
Meta 推出 AI 音訊模型 Audiobox,支援語音及文字同時輸入

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-12-04 17:25:561474瀏覽
Meta最近推出了一款名為Audiobox的AI聲音產生模型。這個模型可以同時接收語音和文字輸入,使用者可以透過語音和文字描述來產生所需的音訊
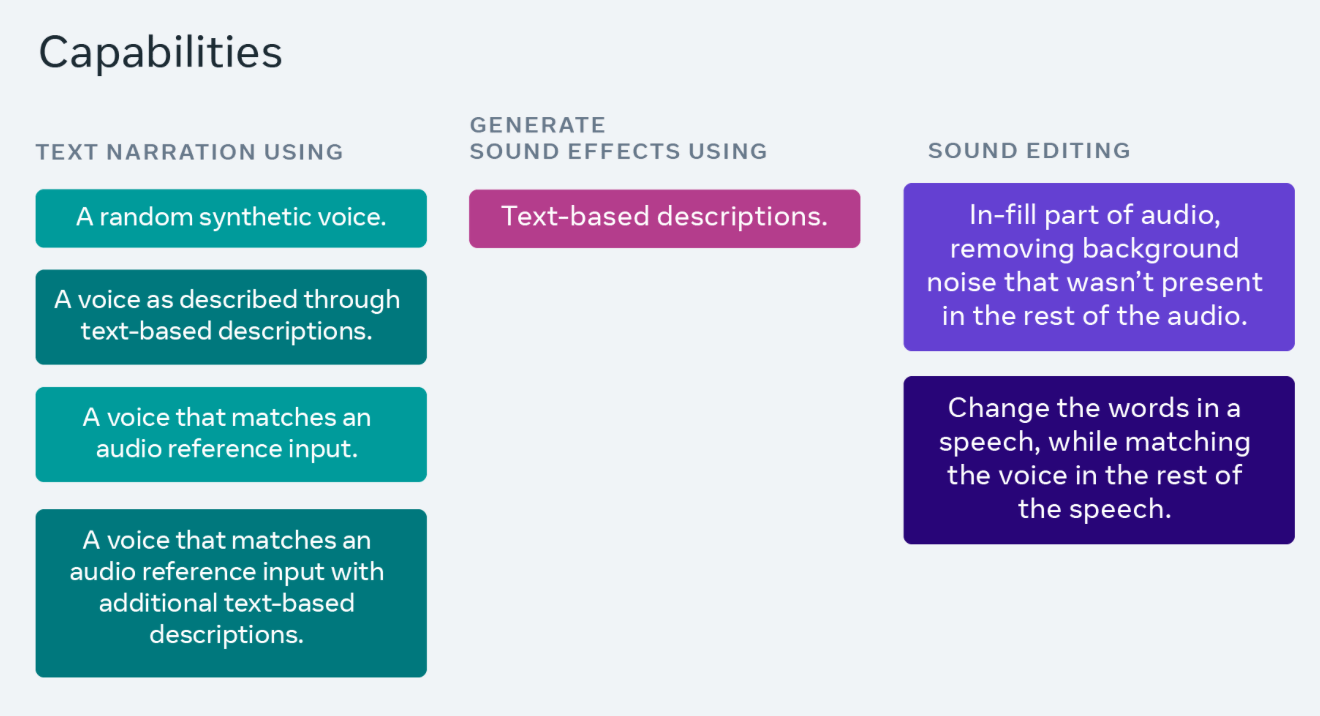
據悉,這款模型基於Meta 今年6 月推出的Voicebox AI 模型,據稱Audiobox 能產生各種環境音、自然對話語音,並整合了音訊生成和編輯能力,以便於用戶自由生成自己所需的音頻。
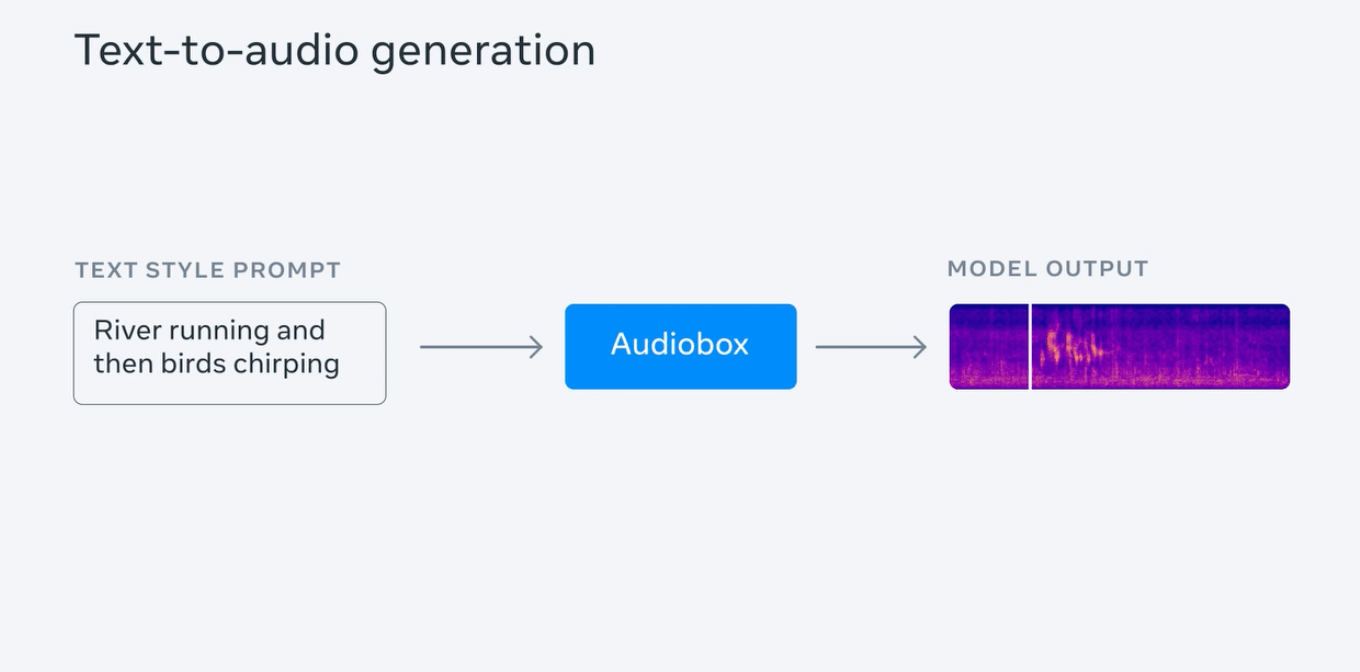
