一張照片生成視頻,張嘴、點頭、喜怒哀樂,都可以打字控制

- 王林轉載
- 2023-12-03 11:17:21821瀏覽
最近,微軟進行的一項研究揭示了視訊處理軟體PS的靈活程度有多高
在這項研究中,你只要給AI 一張照片,它就能產生照片中人物的視頻,而且人物的表情、動作都是可以透過文字進行控制的。例如,如果你給的指令是「張嘴」,影片中的人物就會真的張開嘴。

如果你給的指示是「傷心」,她就會做出傷心的表情和頭部動作。
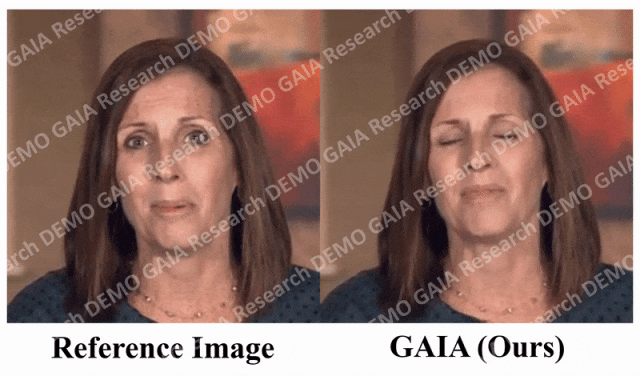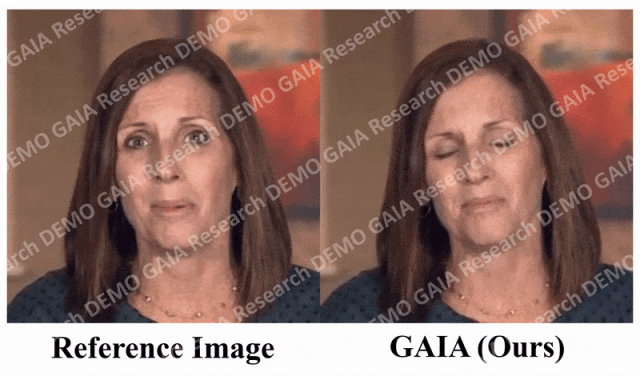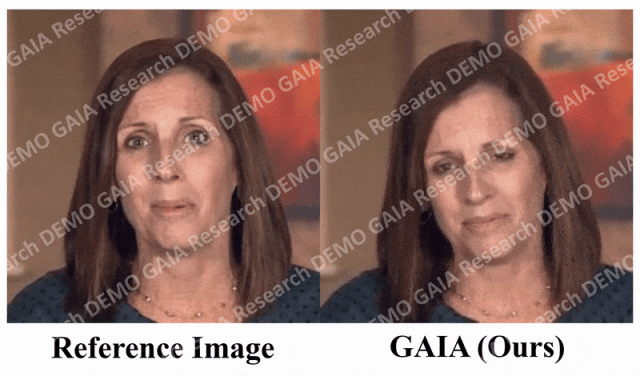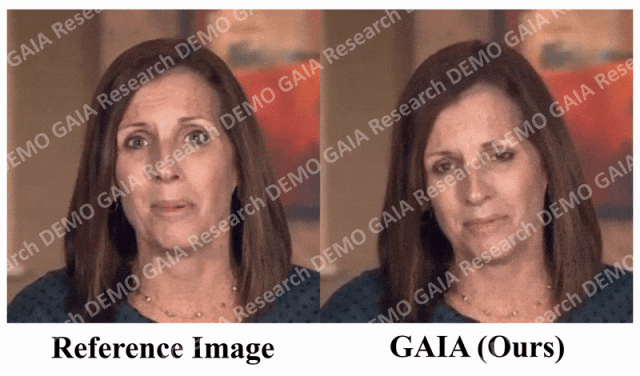
當給出指令「驚訝」,虛擬人物的抬頭紋都擠在一起了。

除此之外,您還可以提供一段語音,讓虛擬角色的嘴型和動作與語音同步。或者,您可以提供一段真人影片供虛擬角色模仿
如果你對虛擬人物的動作有更多的自訂編輯需求,例如讓他們點頭、轉頭或歪頭,這項技術也是支援的

這項研究名叫GAIA(Generative AI for Avatar,用於虛擬形象的生成式AI),其demo 已經開始在社群媒體上傳播。不少人對其效果表示讚嘆,並希望用它來「復活」逝者。
但也有人擔心,這些技巧的持續演化會讓網路影片變得更加真假難辨,或是被不法分子用於詐騙。看來,反詐手法要繼續升級了。
GAIA 有什麼創新點?
