



今天,我想和大家分享一下機器學習中常見的無監督學習聚類方法
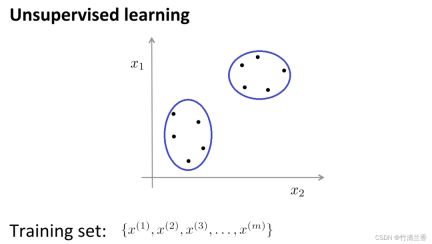
在無監督學習中,我們的數據並不帶有任何標籤,因此在無監督學習中要做的就是將這一系列無標籤的數據輸入到演算法中,然後讓演算法找到一些隱含在數據中的結構,透過下圖中的數據,可以找到的一個結構就是數據集中的點可以分成兩組分開的點集(簇),能夠圈出這些簇(cluster)的演算法,就叫做聚類演算法(clustering algorithm)。
聚類演算法的應用
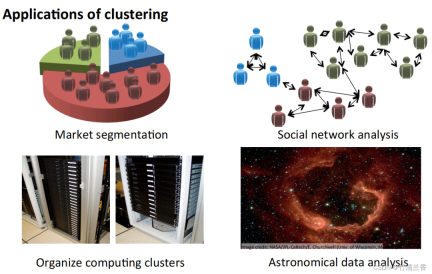
- 市場分割:將資料庫中客戶的資訊根據市場進行不同的分組,從而實現對其分別銷售或根據不同的市場進行服務改進。
- 社群網路分析:透過郵件最常聯絡的人及其最常聯絡的人來找出一個緊密的群體。
- 組織電腦集群:在資料中心裡,電腦集群經常一起協同工作,可以用它來重新組織資源、重新佈局網路、優化資料中心以及通訊資料。
- 了解銀河系的組成:利用這些資訊來了解一些天文學的知識。
聚類分析的目標是將觀測值分成組別(「簇」),以便分配到同一簇的觀測值之間的成對差異往往小於不同簇中的觀測值之間的差異。聚類演算法分為三種不同的類型:組合演算法、混合建模和模式搜尋。
常見的幾種聚類演算法有:
- #K-Means Clustering
- Hierarchical Clustering
- #Agglomerative Clustering
- Affinity Propagation
Mean Shift Clustering
Bisecting K-MeansDBSCAN
OPTICS BIRCH
K-means
K-means 演算法是目前最受歡迎的聚類方法之一。 K-means 是由貝爾實驗室的 Stuart Lloyd 在 1957 年提出來的,最開始是用於脈衝編碼調製,直到 1982 年才將演算法對外公佈。 1965 年,Edward W.Forgy 發布了相同的演算法,因此 K-Means 有時被稱為 Lloyd-Forgy。
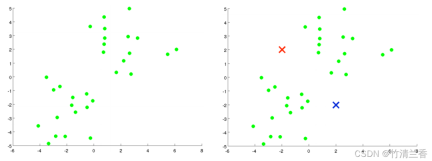
直觀理解K 均值演算法:
- 假如有一個無標籤的資料集(上圖左),並且我們想要將其分成兩個簇,現在執行K 均值演算法,具體操作如下:
第一步,隨機產生兩個點(因為想要將資料聚集成兩個類別)(上圖右),這兩個點叫做聚類中心(cluster centroids)。
第二步,進行 K 均值演算法的內循環。 K 均值演算法是一個迭代演算法,它會做兩件事情,第一個是簇分配(cluster assignment),第二個是行動聚類中心(move centroid)。
內循環的第一步是要進行簇分配,也就是說,遍歷每一個樣本,再根據每一個點到聚類中心距離的遠近將其分配給不同的聚類中心(離誰近分配給誰),對於本例而言,就是遍歷資料集,將每個點染成紅色或藍色。 
K-Means演算法的優點:
#簡單易懂,計算速度較快,適用於大規模資料集。
缺點:
- #例如對於非球形簇的處理能力較差,容易受到初始簇心的選擇影響,需要預先指定簇的數量K等。
- 此外,當資料點之間存在雜訊或離群點時,K-Means演算法可能會將它們指派到錯誤的簇中。
Hierarchical Clustering
層次聚類是依照某個層次對樣本集進行聚類的運算。這裡的層次指的實際上是某種距離的定義
聚類的最終目的是減少分類的數量,因此在行為上類似於從葉子節點逐步靠近的樹狀圖過程,這種行為也被稱為「自下而上」
更通俗的,層次聚類是將初始化的多個類別簇看做樹節點,每一步迭代,都是將兩兩相近的類簇合併成一個新的大類簇,如此反复,直至最終只剩下一個類簇(根節點)。
