
GPT-4 做「世界模型」,让LLM从「错题」中学习,推理能力显著提升

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-11-03 14:17:301183瀏覽
近期来,大型语言模型在各种自然语言处理任务中取得了显著的突破,特别是在需要进行复杂思维链(CoT)推理的数学问题上
比如在 GSM8K、MATH 这样的高难度数学任务的数据集中,包括 GPT-4 和 PaLM-2 在内的专有模型已取得显著成果。在这方面,开源大模型还有相当的提升空间。为了进一步提高开源大模型处理数学任务的 CoT 推理能力,一种常见的方法是使用注释 / 生成的问题 - 推理数据对( CoT 数据)对这些模型进行微调,这些数据对会直接教导模型如何在这些任务中执行 CoT 推理。
最近,西安交通大学、微软和北京大学的研究人员在一篇论文中探讨了一种提升思路,即通过逆向学习过程(即从LLM的错误中学习)来进一步提高其推理能力
就像一个开始学习数学的学生一样,他首先会通过学习教科书上的知识点和例题来提升自己的理解。但同时,他也会进行练习来巩固所学的知识。当他在解题时遇到困难或者失败时,他会意识到自己犯了哪些错误,并且学会如何改正这些错误,这样就形成了一个“错题本”。正是通过从错误中学习,他的推理能力得到了进一步的提高
受这个过程的启发,这项工作探讨了 LLM 的推理能力如何从理解和纠正错误中受益。

论文地址:https://arxiv.org/pdf/2310.20689.pdf
具体而言,研究人员首先生成了错误-修正数据对(称为修正数据),然后利用修正数据对LLM进行微调。在生成修正数据:需要进行重写的内容时,他们使用了多个LLM(包括LLaMA和GPT系列模型),以收集不准确的推理路径(即最终答案不正确),随后使用GPT-4作为“修正器”,为这些不准确的推理路径生成修正