零樣本會說話的虛擬人物生成技術旨在根據語音合成自然視頻,確保生成的嘴型、表情和頭部姿勢與語音內容一致。過去的研究通常需要針對每個虛擬人物進行特定訓練或調整特定模型,或在推理過程中利用模板影片以實現高品質的結果。最近,研究人員致力於設計和改進零樣本會說話的虛擬人物的生成方法,只需使用一張目標虛擬人物的肖像圖片作為外貌參考即可。不過,這些方法通常採用基於warping的運動表示、3D Morphable Model(3DMM)等領域先驗來降低任務難度。這類啟發式方法雖然有效,但可能會限制多樣性,導致不自然的結果。因此,從資料分佈直接學習是未來研究的重點
本文中,來自微軟的研究者提出了GAIA(Generative AI for Avatar),其能夠從語音和單張肖像圖片合成自然的會說話的虛擬人物視頻,在生成過程中消除了領域先驗。

專案位址:https://microsoft.github.io/GAIA/可以在此連結上找到相關專案的詳細資訊
論文連結: https://arxiv.org/pdf/2311.15230.pdf
蓋亞揭示了兩個關鍵洞見:
-
用語音來驅動虛擬人物運動,而虛擬人物的背景和外觀(appearance)在整個影片中保持不變。受此啟發,本文將每一幀的運動和外觀分開,其中外觀在幀之間共享,而運動對每一幀都是唯一的。為了根據語音預測運動,本文將運動序列編碼為運動潛在序列,並使用以輸入語音為條件的擴散模型來預測潛在序列;
- 當一個人在說出給定的內容時,表情和頭部姿態存在巨大的多樣性,這需要一個大規模和多樣化的數據集。因此,該研究收集了一個高品質的能說話的虛擬人物資料集,該資料集由 16K 個不同年齡、性別、皮膚類型和說話風格的獨特說話者組成,使生成結果自然且多樣化。
根據上述兩個洞見,本文提出了GAIA 框架,其由變分自編碼器(VAE)(橘色模組)和擴散模型(藍色和綠色模組)組成。
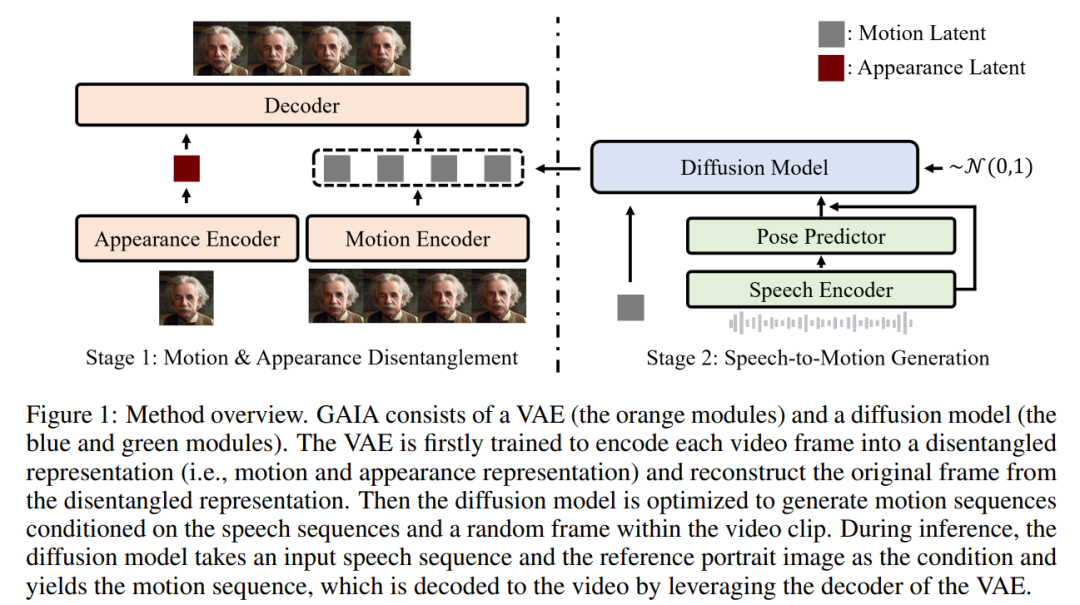
