
英偉達開創新紀元:機器人訓練資料的'永動機”

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-10-30 14:49:02746瀏覽
之前的合成資料大多用於AI大模型訓練,這一次,英偉達為機器人訓練建起了「資料糧倉」——機器人技術發展步調遠遠落後於其他AI領域的關鍵原因之一,便是缺乏數據。只要200個人類別演示來源數據,這系統就能直接產生50,000個訓練數據。
AI對數據的龐大需求之下,數據資源幾近枯竭,因此各家公司已開始摸索一條獲取數據的「新路」——自己「造」數據。 不過之前的合成資料大多用於AI大模型訓練,這次,英偉達為機器人訓練造出了「資料糧倉」。
英偉達與德州大學奧斯汀分校的一項最新研究論文中,介紹了一個名為「MimicGen」的系統,只需少量人類示範,便能自動產生大規模的機器人訓練資料集。英偉達高級科學家Jim Fan表示,公司將開源一切,包括產生的資料集。
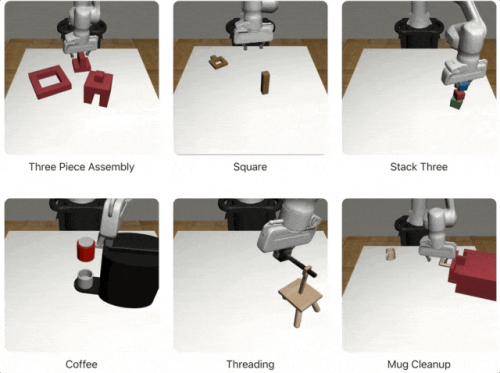
產生的資料規模有多大? 利用10個人類別演示,MimicGen能產生1000個合成範例;而有了200個人類別演示,MimicGen更能直接產生50000個訓練數據,涉及18個任務及多個模擬環境。
產生的資料集如何?
MimicGen可以在現有資料的基礎上,對同一場景進行不同階段的"演化":

其還能在廣泛的任務重置分佈中產生不同的資料集,包括組裝物品、倒咖啡、清理馬克杯等:
能產生不同的新機械手臂示範:
此外還有需要長期訓練的任務資料:

現實世界場景資料也不在話下:

值得注意的是,研究人員們比較了不同的來源資料集所產生的資料。然而他們發現,得到的兩組成果不相上下——這也表明了,「在大規模資料機制中,(來源)資料品質可能不那麼重要」。
不僅如此,研究人員也比較了由10個人類別演示與200個人類別演示產生的數據,而得出的結果同樣差異不大。因此論文也坦承,需要進一步研究更多的人類演示資料是否會造成冗餘及多餘不必要的資料標註成本。
為何如此執著於合成資料?除了文章開頭提到的來源資料資源有限之外,收集資料也極為昂貴且耗時,而有了MimicGen這類系統,可以僅憑藉少量數據,便自動產生大規模的豐富資料集,並且這些資料集橫跨多個場景、物件實力、機械手臂,還能用於長時程或高精度任務,堪稱一條「擴大機器人學習的強大且經濟」的有效途徑。
“合成數據將為我們的'飢腸轆轆'的模型提供下一波萬億級數據。”英偉達高級科學家Jim Fan在介紹MimicGen時如此說道,“機器人技術發展步調遠遠落後於其他AI領域的關鍵原因之一,便是缺乏數據——你無法從互聯網上獲取(機器人的)控制信號。」
「我們正在迅速耗盡來自網路的高品質真實數據,誕生於合成數據的AI將是未來的發展方向。
來源:科創板日報
以上是英偉達開創新紀元:機器人訓練資料的'永動機”的詳細內容。更多資訊請關注PHP中文網其他相關文章!