層次聚類策略分為兩種基本範式:聚集型(自下而上)和分裂型(自上而下)。
與層次聚類相反的是分裂聚類,也稱為DIANA(Divise Analysis),其行為過程為「自上而下」
K-means演算法的結果取決於選擇搜尋的聚類數量和起始配置的分配。而相反,層次聚類方法則不需要這樣的規範。相反,它們要求使用者根據兩組觀察值之間的配對差異性來指定(不相交)觀察組之間的差異性測量。顧名思義,層次聚類方法產生一個層次結構表示,其中每個層次的群集都是透過合併下一個較低層次的群集而創建的。在最低級別,每個集群包含一個觀察值。在最高級別,只有一個叢集包含所有的資料
優點:
- 距離和規則的相似度容易定義,限制少;
- 不需要預先制定聚類數;
- 可以發現類別的層次關係;
- 可以聚類成其它形狀。
缺點:
- #計算複雜度太高;
##奇異值也能產生很大影響;演算法很可能會聚類成鏈狀。
- Agglomerative Clustering
- 重寫後的內容為:凝聚層次聚類(Agglomerative Clustering)是一種自底向上的聚類演算法,它將每個資料點看作一個初始簇,並逐步合併它們以形成更大的簇,直到滿足停止條件。在這個演算法中,每個資料點最初被視為一個單獨的簇,然後逐步合併簇,直到所有資料點合併為一個大簇 ##優點:
適用於不同形狀和大小的簇,且不需要事先指定聚類數目。
- 此演算法也可以輸出聚類層次結構,以便於分析和視覺化。
- 缺點:
#計算複雜度較高,尤其是在處理大規模資料集時,需要消耗大量的運算資源和儲存空間。
此演算法對初始簇的選擇也較為敏感,可能會導致不同的聚類結果。 ############Affinity Propagation#########修改後的內容:親和傳播演算法(AP)通常被翻譯為親和力傳播演算法或鄰近傳播演算法##### ########Affinity Propagation 是一種基於圖論的聚類演算法,旨在識別資料中的"exemplars"(代表點)和"clusters"(簇)。與 K-Means 等傳統聚類演算法不同,Affinity Propagation 不需要事先指定聚類數目,也不需要隨機初始化簇心,而是透過計算資料點之間的相似性得出最終的聚類結果。 ######
優點:
- 不需要製定最終聚類族的數量
- 已有的資料點作為最終的聚類中心,而不是新產生一個簇中心。
- 模型對資料的初始值不敏感。
- 對初始相似度矩陣資料的對稱性沒有要求。
- 比較與 k-centers 聚類方法,其結果的平方差誤差較小。
缺點:
- #該演算法的計算複雜度較高,需要大量的儲存空間和運算資源;
- 對於雜訊點和離群點的處理能力較弱。
Mean Shift Clustering
平移聚類是一種基於密度的非參數聚類演算法,其基本思想是透過尋找資料點密度最大的位置(稱為“局部最大值”或“高峰”),來識別資料中的群集。此演算法的核心在於對每個資料點進行局部密度估計,並將密度估計結果用於計算資料點移動的方向和距離
優點:
- 不需要指定簇的數目,而且對於形狀複雜的簇也有很好的效果。
- 演算法也能夠有效地處理雜訊資料。
缺點:
- #計算複雜度較高,尤其是在處理大規模資料集時,需要消耗大量的運算資源和儲存空間;
- 此演算法也對初始參數的選擇較為敏感,需要進行參數調整與最佳化。
Bisecting K-Means
Bisecting K-Means 是基於K-Means 演算法的層次聚類演算法,其基本思想是將所有數據點分成一個簇,然後將該簇分成兩個子簇,並對每個子簇分別應用K-Means 演算法,重複執行這個過程,直到達到預定的聚類數目為止。
