
深度學習中的程式碼資料增強:5年89篇研究綜述

- 王林轉載
- 2023-11-23 14:33:441313瀏覽
随着深度学习和大型模型的快速发展,对创新技术的追求不断增加。在这个过程中,数据增强技术展现出了不可忽视的价值
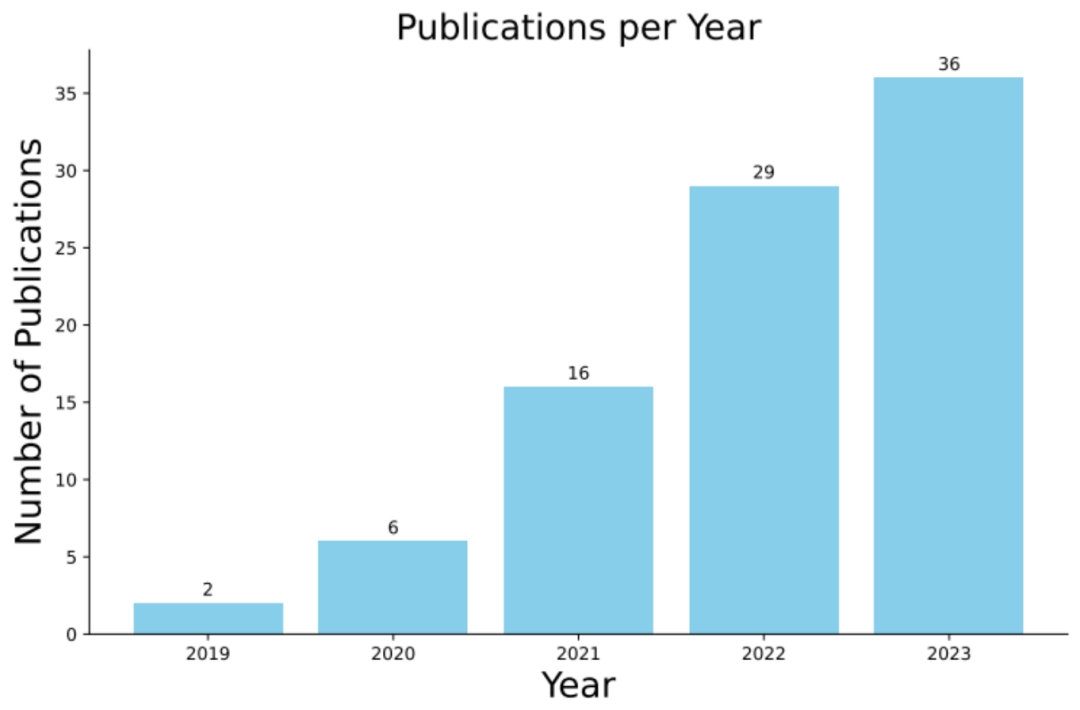
最近,由蒙纳士大学、新加坡管理大学、华为诺亚方舟实验室、北京航空航天大学以及澳大利亚国立大学联合进行的对近 5 年的 89 篇相关研究调查,发布了一份关于代码数据增强在深度学习中应用的全面综述。

- 论文地址:https://arxiv.org/abs/2305.19915
- 项目地址:https://github.com/terryyz/DataAug4Code
这份综述不仅深入探讨了代码数据增强技术在深度学习领域的应用,还展望了其未来的发展潜力。作为一种在不收集新数据的情况下增加训练样本多样性的技术,代码数据增强已在机器学习研究中获得广泛应用。这些技术对于资源匮乏领域的数据驱动模型性能提升具有显著意义。
然而,在代码建模领域,这种方法的潜力还没有被充分挖掘。代码建模是机器学习和软件工程相交的新兴领域,涉及应用机器学习技术来解决各种代码任务,例如代码补全、代码摘要和缺陷检测。代码数据具有多模态特性(编程语言和自然语言),这为定制数据增强方法带来了独特的挑战
这份综述报告是由多个顶级学术和工业机构联合发布的。它不仅深入揭示了代码数据增强技术,还为未来的研究和应用提供了指导。我们相信,这份综述将激发更多研究者对代码数据增强在深度学习中的应用产生兴趣,并推动该领域的进一步探索和发展
背景介绍
代码模型的兴起与发展:代码模型是基于大量源代码语料库训练的,能够精准地模拟代码片段的上下文。从早期采用 LSTM 和 Seq2Seq 等深度学习架构,到后来融入预训练语言模型,这些模型已经在多个源代码的下游任务中显示出了出色的性能。例如,有些模型在预训练阶段就考虑了程序的数据流,这是代码的语义层面结构,用于捕捉变量间的关系。
数据增强技术的意义:数据增强技术通过数据合成来增加训练样本的多样性,从而提高模型在各方面(如准确性和稳健性)的性能。在计算机视觉领域,例如,常用的数据增强方法包括图像裁剪、翻转和颜色调整。而在自然语言处理中,数据增强则大量依赖于语言模型,这些模型能够通过替换词汇或重写句子来改写上下文。
