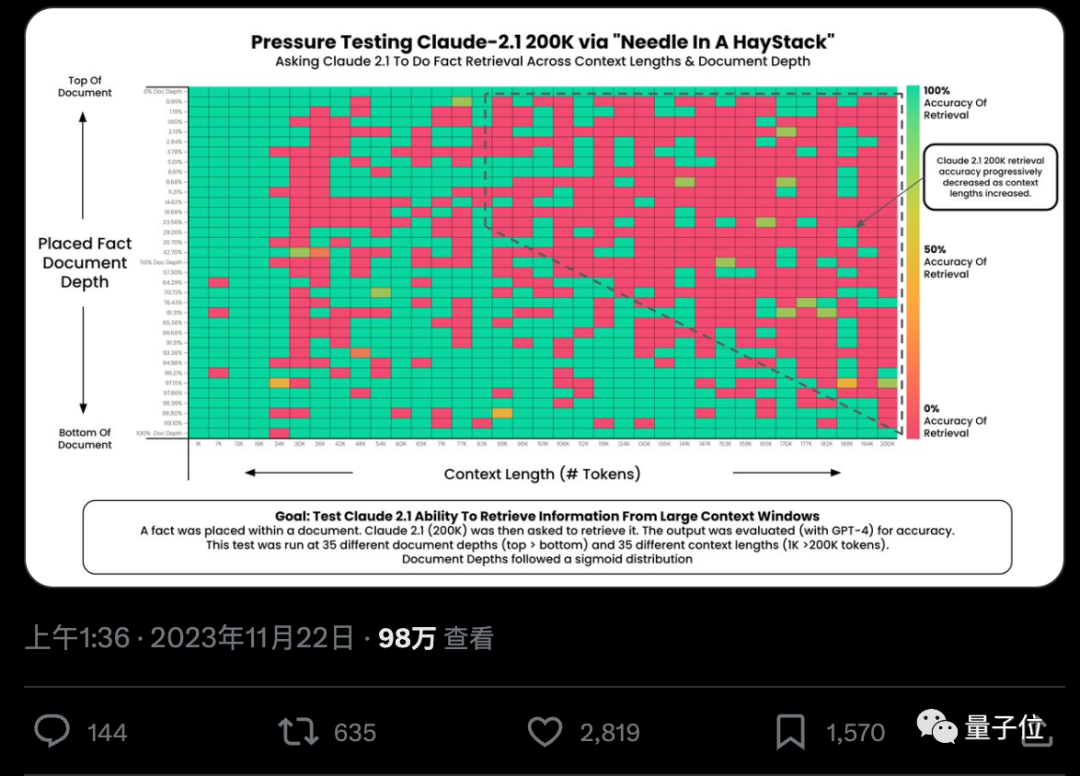
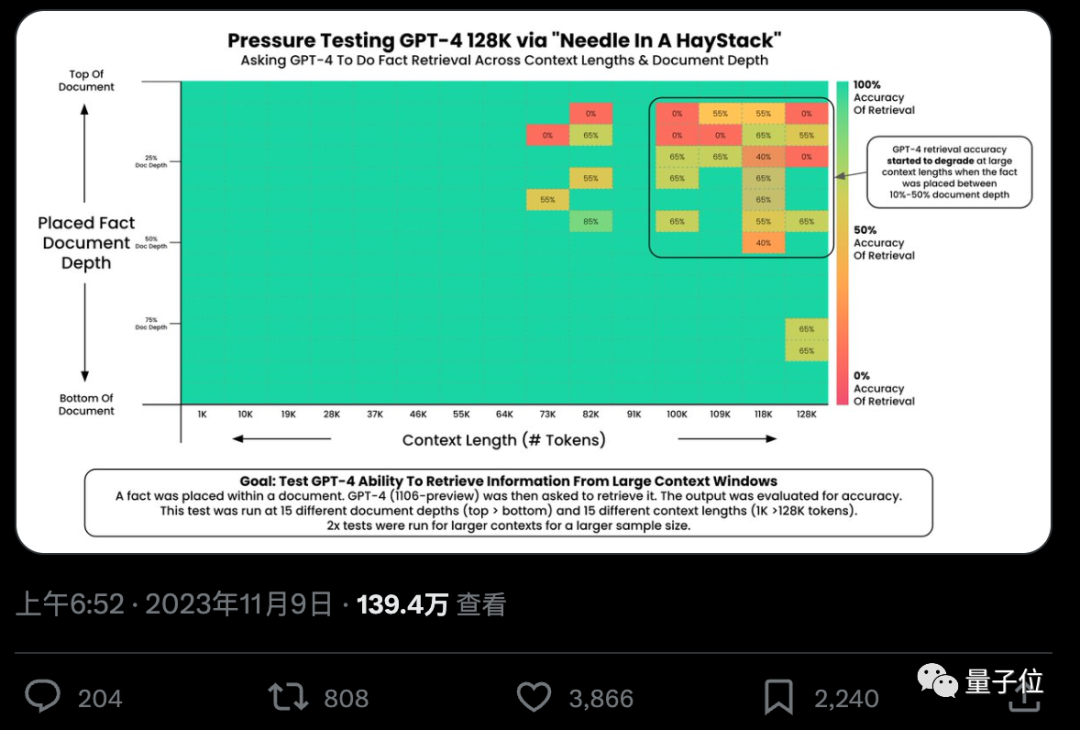
預設情況下,GPT-4-128k和最新發布的Claude2.1-200k成績都不太理想。
但Claude團隊了解狀況後,給予超簡單解決辦法,增加一句話,直接把成績從27%提升到98%。
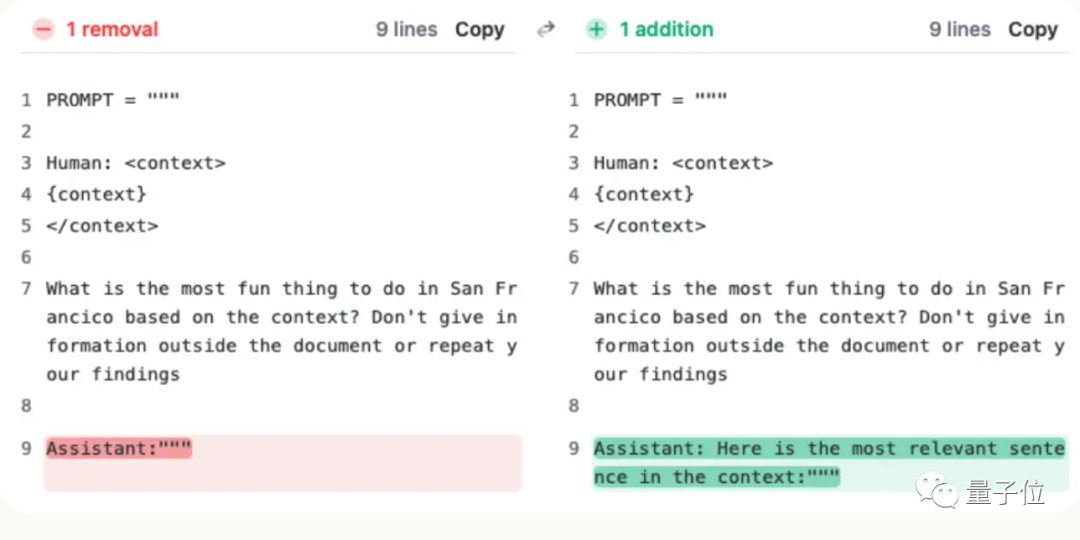
#只不過這句話不是加在使用者提問上的,而是讓AI在回覆的開頭先說:
“Here is the most relevant sentence in the context:”
#(這就是上下文中最相關的句子:)
讓大模型大海撈針
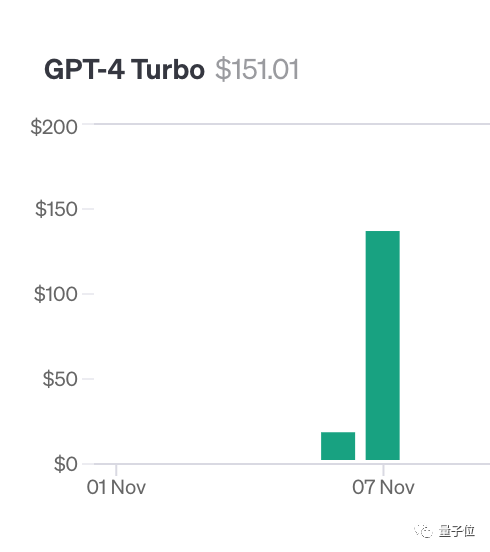