Meta 介紹稱,生成高品質音頻需要有大量音頻庫及深厚的領域知識,但大眾難以獲得這些資源,而該公司推出這個模型旨在降低聲音生成門檻,讓任何人都更容易製作視頻、遊戲等應用場景的音效。
IT之家發現,這款Audiobox 模型基於Voicebox 的「引導聲音」機制,以便於生成目標音頻,並配合「流量比對(flow-matching)」擴散模型生成方法,以實現「聲音填充( audio infilling)」功能,從而產生多層次的音訊。
Meta 測試產生帶有雷暴聲的下雨音頻,並輸入一系列提示句進行演示,例如“流水聲伴隨鳥鳴”、“以高音調快節奏說話的年輕女性”等;同時測試了同時輸入人聲及文字提示,以產生帶有情緒(「哀痛而緩慢」)並擁有背景音(身處教堂)的語音。
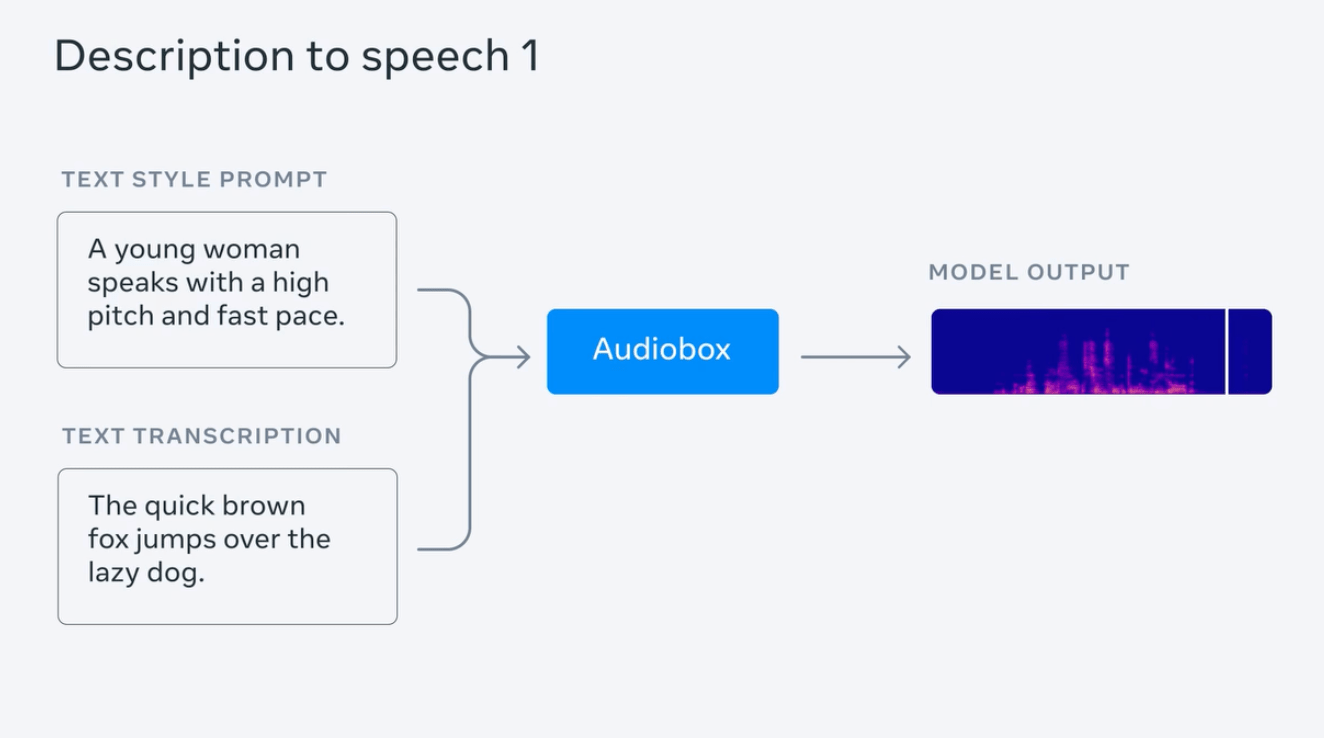
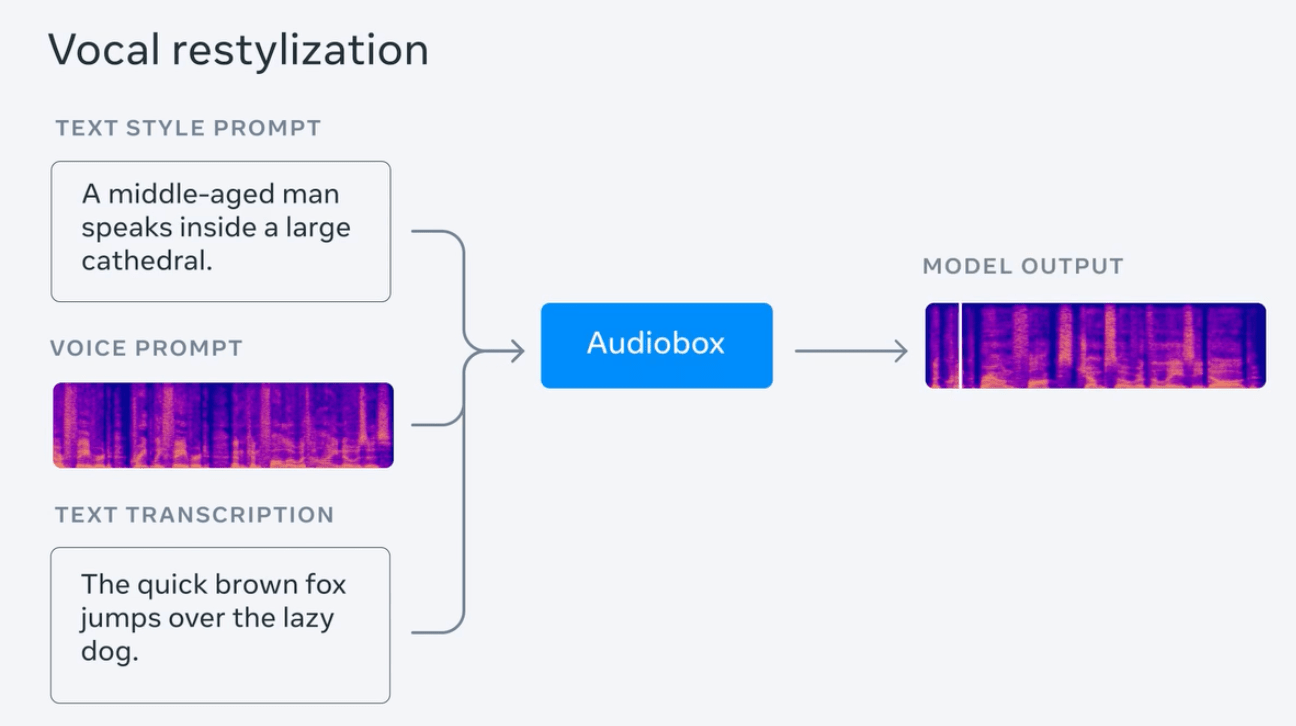
Meta 聲稱,Audiobox 在音質及「生成內容的準確度」 順利擊敗了 AudioLDM2、VoiceLDM 及 TANGO,超越了現有最佳的音頻生成模型。
目前 Audiobox 已經開放向特定研究人員及學術界試用,以供測試模型品質及安全性,Meta 聲稱,他們計劃「再過幾週將社會全面公開該模型」。
以上是Meta 推出 AI 音訊模型 Audiobox,支援語音及文字同時輸入的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:sohu.com。如有侵權,請聯絡admin@php.cn刪除