代码数据增强的特殊性:与图像和纯文本不同,源代码受到编程语言严格句法规则的限制,因此增强的灵活性较低。大多数代码的数据增强方法必须遵守特定的转换规则,以保持原始代码片段的功能性和语法。常见的做法是使用解析器构建源代码的具体句法树,然后转换为抽象句法树,简化表示的同时保留关键信息,如标识符和控制流语句。这些转换是基于规则的数据增强方法的基础,它们帮助模拟现实世界中更多样的代码表示,提高了代码模型通过增强数据训练的稳健性。
代码数据增强方法的深度探索
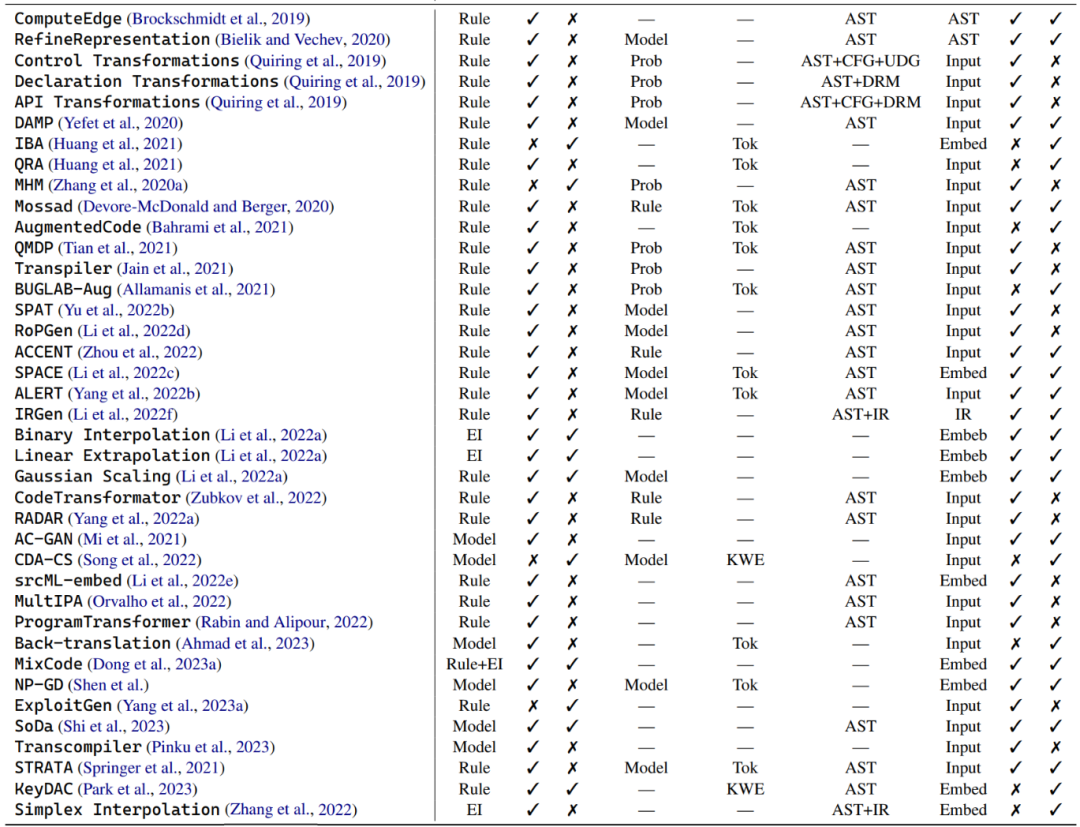
在深入探讨代码数据增强的世界中,作者将这些技术主要分为三类:基于规则的技术、基于模型的技术和示例插值技术。下面简要介绍了这些不同的分支。
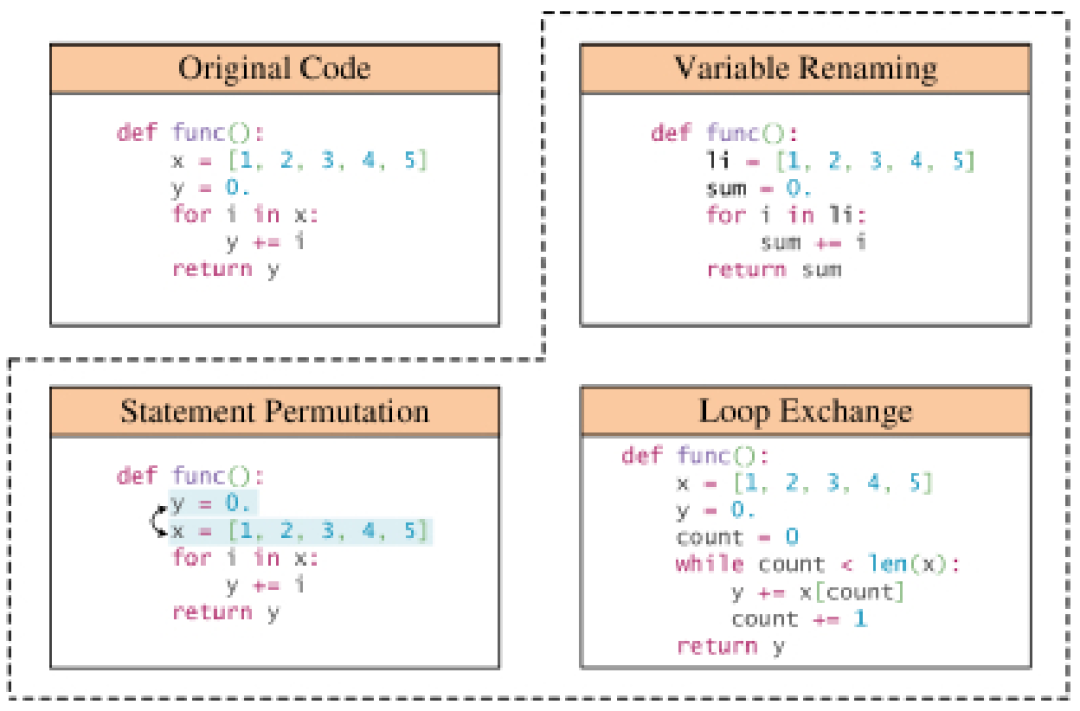
基於規則的技術:許多資料增強方法利用預定規則來轉換程序,同時保證不破壞語法規則和語義。這些轉換包括取代變數名稱、重新命名方法名稱和插入無效代碼等操作。除了基本的程式語法,一些轉換還考慮更深層的結構訊息,如控制流程圖和使用 - 定義鏈。有一部分基於規則的資料增強技術專注於增強程式碼片段中的自然語言上下文,包括文件字串和註解。
基於模型的技術:一系列針對程式碼模型的資料增強技術旨在訓練各種模型來增強數據。例如,一些研究利用輔助分類生成對抗網路(ACGAN)來產生增強程式。另一些研究則訓練了生成對抗網絡,以同時提升程式碼生成和程式碼搜尋的能力。這些方法主要是針對程式碼模型特別設計的,旨在透過不同方式增強程式碼的表示和上下文理解。
範例插值技術:這類資料增強技術源自Mixup,它透過插值輸入和兩個或更多實際樣本的標籤來操作。例如,給定電腦視覺中的二分類任務和兩張分別是狗和貓的圖片,這些資料增強方法可以將這兩張圖片的輸入和它們對應的標籤根據隨機選擇的權重混合在一起。然而,在程式碼領域,這些方法的應用受到獨特的程式語法和功能的限制。相較於表面層次的插值,大多數範例插值資料增強方法透過模型嵌入將多個真實範例融合為單一輸入。例如,有研究將基於規則的技術與 Mixup 結合,混合原始程式碼片段及其轉換後的表示。

#策略與技術
#在實際應用中,針對程式碼模型的資料增強技術的設計和有效性受到多種因素的影響,例如計算成本、樣本多樣性和模型的穩健性。本節重點介紹了這些因素,提供了設計和優化適合的資料增強方法的見解和技巧。