為了做這項測試,作者Greg Kamradt自掏腰包花了至少150美元。
在測試Claude2.1時,Anthropic提供了免費額度給他,幸好這樣他就不用花費額外的1016美元了
其實測試方法也不複雜,都是選用YC創辦人Paul Graham的218篇部落格文章當做測試數據。
在文件的不同位置添加特定的語句:舊金山最美好的事情就是在陽光明媚的日子裡,坐在多洛雷斯公園,享用一份三明治
請使用所提供的上下文來回答問題,在不同上下文長度和添加在不同位置的文檔中,反覆測試GPT-4和Claude2.1

最終使用Langchain Evals庫對結果進行評估
作者把這套測試命名為“乾草堆裡找針/大海撈針”,並把代碼開源在GitHub上,已獲得200 星,並透露已經有公司贊助了對下一個大模型的測試。
AI公司自己找到解決方案
幾週後,Claude背後公司Anthropic仔細分析後卻發現,AI只是不願意回答基於文件中單一句子的問題,特別是這個句子是後來插入的,和整篇文章關係不大的時候。
換句話說,如果AI判斷這句話與文章主題無關,則會採取不查找每句話的方法

這時就需要用點手段晃過AI,要求Claude在回答開頭加上那句「Here is the most relevant sentence in the context:」就能解決。
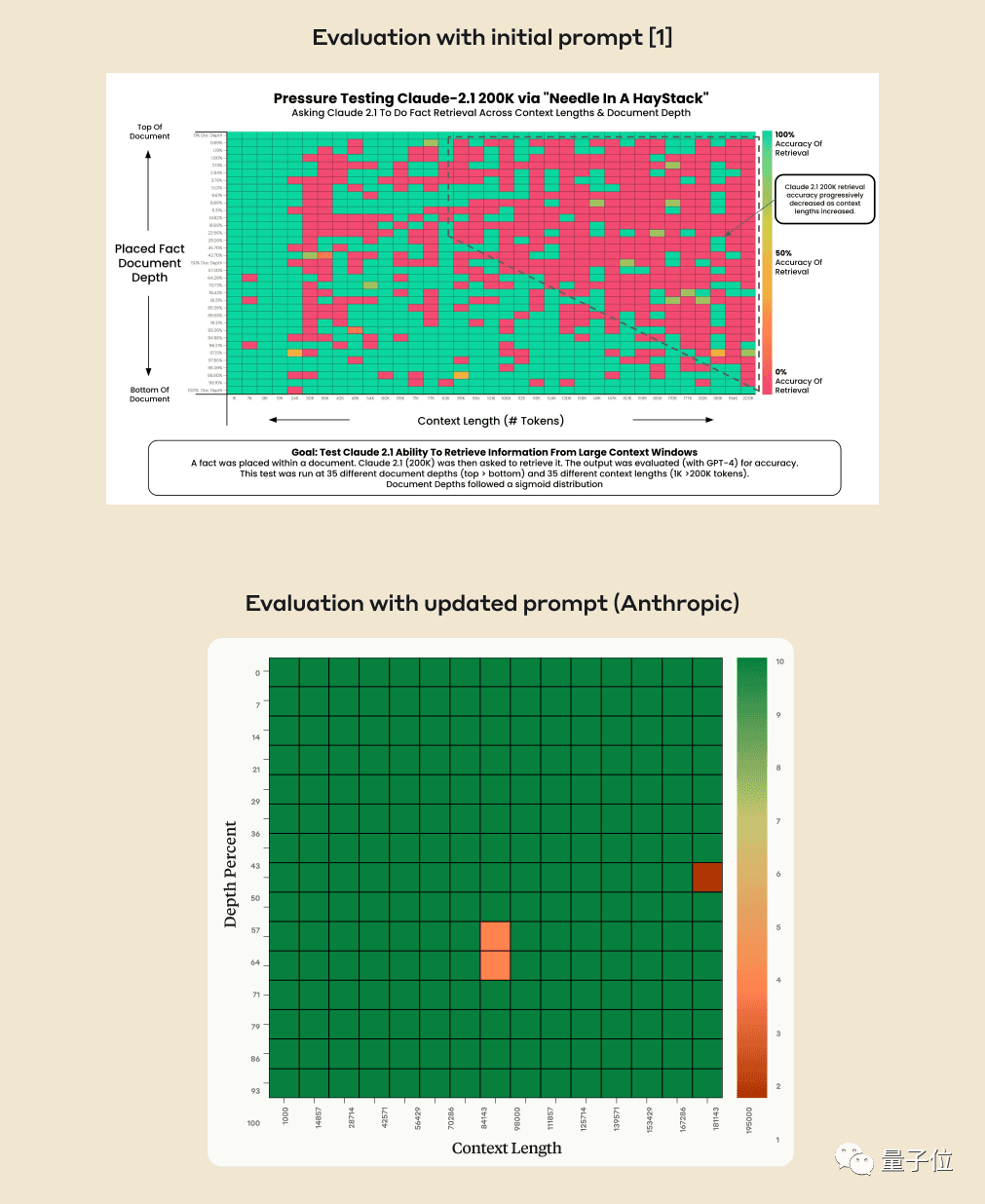
使用這種方法可以提高Claude的表現,即使在尋找原文中未被人為添加的句子時也可以如此
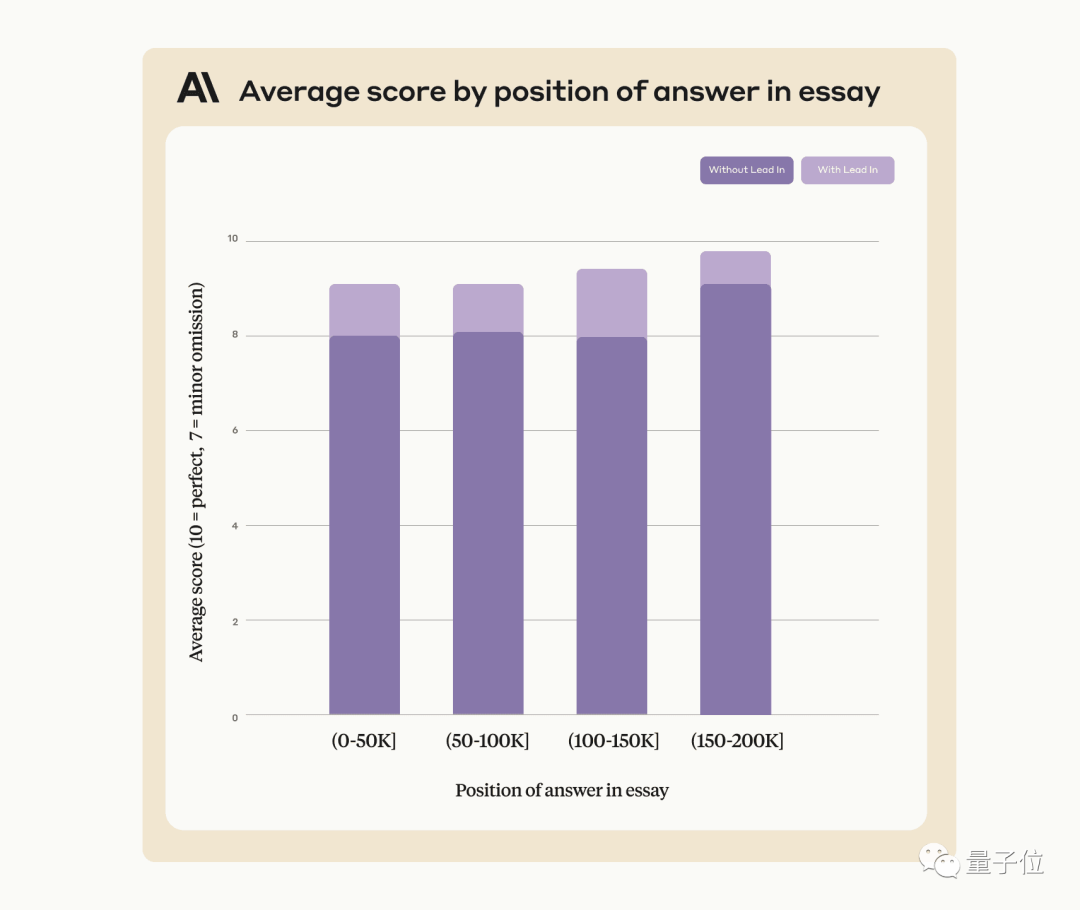