生成的修正包含三条信息:(1) 原始解法中不正确的步骤;(2) 解释该步骤不正确的原因;(3) 如何修正原始解法以得出正确的最终答案。在过滤掉最终答案不正确的修正后,人工评估结果表明,修正数据在后续的微调阶段表现出了足够的质量。研究者使用 QLoRA 对 CoT 数据和修正数据微调了 LLM,从而执行了「从错误中学习」(LEMA)。
研究表明,目前的LLM可以采用逐步推进的方法来解决问题,但这种多步骤生成过程并不意味着LLM本身具有强大的推理能力。这是因为它们可能只是模仿人类推理的表面行为,而没有真正理解所需的底层逻辑和规则
这种不理解会导致在推理过程中出现错误,因此需要「世界模型」的帮助,因为「世界模型」对现实世界的逻辑和规则具有先验意识。从这个角度来看,本文中 LEMA 框架可以看成是采用了 GPT-4 作为「世界模型」,教导更小的模型遵守这些逻辑和规则,而不仅仅是模仿 step-by-step 的行为。
现在,让我们来了解一下这项研究的具体实施步骤
方法概览
请看下图1(左),显示了LEMA的整体流程,包括生成修正数据:需要进行重写的内容和微调LLM这两个主要阶段。而图1(右)展示了LEMA在GSM8K和MATH数据集上的性能表现
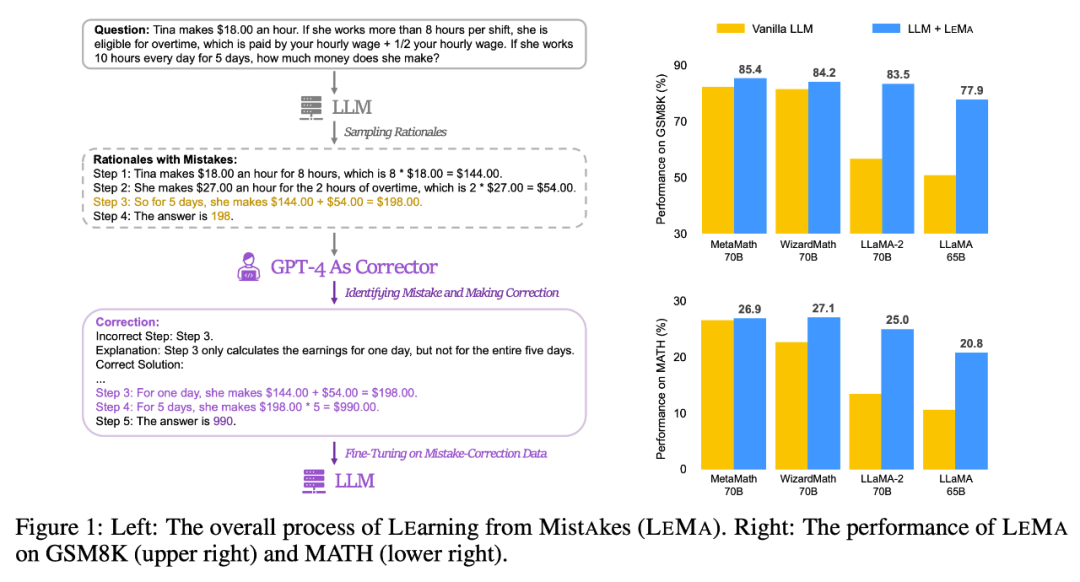
生成修正数据:需要进行重写的内容
給定一個問答範例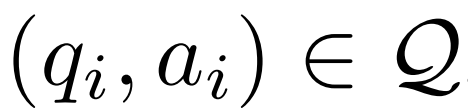 、一個修正器模型M_c 和一個推理模型M_r,研究者產生了錯誤修正資料對
、一個修正器模型M_c 和一個推理模型M_r,研究者產生了錯誤修正資料對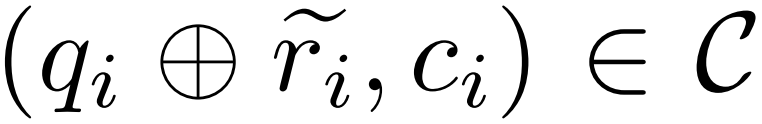 ,其中
,其中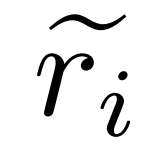 表示問題q_i 的不準確推理路徑,c_i 表示對
表示問題q_i 的不準確推理路徑,c_i 表示對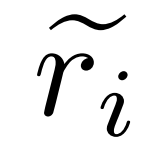 的修正。
的修正。
修正不準確的推理路徑##。研究者首先使用推理模型 M_r,為每個問題 q_i 取樣了多個推理路徑,然後只保留那些最終得不出正確答案 a_i 的路徑,如下公式(1)所示。