VAE的主要功能是分解運動和外觀。它由兩個編碼器(運動編碼器和外觀編碼器)和一個解碼器組成。在訓練時,運動編碼器的輸入為面部關鍵點(landmarks)的當前幀,而外貌編碼器的輸入為當前視頻剪輯中的隨機採樣幀
根據這兩個編碼器的輸出,隨後最佳化解碼器以重建目前幀。一旦獲得訓練完成的VAE,就會得到所有訓練資料的潛在動作(即運動編碼器的輸出)
然後,這篇文章使用擴散模型訓練,以預測基於語音和影片剪輯中隨機取樣影格的運動潛在序列,從而為生成過程提供外貌資訊
#在推理過程中,給定目標虛擬人物的參考肖像影像,擴散模型將影像和輸入語音序列作為條件,產生符合語音內容的運動潛在序列。然後,產生的運動潛在序列和參考肖像圖像經過 VAE 解碼器合成說話視訊輸出。
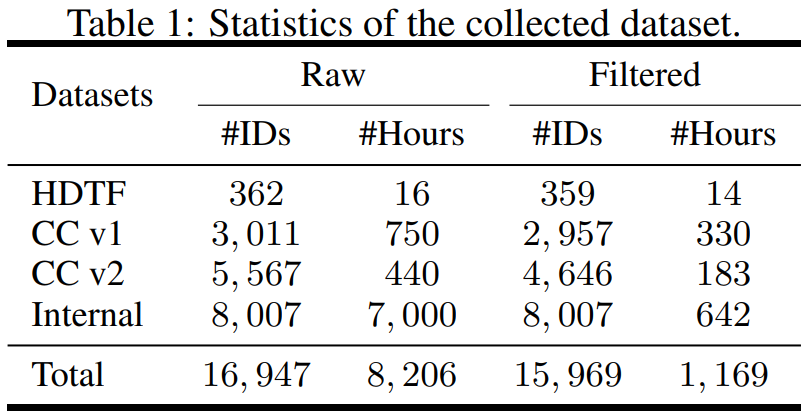
該研究在資料方面進行了構建,從不同的來源收集了資料集,包括 High-Definition Talking Face Dataset (HDTF) 和 Casual Conversation datasets v1&v2 (CC v1&v2)。除了這三個資料集之外,研究還收集了一個大規模的內部說話虛擬人物資料集,其中包含 7K 小時的影片和 8K 說話者 ID。資料集的統計概述如表1 所示
為了學習到所需的信息,文章提出了幾種自動過濾策略以確保訓練資料的品質:
- 為了讓嘴唇移動可見,頭像的正面方向應朝向相機;
- 為了確保穩定性,影片中的臉部動作要流暢,不能出現快速晃動;
- 為了過濾嘴唇動作和言語不一致的極端情況,應該刪除頭像戴口罩或保持沉默的畫面。
本文在過濾後的資料上訓練 VAE 和擴散模型。從實驗結果來看,本文得到了三個關鍵結論:
- GAIA 能夠進行零樣本說話虛擬人物生成,在自然度、多樣性、口型同步質量和視覺品質方面具有優越的性能。根據研究者的主觀評價,GAIA 顯著超越了所有基線方法;
- #訓練模型的大小從150M 到2B 不等,結果表明,GAIA 具有可擴展性,因為較大型的模型會產生更好的結果;
- GAIA 是一個通用且靈活的框架,可實現不同的應用,包括可控的說話虛擬人物生成和文字- 指令虛擬人物生成。
GAIA 效果怎麼樣?
