



在CTR預估中,主流都採用特徵embedding MLP的方式,其中特徵非常關鍵。然而對於相同的特徵,在不同的樣本中,表徵是相同的,這種方式輸入到下游模型,會限制模型的表達能力。
為了解決這個問題,CTR預估領域提出了一系列相關工作,稱為特徵增強模組。特徵增強模組根據不同的樣本,對embedding層的輸出結果進行一次矯正,以適應不同樣本的特徵表示,提升模型的表達能力。
最近,復旦大學和微軟亞洲研究院合作發布了一篇關於特徵增強工作的綜述,對比了不同特徵增強模組的實現方法及其效果。現在,讓我們來介紹幾個特徵增強模組的實作方法,以及本文所進行的相關對比實驗
 論文標題:A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
論文標題:A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
下載網址:https://arxiv.org/pdf/2311.04625v1.pdf
1、特徵增強建模想法
特徵增強模組,旨在提升CTR預估模型中Embedding層的表達能力,實現相同特徵在不同樣本下的表徵差異化。特徵增強模組可以用下面這個統一公式表達,輸入原始的Embedding,經過一個函數後,產生這個樣本個性化的Embedding。
 圖片
圖片
這類方法的大致思路為,在得到初始的每個特徵的embedding後,使用樣本本身的表徵,對特徵embedding做一個變換,得到目前樣本的個人化embedding。以下為大家介紹一些經典的特徵增強模組建模方法。
2、特徵增強經典方法
An Input-aware Factorization Machine for Sparse Prediction(IJCAI 2019)這篇文章在embedding層之後增加了一個reweight層,將樣本初始embedding輸入到一個MLP中得到一個表徵樣本的向量,使用softmax進行歸一化。 Softmax後的每個元素對應一個特徵,代表這個特徵的重要程度,使用這個softmax結果和每個對應特徵的初始embedding相乘,實現樣本粒度的特徵embedding加權。
 圖片
圖片
FiBiNET: 結合特徵重要性和二階特徵互動的點擊率預測模型(RecSys 2019)也採用了類似的想法。該模型為每個樣本學習了一個特徵的個人化權重。整個過程分為擠壓(squeeze)、提取(extraction)和重新加權(reweight)三個步驟。在擠壓階段,透過池化方法將每個特徵的嵌入向量得到一個統計標量。在提取階段,將這些標量輸入到多層感知機(MLP)中,得到每個特徵的權重。最後,將這些權重與每個特徵的嵌入向量相乘,得到加權後的嵌入結果,相當於在樣本層級上進行特徵重要性的篩選
 圖片
圖片
#A Dual Input-aware Factorization Machine for CTR Prediction(IJCAI 2020)和上一篇文章類似,也是利用self-attention對特徵進行一層增強。整體分為vector-wise和bit-wise兩個模組。 Vector-wise將每個特徵的embedding當成序列中的一個元素,輸入到Transformer中得到融合後的特徵表示;bit-wise部分使用多層MLP對原始特徵進行對應。兩部分的輸入結果相加後,得到每個特徵元素的權重,乘到對應的原始特徵的每一位上,得到增強後的特徵。