演算法首先將所有資料點視為初始簇,然後對該簇應用K-Means演算法,將該簇分成兩個子簇,併計算每個子簇的誤差平方和(SSE)。然後,選擇誤差平方和最大的子簇,並將其再次分成兩個子簇,重複執行這個過程,直到達到預定的聚類數目為止。
優點:
- #具有較高的準確度和穩定性,能夠有效地處理大規模資料集,且不需要指定初始聚類數目。
- 此演算法也能夠輸出聚類層次結構,以便於分析和視覺化。
缺點:
- #計算複雜度較高,尤其是在處理大規模資料集時,需要消耗大量的運算資源和儲存空間。
- 此外演算法對初始簇的選擇也比較敏感,可能會導致不同的聚類結果。
DBSCAN
基於密度的空間聚類演算法DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一種典型的具有雜訊的聚類別方法
密度的方法具有不依賴距離的特點,而是依賴密度。因此,它能夠克服基於距離的演算法只能發現「球形」聚集的缺點
DBSCAN演算法的核心思想是:對於一個給定的數據點,如果它的密度達到一定的閾值,則它屬於一個簇中;否則,它被視為雜訊點。
優點:
- 這類演算法能克服基於距離的演算法只能發現「類別圓形」(凸)的聚類的缺點;
- 可發現任意形狀的聚類,且對雜訊資料不敏感;
- 不需要指定類別的數目cluster;
- 演算法中只有兩個參數,掃描半徑(eps)和最小包含點數(min_samples)。
缺點:
- #計算複雜度,不進行任何最佳化時,演算法的時間複雜度是O(N^{2}),通常可利用R-tree,k-d tree, ball;
- tree索引來加速計算,將演算法的時間複雜度降為O(Nlog(N));
- 受eps影響較大。在類別中的資料分佈密度不均勻時,eps較小時,密度小的cluster會被劃分成多個性質相似的cluster;eps較大時,會使得距離較近且密度較大的cluster被合併成一個cluster。在高維度資料時,因為維數災難問題,eps的選取比較困難;
- #依賴距離公式的選取,由於維度災害,距離的量測標準不重要;
- 不適合資料集集中密度差異很大的,因為eps和metric選取很困難。
OPTICS
OPTICS(Ordering Points To Identify the Clustering Structure)是一種基於密度的聚類演算法,它能夠自動確定簇的數量,同時也能夠發現任意形狀的簇,並且能夠處理雜訊資料
OPTICS 演算法的核心思想是根據給定資料點計算其與其他點之間的距離,以確定其在密度上的可及性,並建立一個基於密度的距離圖。然後,透過掃描該距離圖,自動確定簇的數量,並對每個簇進行分割
# 優點:
- 能夠自動確定簇的數量,並且能夠處理任意形狀的簇,並且能夠有效地處理雜訊資料。
- 此演算法也能夠輸出聚類層次結構,以便於分析和視覺化。
缺點:
- #計算複雜度較高,尤其是在處理大規模資料集時,需要消耗大量的運算資源和儲存空間。
- 此演算法對於密度差異較大的資料集,可能會導致聚類效果不佳。
BIRCH
BIRCH(平衡迭代降低和層次聚類)是一種基於層次聚類的聚類演算法,它能夠高效地處理大規模資料集,並且對於任何形狀的簇都能夠取得良好的效果
BIRCH演算法的核心思想是:透過對資料集進行分層聚類,逐步減小資料規模,最終得到簇結構。 BIRCH演算法採用類似B樹的結構,稱為CF樹,它可以快速地插入和刪除子簇,並且可以自動平衡,從而確保簇的質量和效率
優點:
- 能夠快速處理大規模資料集,並且對於任意形狀的簇都有較好的效果。
- 此演算法對於雜訊資料和離群點也有較好的容錯性。
缺點:
- #對於密度差異較大的資料集,可能會導致聚類效果不佳;
- 對於高維度資料集的效果也不如其他演算法。