實驗過程中,研究將 GAIA 與三個強大的基準進行比較,包括 FOMM、HeadGAN 和 Face-vid2vid。結果如表 2 所示:GAIA 中的 VAE 比先前的視訊驅動基準實現了持續的改進,這說明 GAIA 成功地分解了外觀和運動表示。
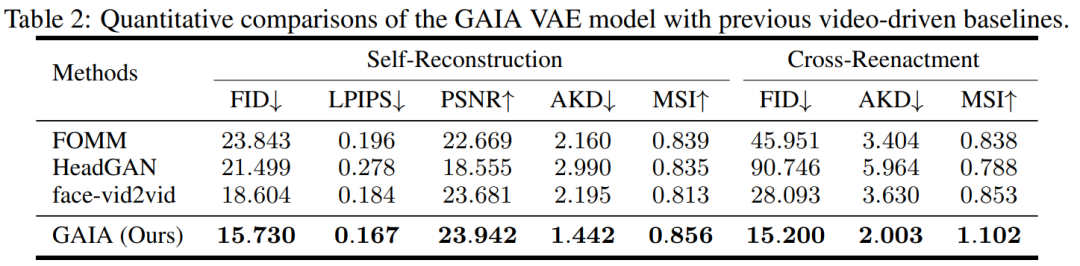
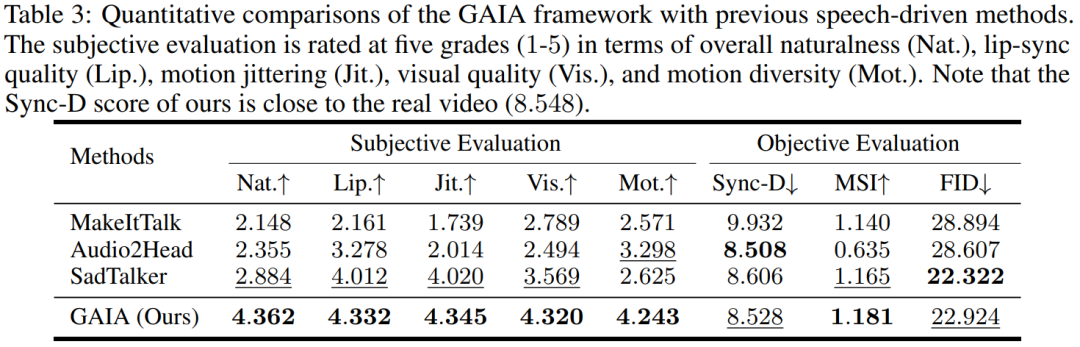
語音驅動結果。用語音驅動說話虛擬人物生成是透過從語音預測運動實現的。表 3 和圖 2 提供了 GAIA 與 MakeItTalk、Audio2Head 和 SadTalker 方法的定量和定性比較。
從數據中可以清楚地看出,GAIA 在主觀評估方面遠遠超過了所有基準方法。更具體地說,如圖2 所示,即使參考影像是閉眼或頭部姿態不尋常,基準方法的生成結果通常高度依賴於參考影像;相較之下,GAIA 對各種參考影像都表現出穩健性,並產生具有更高自然度、口型高度同步、視覺品質更好以及運動多樣性的結果

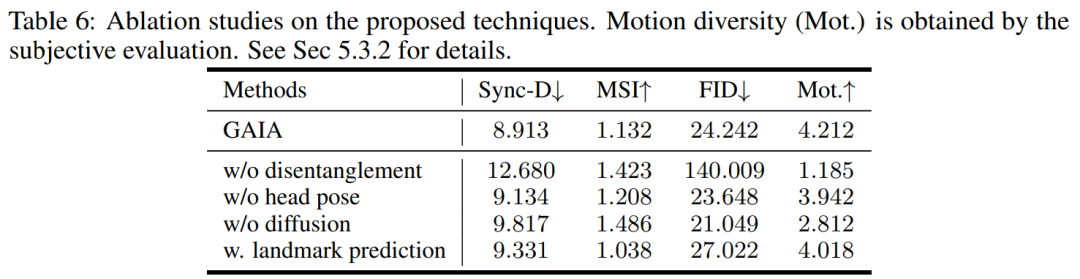
根據表3,最佳的MSI分數顯示GAIA產生的影片具有優異的運動穩定性。 Sync-D得分為8.528,接近真實影片得分(8.548),顯示產生的影片具有出色的唇形同步性。該研究獲得了與基線相當的FID分數,這可能是受到了不同頭部姿態的影響,因為該研究發現未經擴散訓練的模型在表中實現了更好的FID分數,詳見表6
以上是一張照片生成視頻,張嘴、點頭、喜怒哀樂,都可以打字控制的詳細內容。更多資訊請關注PHP中文網其他相關文章!