 圖片
圖片
GateNet:增強門控深度網路用於點擊率預測(2020)利用每個特徵的初始嵌入向量透過一個MLP和sigmoid函數產生其獨立的特徵權重分數,同時使用MLP將所有特徵映射為按位的權重分數,將兩者結合起來對輸入特徵進行加權。除了特徵層外,在MLP的隱藏層中,也利用類似的方法對每個隱藏層的輸入進行加權
 圖片
圖片
Interpretable Click-Through Rate Prediction through Hierarchical Attention(WSDM 2020)也是利用self-attention實現特徵的轉換,但是增加了高階特徵的生成。這裡面使用層次self-attention,每一層的self-attention以上一層sefl-attention的輸出作為輸入,每一層增加了一階高階特徵組合,實現層次多層特徵提取。具體來說,每一層進行self-attention後,將生成的新特徵矩陣經過softmax得到每個特徵的權重,根據權重對原始特徵加權新的特徵,再和原始特徵進行一次點積,實現增加一階的特徵交叉。
 圖片
圖片
ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding(2021)也是類似的做法,使用一個MLP將所有特徵映射成一個每個特徵embedding尺寸的維度,對原始特徵做一個縮放,文中針對每個特徵使用了個性化的MLP參數。透過這種方式,利用樣本中的其他特徵作為上下位增強每個特徵。
 圖片
圖片
Enhancing CTR Prediction with Context-Aware Feature Representation Learning(SIGIR 2022)採用了self-attention進行特徵增強,對於一組輸入特徵,每個特徵對於其他特徵的影響程度是不同的,透過self-attention,對每個特徵的embedding進行一次self-attention,實現樣本內特徵間的資訊交互作用。除了特徵間的交互,文中也利用MLP進行bit層級的訊息交互。上述生成的新embedding,會透過一個gate網絡,和原始的embedding進行融合,得到最終refine後的特徵表示。
 圖片
圖片
3、實驗效果
#進行了各類別特徵增強方法的效果對比後,得出整體結論:在在眾多特徵增強模組中,GFRL、FRNet-V、FRNetB表現最優,且效果優於其他特徵增強方法
 ##圖片 #
##圖片 #
以上是一文總結特徵增強&個人化在CTR預估中的經典方法與效果對比的詳細內容。更多資訊請關注PHP中文網其他相關文章!

![WLAN扩展模块已停止[修复]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif) WLAN扩展模块已停止[修复]Feb 19, 2024 pm 02:18 PM
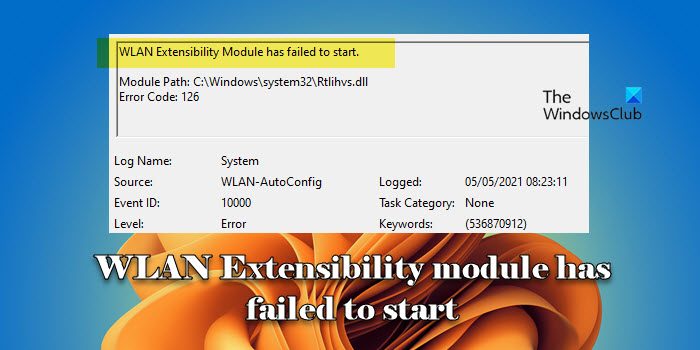