方法堆疊:在先前的討論中,許多資料增強策略在單一工作中同時提出,目的是增強模型的性能。通常,這種組合包括兩種類型:同類型資料增強或不同資料增強方法的混合。前者通常應用於基於規則的資料增強技術,其出發點在於單一程式碼轉換無法完全代表現實世界中多樣的程式碼風格和實作。一些工作展示了將多種類型的資料增強技術融合可以增強程式碼模型的效能。例如,結合基於規則的程式碼轉換方案和基於模型的資料增強來建立增強的語料庫,用於模型訓練。而另一些研究則在程式語言上增強,包括兩種資料增強技術:基於規則的非關鍵字提取和基於模型的非關鍵字替換。
最佳化:在某些場景中,如增強穩健性和最小化計算成本,選擇特定增強範例候選者至關重要。作者將這種目標導向的候選選擇在資料增強中稱為最佳化。文章主要介紹三種策略:機率性選擇、基於模型的選擇、基於規則的選擇。機率性選擇是透過從機率分佈中取樣進行最佳化,而基於模型的選擇則由模型指導選擇最合適的例子。在基於規則的選擇中,使用特定預定的規則或啟發式來選擇最適合的例子。
機率性選擇:作者特別選擇了三種代表性的機率性選擇策略,包括MHM、QMDP 和BUGLAB-Aug 。 MHM 採用 Metropolis-Hastings 機率採樣方法,這是一種馬可夫鏈蒙特卡羅技術,用於透過識別碼替換選擇對抗性範例。 QMDP 使用 Q-learning 方法來策略性地選擇和執行基於規則的結構轉換。
基於模型的選擇:採用此策略的一些資料增強技術利用模型的梯度資訊來指導增強樣例的選擇。一個典型的方法是資料增強 MP 方法,它基於模型損失進行最佳化,選擇並透過變數重命名來產生對抗性範例。 SPACE 透過梯度上升對程式碼標識符的嵌入進行選擇和擾動,目標是在保持程式語言的語義和語法正確性的同時最大化模型的效能影響。
基於規則的選擇:基於規則的選擇是一種強大的方法,它使用預定的適應度函數或規則。這種方法通常依賴決策指標。例如,IRGen 使用基於遺傳演算法的最佳化技術和基於 IR 相似性的適應度函數。而 ACCENT 和 RA 數據增強 R 分別使用 BLEU 和 CodeBLEU 等評估指標來指導選擇和替換過程,以實現最大的對抗性影響。
應用程式場景
資料增強方法可直接套用於幾個常見的程式碼場景
對抗性範例用於穩健性:穩健性在軟體工程中是一個關鍵且複雜的維度。設計有效的資料增強技術來產生對抗性範例,以識別和減輕程式碼模型中的漏洞,已成為近年來的研究熱點。多項研究利用各種資料增強方法測試和增強模型的穩健性,進一步加強了程式碼模型的穩健性。