以上是九種聚類演算法,探索無監督機器學習的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 商業領袖生成引擎優化指南(GEO)May 03, 2025 am 11:14 AM
商業領袖生成引擎優化指南(GEO)May 03, 2025 am 11:14 AMGoogle正在領導這一轉變。它的“ AI概述”功能已經為10億用戶提供服務,在任何人單擊鏈接之前提供完整的答案。 [^2] 其他球員也正在迅速獲得地面。 Chatgpt,Microsoft Copilot和PE
 該初創公司正在使用AI代理來與惡意廣告和模仿帳戶進行戰鬥May 03, 2025 am 11:13 AM
該初創公司正在使用AI代理來與惡意廣告和模仿帳戶進行戰鬥May 03, 2025 am 11:13 AM2022年,他創立了社會工程防禦初創公司Doppel,以此做到這一點。隨著網絡犯罪分子越來越高級的AI模型來渦輪增壓,Doppel的AI系統幫助企業對其進行了大規模的對抗 - 更快,更快,
 世界模型如何從根本上重塑生成AI和LLM的未來May 03, 2025 am 11:12 AM
世界模型如何從根本上重塑生成AI和LLM的未來May 03, 2025 am 11:12 AM瞧,通過與合適的世界模型進行交互,可以實質上提高生成的AI和LLM。 讓我們來談談。 對創新AI突破的這種分析是我正在進行的《福布斯》列的最新覆蓋範圍的一部分,包括
 2050年五月:我們要慶祝什麼?May 03, 2025 am 11:11 AM
2050年五月:我們要慶祝什麼?May 03, 2025 am 11:11 AM勞動節2050年。全國范圍內的公園充滿了享受傳統燒烤的家庭,而懷舊遊行則穿過城市街道。然而,慶祝活動現在具有像博物館般的品質 - 歷史重演而不是紀念C
 您從未聽說過的DeepFake探測器準確是98%May 03, 2025 am 11:10 AM
您從未聽說過的DeepFake探測器準確是98%May 03, 2025 am 11:10 AM為了幫助解決這一緊急且令人不安的趨勢,在2025年2月的TEM期刊上進行了同行評審的文章,提供了有關該技術深擊目前面對的最清晰,數據驅動的評估之一。 研究員
 量子人才戰爭:隱藏的危機威脅技術的下一個邊界May 03, 2025 am 11:09 AM
量子人才戰爭:隱藏的危機威脅技術的下一個邊界May 03, 2025 am 11:09 AM從大大減少制定新藥所需的時間到創造更綠色的能源,企業將有巨大的機會打破新的地面。 不過,有一個很大的問題:嚴重缺乏技能的人
 原型:這些細菌可以產生電力May 03, 2025 am 11:08 AM
原型:這些細菌可以產生電力May 03, 2025 am 11:08 AM幾年前,科學家發現某些類型的細菌似乎通過發電而不是吸收氧氣而呼吸,但是它們是如何做到的,這是一個謎。一項發表在“雜誌”雜誌上的新研究確定了這種情況的發生方式:Microb
 AI和網絡安全:新政府的100天估算May 03, 2025 am 11:07 AM
AI和網絡安全:新政府的100天估算May 03, 2025 am 11:07 AM在本週的RSAC 2025會議上,Snyk舉辦了一個及時的小組,標題為“前100天:AI,政策和網絡安全如何碰撞”,其中包括全明星陣容:前CISA董事Jen Easterly;妮可·珀洛斯(Nicole Perlroth),前記者和帕特納(Partne)


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3漢化版
中文版,非常好用

記事本++7.3.1
好用且免費的程式碼編輯器

Dreamweaver Mac版
視覺化網頁開發工具