WLAN扩展模块已停止[修复]Feb 19, 2024 pm 02:18 PM如果您的Windows计算机上的WLAN扩展模块出现问题,可能会导致您与互联网断开连接。这种情况常常让人感到困扰,但幸运的是,本文提供了一些简单的建议,可以帮助您解决这个问题,让您的无线连接重新正常运行。修复WLAN扩展模块已停止如果您的Windows计算机上的WLAN可扩展性模块已停止工作,请按照以下建议进行修复:运行网络和Internet故障排除程序禁用并重新启用无线网络连接重新启动WLAN自动配置服务修改电源选项修改高级电源设置重新安装网络适配器驱动程序运行一些网络命令现在,让我们来详细看
 WLAN可扩展性模块无法启动Feb 19, 2024 pm 05:09 PM
WLAN可扩展性模块无法启动Feb 19, 2024 pm 05:09 PM本文详细介绍了解决事件ID10000的方法,该事件表明无线局域网扩展模块无法启动。在Windows11/10PC的事件日志中可能会显示此错误。WLAN可扩展性模块是Windows的一个组件,允许独立硬件供应商(IHV)和独立软件供应商(ISV)为用户提供定制的无线网络特性和功能。它通过增加Windows默认功能以扩展本机Windows网络组件的功能。在操作系统加载网络组件时,WLAN可扩展性模块作为初始化的一部分启动。如果无线局域网扩展模块遇到问题无法启动,您可能会在事件查看器的日志中看到错误消
 Python常用标准库及第三方库2-sys模块Apr 10, 2023 pm 02:56 PM
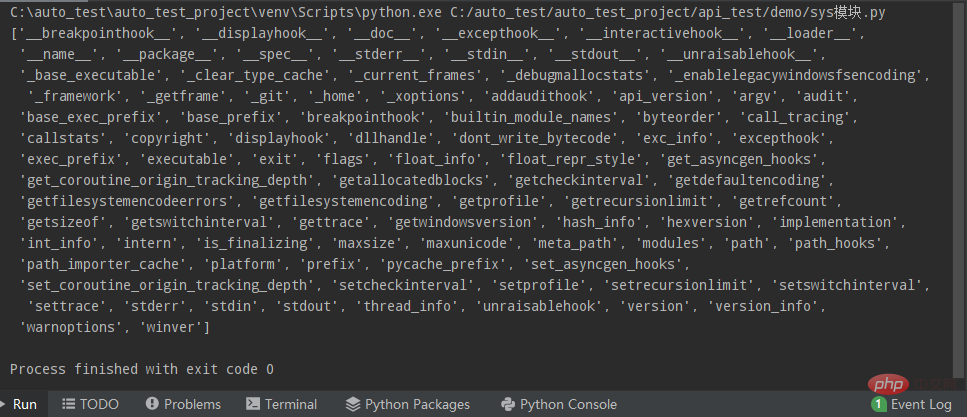
Python常用标准库及第三方库2-sys模块Apr 10, 2023 pm 02:56 PM一、sys模块简介前面介绍的os模块主要面向操作系统,而本篇的sys模块则主要针对的是Python解释器。sys模块是Python自带的模块,它是与Python解释器交互的一个接口。sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分。二、sys模块常用方法通过dir()方法可以查看sys模块中带有哪些方法:import sys print(dir(sys))1.sys.argv-获取命令行参数sys.argv作用是实现从程序外部向程序传递参数,它能够获取命令行参数列
 Python编程:详解命名元组(namedtuple)的使用要点Apr 11, 2023 pm 09:22 PM
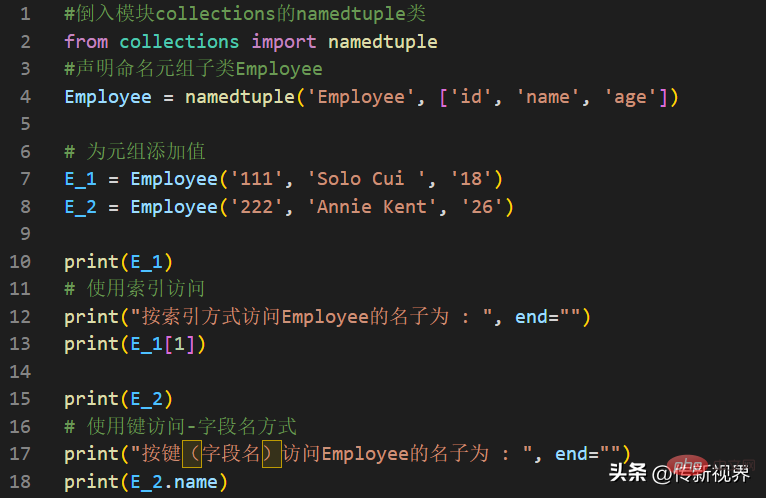
Python编程:详解命名元组(namedtuple)的使用要点Apr 11, 2023 pm 09:22 PM前言本文继续来介绍Python集合模块,这次主要简明扼要的介绍其内的命名元组,即namedtuple的使用。闲话少叙,我们开始——记得点赞、关注和转发哦~ ^_^创建命名元组Python集合中的命名元组类namedTuples为元组中的每个位置赋予意义,并增强代码的可读性和描述性。它们可以在任何使用常规元组的地方使用,且增加了通过名称而不是位置索引方式访问字段的能力。其来自Python内置模块collections。其使用的常规语法方式为:import collections XxNamedT
 如何在 Python 中使用 DateTimeApr 19, 2023 pm 11:55 PM
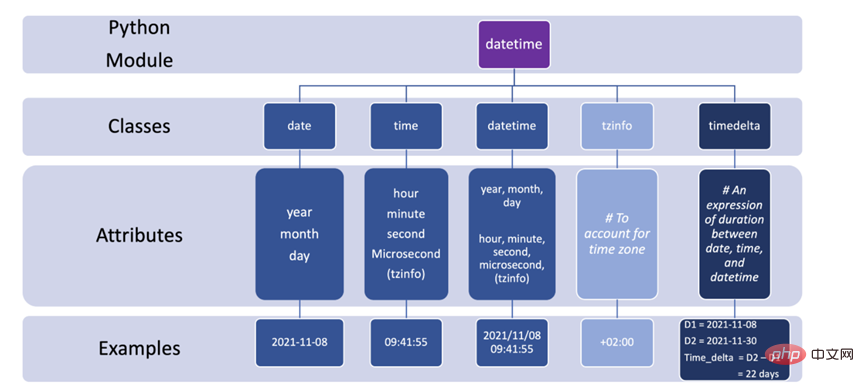