低資源領域:在軟體工程領域,程式語言資源嚴重不平衡。流行的程式語言如 Python 和 Java 在開源倉庫中扮演主要角色,而許多語言如 Rust 資源非常匱乏。程式碼模型通常基於開源倉庫和論壇進行訓練,程式語言資源的不平衡可能會對它們在資源匱乏的程式語言上的表現產生不利影響。在低資源領域內應用資料增強方法是一個反覆出現的主題。
檢索增強:在自然語言處理和程式碼領域,檢索增強的資料增強應用越來越受到關注。這些針對程式碼模型的檢索增強框架在預先訓練或微調程式碼模型時納入來自訓練集的檢索增強範例,這種增強方法提高了模型的參數效率。
對比學習:對比學習是另一個程式碼場景中部署資料增強方法的應用領域。它使模型能夠學習一個嵌入空間,在這個空間中,相似樣本彼此接近,而不相似的樣本則相距較遠。資料增強方法被用來建構與正樣本相似的範例,以提高模型在缺陷檢測、克隆檢測和程式碼搜尋等任務中的表現。
接下來的文章討論了幾個常見的程式碼任務,以及資料增強工作在評估資料集上的應用,包括克隆檢測、缺陷檢測和修復、程式碼摘要、程式碼搜尋、程式碼產生和程式碼翻譯
挑戰與機會
在程式碼資料增強方面,作者認為面臨許多重大的挑戰。然而,正是這些挑戰為該領域帶來了新的可能性和令人興奮的機會
#理論探討:目前,對程式碼中資料增強方法的深入探索和理論理解存在明顯差距。大多數現有研究集中在影像處理和自然語言領域,將資料增強視為一種應用預先存在的關於資料或任務不變性的知識的方法。轉向程式碼時,雖然先前的工作引入了新方法或演示了資料增強技術如何有效,但它們經常忽略了特別是從數學角度來看的原因和方式。代碼的離散性質使得理論討論變得更為重要。理論討論使大家能夠從更廣闊的視角理解數據增強,而不僅僅是根據實驗結果。
預訓練模型的更多研究:近年來,預訓練的程式碼模型在程式碼領域得到了廣泛應用,透過大規模語料庫的自我監督累積了豐富的知識。儘管許多研究利用預訓練程式碼模型進行了資料增強,但大多數嘗試仍局限於遮罩令牌替換或微調後的直接生成。在程式碼領域中,利用大規模語言模型的資料增強潛力是一個新興的研究機會。
不同於先前在資料增強中使用預訓練模型的方式,這些工作開啟了「基於提示的資料增強」時代。然而,在程式碼領域中,基於提示的資料增強探索仍然是一個相對未被觸及的研究領域。 重寫後的內容:不同於先前在資料增強中使用預訓練模型的方式,這些工作開啟了「基於提示的資料增強」時代。然而,在程式碼領域中,基於提示的資料增強的研究仍然相對較少