Anthropic公司表示將來會持續的繼續訓練Claude,讓它能更適應這類任務。
在使用API時,請AI以特定的開頭回答,並且還可以有其他巧妙的用途
馬特·舒默(Matt Shumer)這個創業家在閱讀該方案後給了一些小技巧的補充
如果想让AI输出纯JSON格式,提示词的最后以“{”结尾。同理,如果想让AI列出罗马数字,提示词以“I:”结尾就行。
不过事情还没完……
国内的大型公司也开始注意到这项测试,并开始尝试他们自己的大型模型是否能够通过
同样拥有超长上下文的月之暗面Kimi大模型团队也测出了问题,但给出了不同的解决方案,也取得了很好的成绩。

在不改变原义的情况下,需要重写的内容是:这样做的好处是,修改用户提问提示比要求AI在回答中添加一句更容易实现,尤其是在不调用API而直接使用聊天机器人产品的情况下
我使用了一种新方法来帮助测试GPT-4和Claude2.1的月球背面,结果显示GPT-4取得了显著的改善,而Claude2.1只有轻微的改善
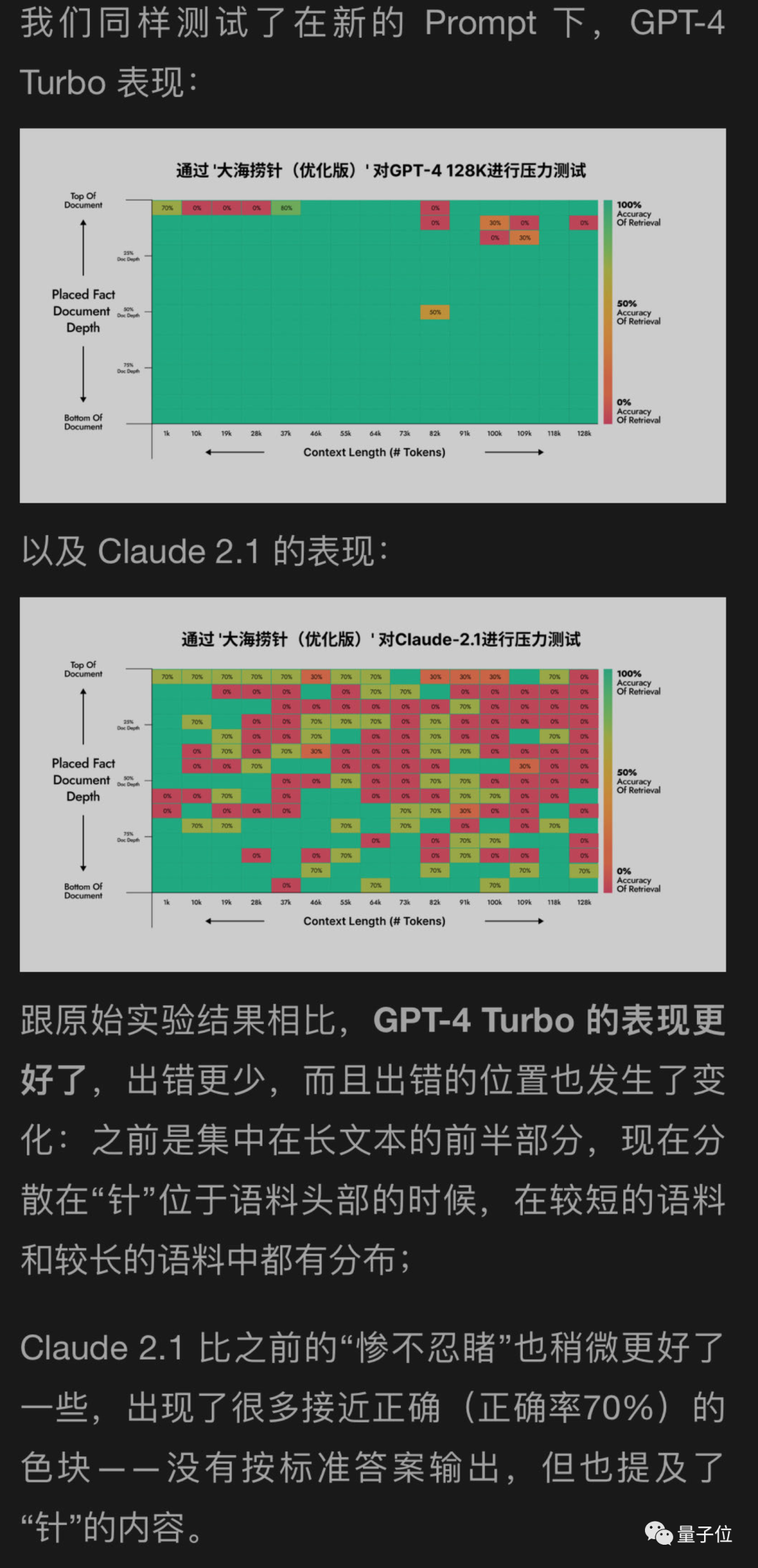
看来这个实验本身有一定局限性,Claude也是有自己的特殊性,可能与他们自己的对齐方式Constituional AI有关,需要用Anthropic自己提供的办法更好。
后来,月球背面的工程师继续进行了更多轮的实验,其中一个实验居然是……

糟糕,我变成测试数据了
以上是解鎖GPT-4與Claude2.1:一句話帶你實現100k+上下文大模型的真實力,將27分提升至98的詳細內容。更多資訊請關注PHP中文網其他相關文章!