如何在 Python 中使用 DateTimeApr 19, 2023 pm 11:55 PM所有数据在开始时都会自动分配一个“DOB”(出生日期)。因此,在某些时候处理数据时不可避免地会遇到日期和时间数据。本教程将带您了解Python中的datetime模块以及使用一些外围库,如pandas和pytz。在Python中,任何与日期和时间有关的事情都由datetime模块处理,它将模块进一步分为5个不同的类。类只是与对象相对应的数据类型。下图总结了Python中的5个日期时间类以及常用的属性和示例。3个有用的片段1.将字符串转换为日期时间格式,也许是使用datet
 Python 的 import 是怎么工作的?May 15, 2023 pm 08:13 PM
Python 的 import 是怎么工作的?May 15, 2023 pm 08:13 PM你好,我是somenzz,可以叫我征哥。Python的import是非常直观的,但即使这样,有时候你会发现,明明包就在那里,我们仍会遇到ModuleNotFoundError,明明相对路径非常正确,就是报错ImportError:attemptedrelativeimportwithnoknownparentpackage导入同一个目录的模块和不同的目录的模块是完全不同的,本文通过分析使用import经常遇到的一些问题,来帮助你轻松搞定import,据此,你可以轻松创建属
 Ansible工作原理详解Feb 18, 2024 pm 05:40 PM
Ansible工作原理详解Feb 18, 2024 pm 05:40 PMAnsible工作原理从上面的图上可以了解到:管理端支持local、ssh、zeromq三种方式连接被管理端,默认使用基于ssh的连接,这部分对应上面架构图中的连接模块;可以按应用类型等方式进行HostInventory(主机清单)分类,管理节点通过各类模块实现相应的操作,单个模块,单条命令的批量执行,我们可以称之为ad-hoc;管理节点可以通过playbooks实现多个task的集合实现一类功能,如web服务的安装部署、数据库服务器的批量备份等。playbooks我们可以简单的理解为,系统通过
 一文总结特征增强&个性化在CTR预估中的经典方法和效果对比Dec 15, 2023 am 09:23 AM
一文总结特征增强&个性化在CTR预估中的经典方法和效果对比Dec 15, 2023 am 09:23 AM在CTR预估中,主流都采用特征embedding+MLP的方式,其中特征非常关键。然而对于相同的特征,在不同的样本中,表征是相同的,这种方式输入到下游模型,会限制模型的表达能力。为了解决这个问题,CTR预估领域提出了一系列相关工作,被称为特征增强模块。特征增强模块根据不同的样本,对embedding层的输出结果进行一次矫正,以适应不同样本的特征表示,提升模型的表达能力。最近,复旦大学和微软亚洲研究院合作发布了一篇关于特征增强工作的综述,对比了不同特征增强模块的实现方法及其效果。现在,我们来介绍一


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

禪工作室 13.0.1
強大的PHP整合開發環境

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

