



大型语言模型(llm)已经彻底改变了自然语言处理领域。随着这些模型在规模和复杂性上的增长,推理的计算需求也显著增加。为了应对这一挑战利用多个gpu变得至关重要。

因此,这篇文章将在多个GPU上同时进行推理,内容主要包括:介绍Accelerate库、简单的方法和工作代码示例,以及使用多个GPU进行性能基准测试
本文将使用多个3090将llama2-7b的推理扩展在多个GPU上
基本示例
我们首先介绍一个简单的示例来演示使用Accelerate进行多gpu“消息传递”。
from accelerate import Accelerator from accelerate.utils import gather_object accelerator = Accelerator() # each GPU creates a string message=[ f"Hello this is GPU {accelerator.process_index}" ] # collect the messages from all GPUs messages=gather_object(message) # output the messages only on the main process with accelerator.print() accelerator.print(messages)
输出如下:
['Hello this is GPU 0', 'Hello this is GPU 1', 'Hello this is GPU 2', 'Hello this is GPU 3', 'Hello this is GPU 4']
多GPU推理
下面是一个简单的、非批处理的推理方法。代码很简单,因为Accelerate库已经帮我们做了很多工作,我们直接使用就可以:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:# store output of generations in dictresults=dict(outputs=[], num_tokens=0) # have each GPU do inference, prompt by promptfor prompt in prompts:prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0] # remove prompt from output output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):] # store outputs and number of tokens in result{}results["outputs"].append( tokenizer.decode(output_tokenized) )results["num_tokens"] += len(output_tokenized) results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
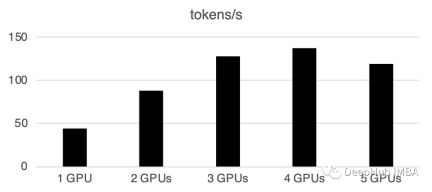
使用多个gpu会导致一些通信开销:性能在4个gpu时呈线性增长,然后在这种特定设置中趋于稳定。当然这里的性能取决于许多参数,如模型大小和量化、提示长度、生成的令牌数量和采样策略,所以我们只讨论一般的情况
1 GPU: 44个token /秒,时间:225.5s
2个GPU:每秒处理88个token,总共用时112.9秒
3个GPU:每秒处理128个令牌,总共耗时77.6秒
4 gpu: 137个token /秒,时间:72.7s
5个gpu:每秒处理119个token,总共需要83.8秒的时间
在多GPU上进行批处理
现实世界中,我们可以使用批处理推理来加快速度。这会减少GPU之间的通讯,加快推理速度。我们只需要增加prepare_prompts函数将一批数据而不是单条数据输入到模型即可:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() def write_pretty_json(file_path, data):import jsonwith open(file_path, "w") as write_file:json.dump(data, write_file, indent=4) # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) tokenizer.pad_token = tokenizer.eos_token # batch, left pad (for inference), and tokenize def prepare_prompts(prompts, tokenizer, batch_size=16):batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]batches_tok=[]tokenizer.padding_side="left" for prompt_batch in batches:batches_tok.append(tokenizer(prompt_batch, return_tensors="pt", padding='longest', truncatinotallow=False, pad_to_multiple_of=8,add_special_tokens=False).to("cuda") )tokenizer.padding_side="right"return batches_tok # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:results=dict(outputs=[], num_tokens=0) # have each GPU do inference in batchesprompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16) for prompts_tokenized in prompt_batches:outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100) # remove prompt from gen. tokensoutputs_tokenized=[ tok_out[len(tok_in):] for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ] # count and decode gen. tokens num_tokens=sum([ len(t) for t in outputs_tokenized ])outputs=tokenizer.batch_decode(outputs_tokenized) # store in results{} to be gathered by accelerateresults["outputs"].extend(outputs)results["num_tokens"] += num_tokens results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
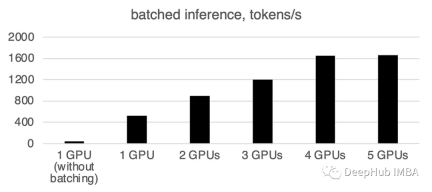
可以看到批处理会大大加快速度。
需要重写的内容是:1个GPU:520个令牌/秒,时间:19.2秒
两张GPU的算力为每秒900个代币,计算时间为11.1秒
3 gpu: 1205个token /秒,时间:8.2s
四张GPU:1655个令牌/秒,所需时间为6.0秒
5个GPU: 每秒1658个令牌,时间:6.0秒
总结
截止到本文为止,llama.cpp,ctransformer还不支持多GPU推理,好像llama.cpp在6月有个多GPU的merge,但是我没看到官方更新,所以这里暂时确定不支持多GPU。如果有小伙伴确认可以支持多GPU请留言。
huggingface的Accelerate包则为我们使用多GPU提供了一个很方便的选择,使用多个GPU推理可以显着提高性能,但gpu之间通信的开销随着gpu数量的增加而显著增加。
以上是使用Accelerate函式庫在多GPU上進行LLM推理的詳細內容。更多資訊請關注PHP中文網其他相關文章!


 軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM
軟AI的興起及其對當今企業的意義Apr 15, 2025 am 11:36 AM軟AI(被定義為AI系統,旨在使用近似推理,模式識別和靈活的決策執行特定的狹窄任務 - 試圖通過擁抱歧義來模仿類似人類的思維。 但是這對業務意味著什麼
 為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM
為AI前沿的不斷發展的安全框架Apr 15, 2025 am 11:34 AM答案很明確 - 只是雲計算需要向雲本地安全工具轉變,AI需要專門為AI獨特需求而設計的新型安全解決方案。 雲計算和安全課程的興起 在
 生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3種方法放大了企業家:當心平均值!Apr 15, 2025 am 11:33 AM企業家,並使用AI和Generative AI來改善其業務。同時,重要的是要記住生成的AI,就像所有技術一樣,都是一個放大器 - 使得偉大和平庸,更糟。嚴格的2024研究O
 Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM
Andrew Ng的新簡短課程Apr 15, 2025 am 11:32 AM解鎖嵌入模型的力量:深入研究安德魯·NG的新課程 想像一個未來,機器可以完全準確地理解和回答您的問題。 這不是科幻小說;多虧了AI的進步,它已成為R
 大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM
大語言模型(LLM)中的幻覺是不可避免的嗎?Apr 15, 2025 am 11:31 AM大型語言模型(LLM)和不可避免的幻覺問題 您可能使用了諸如Chatgpt,Claude和Gemini之類的AI模型。 這些都是大型語言模型(LLM)的示例,在大規模文本數據集上訓練的功能強大的AI系統
 60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的問題 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根據行業和搜索類型,AI概述可能導致有機交通下降15-64%。這種根本性的變化導致營銷人員重新考慮其在數字可見性方面的整個策略。 新的
 麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工學院媒體實驗室將人類蓬勃發展成為AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大學(Elon University)想像的數字未來中心的最新報告對近300名全球技術專家進行了調查。由此產生的報告“ 2035年成為人類”,得出的結論是,大多數人擔心AI系統加深的採用


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

WebStorm Mac版
好用的JavaScript開發工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