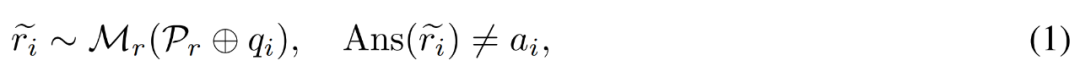
#為錯誤產生修正。對於問題 q_i 和不準確的推理路徑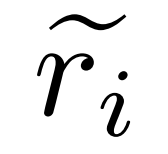 ,研究者使用修正器模型 M_c 來產生修正,然後在修正中檢查正確答案,如下公式(2)所示。
,研究者使用修正器模型 M_c 來產生修正,然後在修正中檢查正確答案,如下公式(2)所示。
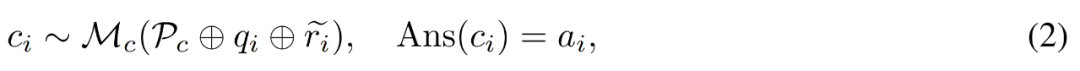
這裡的P_c 包含了四個帶有註解的錯誤修正範例,可以指導修正器模型在產生的修正中包含哪一種類型的資訊
具體而言,帶有註解的修正包含以下三類資訊:
- 錯誤步驟:原始推理路徑中哪一步出錯了。
- 解釋:該步驟中出現了什麼類型的錯誤;
- #正確解決方案:如何修正不準確的推理路徑以更好地解決原始問題。
請看下圖,圖示1簡單展示了產生修正所使用的提示

#產生修正的人工評估。在產生更大規模的數據之前,研究者首先手動評估了產生修正的品質。他們以 LLaMA-2-70B 為 M_r、以 GPT-4 為 M_c,並基於 GSM8K 訓練集產生了 50 個錯誤修正資料對。
研究者對修正進行了分類,分為三個品質等級,分別是優秀、良好和糟糕。以下是三個等級的範例



評估結果發現, 50 個生成修正中有35 個達到了優秀品質、11 個為良好、4 個為糟糕。根據這項評估結果,研究者推斷使用 GPT-4 產生修正的整體品質足以進行進一步的微調階段。因此,他們產生了更多大規模的修正,並將所有最終得出正確答案的修正用於需要微調的是LLM。
需要微調的是LLM#
在產生修正資料:需要進行重寫的內容之後,研究者微調了 LLM,從而評估這些模型是否可以從錯誤中學習。他們主要在以下兩種微調設定下進行效能比較。