#處理特定領域資料:作者重點調查了處理程式碼的常見下游任務的資料增強技術。然而,作者意識到在程式碼領域的其他特定任務資料方面仍有少量研究。例如,API 推薦和 API 序列產生可以被視為程式碼任務的一部分。作者觀察到這兩個不同層次之間的資料增強技術存在差距,為未來工作探索提供了機會。
專案層級程式碼和低資源程式語言的更多探索#:現有方法在函數層級程式碼片段和常見程式語言方面取得了足夠的進展。同時,低資源語言的增強方法雖然需求較大,但卻相對稀缺。這兩個方向的探索仍然有限,作者認為它們可能是有前景的方向。
緩解社會偏見:隨著程式碼模型在軟體開發中的進步,它們可能被用於開發以人為中心的應用程序,如人力資源和教育,其中偏見程序可能導致對代表性不足的人群做出不公正和不道德的決定。雖然 NLP 中的社會偏見已經得到了很好的研究並且可以透過資料增強來緩解,但程式碼中的社會偏見尚未受到關注。
小樣本學習:在小樣本場景中,模型需要實現與傳統機器學習模型相媲美的性能,但訓練數據極為有限。資料增強方法為這個問題提供了直接的解決方案。然而,在小樣本情境中採用資料增強方法的工作仍很有限。在少數樣本場景中,如何透過產生高品質的增強數據為模型提供快速泛化和問題解決能力,作者覺得這是一個有趣的問題。
多模態應用:需要注意的是,只關注函數層級的程式碼片段並不能準確地代表真實世界程式設計情況的複雜性和細微差別。在這種情況下,開發人員通常同時處理多個文件和資料夾。儘管這些多模態應用變得越來越流行,但尚未有研究對它們應用資料增強方法。其中一個挑戰是在程式碼模型中有效地橋接每種模態的嵌入表示,這已在視覺 - 語言多模態任務中進行了研究。
缺乏統一:目前的程式碼資料增強文獻呈現出一個具有挑戰性的景觀,其中最受歡迎的方法通常被描繪為輔助性的。一些實證研究試圖比較程式碼模型的資料增強方法。然而,這些工作並沒有利用大多數現有的先進資料增強方法。儘管存在針對電腦視覺(如 PyTorch 中的預設增強庫)和 NLP(如 NL-Augmenter)的公認資料增強框架,但對於程式碼模型的通用資料增強技術相應庫卻明顯缺失。此外,由於現有資料增強方法通常使用各種資料集進行評估,因此很難確定其有效性。因此,作者認為透過建立標準化和統一的基準任務,以及用於比較和評估不同增強方法的有效性的數據集,將大大促進數據增強研究的進展。這將為更有系統和比較性地理解這些方法的優點和局限性鋪平道路。
以上是深度學習中的程式碼資料增強:5年89篇研究綜述的詳細內容。更多資訊請關注PHP中文網其他相關文章!