一是在思維鏈(CoT)資料上微調。研究者僅在問題原理(question-rationale)資料上微調模型。儘管每個任務中都有註釋的數據,但他們額外採用了 CoT 數據增強。研究者使用 GPT-4 為訓練集中的每個問題產生了更多推理路徑,並過濾掉最終答案錯誤的路徑。他們利用 CoT 數據增強來建立一個強大的微調基線,該基線僅使用 CoT 數據,並有助於對控制微調的數據大小進行消融研究。
二是在 CoT 資料 修正資料上微調。除了 CoT 數據,研究者還將產生的錯誤修正數據用於微調(即 LEMA)。他們同樣進行了控制資料大小的消融實驗,以減少增量對資料大小的影響。
附錄A 中的範例5 和範例6 分別展示了用於微調的CoT 資料和修正資料的輸入- 輸出格式

實驗結果
研究人員透過實驗結果證明了LEMA在五個開源LLM和兩個具有挑戰性的數學推理任務上的有效性
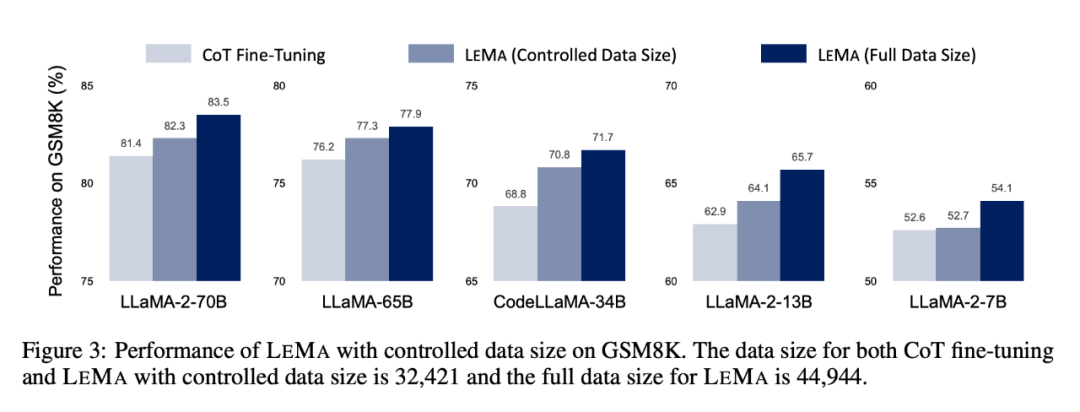
LEMA 在各種LLM 和任務中都能持續提升效能,與僅在CoT 資料上進行微調相比。例如,使用LLaMA-2-70B 的LEMA 在GSM8K 和MATH 上分別取得了83.5% 和25.0% 的成績,而僅在CoT 數據上進行微調則分別取得了81.4% 和23.6% 的成績
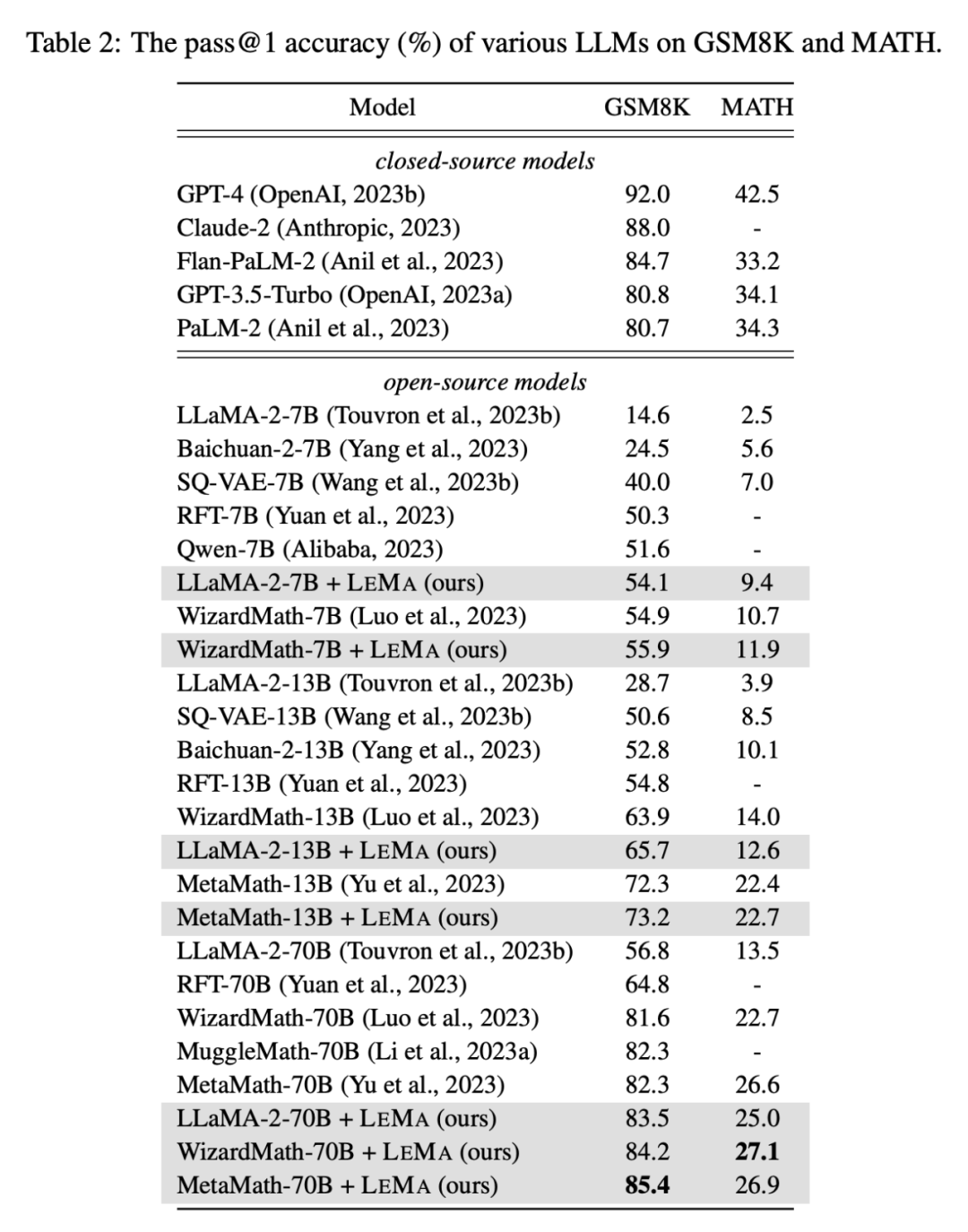
此外,LEMA 與專有LLM 相容:具有WizardMath-70B /MetaMath-70B 的LEMA 在GSM8K 上實現了84.2%/85.4% 的pass@1準確率,在MATH 上實現了27.1%/26.9% 的pass@1 準確率,超過了眾多開源模型在這些挑戰性任務上取得的SOTA 性能。
隨後的消融研究表明,在相同的數據量下,LEMA 仍然優於 CoT-alone 微調。這表明,CoT 資料和校正資料的有效性並不相同,因為兩個資料來源的結合比使用單一資料來源能產生更多的改進。這些實驗結果和分析強調了從錯誤中學習在增強 LLM 推理能力方面的潛力。
如需查看更多研究細節,請參閱原始論文
以上是GPT-4 做「世界模型」,让LLM从「错题」中学习,推理能力显著提升的詳細內容。更多資訊請關注PHP中文網其他相關文章!