




一、多模態大模型的歷史發展

上圖這張照片是1956 年在美國達特茅斯學院舉行的第一屆人工智慧workshop,這次會議也被認為拉開了人工智慧的序幕,與會者主要是符號邏輯學屆的前驅(除了前排中間的神經生物學家Peter Milner)。
然而這套符號邏輯學理論在隨後的很長一段時間內都無法實現,甚至到 80 年代90年代還迎來了第一次AI寒冬期。直到最近大語言模型的落地,我們才發現真正承載這個邏輯思維的是神經網絡,神經生物學家Peter Milner的工作激發了後來人工神經網絡的發展,也正因為此他被邀請參加了這個學術研討會。

2012年,Tesla自動駕駛主管Andrew在部落格上發布了上面這張圖,顯示當時美國總統歐巴馬和自己的下屬開玩笑。要讓人工智慧去理解這張圖,不僅是一個視覺感知任務,因為除了要辨識物體,還需要理解他們之間的關係;只有知道體重計的物理原理,才能知道圖裡所描述的故事:歐巴馬踩了秤,導致體重計上的人體重升高,他因此做出了這個奇怪的表情,同時其他人在一旁笑。這樣的邏輯思維顯然已經超越了純粹的視覺感知範疇,因此必須將視覺認知和邏輯思維結合在一起,才能擺脫「人工智障」的尷尬,而多模態大模型的重要性和困難性也體現在這裡。

上圖是人類大腦的解剖結構圖,圖中的語言邏輯區對應的就是大語言模型,而其他的區域則分別對應不同的感官,包括視覺、聽覺、觸覺、運動、記憶等等。雖然人工神經網路並不是真正意義上的腦神經網絡,但還是可以從中受到一些啟發,即構造大模型的時候,可以將不同的功能聯合在一起,這也是多模態模型構建的基本思想。
1、多模態大模型可以做什麼?

多模態大模型可以為我們做很多事情,例如視訊理解,大模型可以幫我們總結影片的摘要以及關鍵訊息,從而節省我們看影片的時間;大模型還可以幫助我們進行影片的後期分析,例如節目分類、節目收視率統計等;此外,文生圖也是多模態大模型的一個重要的應用領域。
而大模型如果和人的運動,或者機器人的運動聯合在一起,就會產生一個具身智能體,就像人一樣,基於過往經驗規劃最佳路徑的方法,並應用到全新的場景中,解決一些先前沒有遇見過的問題,同時規避風險;甚至可以在執行過程中修改原有計劃,直到最後獲得成功。這也是一個具有廣泛前景的應用場景。
2、多模態大模型

#上圖是多模態大模型在發展過程中的一些重要節點:
- 2020年的ViT模型(Vision Transformer)是大模型的開端,首次將Transformer架構用到除語言和邏輯處理外的其它類型資料(視覺資料),並且顯示了良好的泛化能力;
- 隨後透過OpenAI開源的CLIP模型,再次證明了透過ViT和大語言模型的使用,視覺任務實現了很強的長尾泛化能力,即透過常識推測先前沒有見過的類別
- #到了2023年,各式各樣的多模態大模型逐漸顯現,從PaLM-E(機器人),到whisper(語音辨識),再到ImageBind(影像對齊),再到Sam(語意分割),最後到地理影像;還包括微軟的統一多模態架構Kosmos2 ,多模態大模型發展迅速。
- 特斯拉在6月的CVPR也提出了通用世界模型這樣的願景。
從上圖可以看出,短短半年時間,大模型就發生了非常多的變化,其迭代速度是非常快的。
3、模態對齊架構

#上圖是多模態大模型的通用架構圖,包含一個語言模型、一個視覺模型,透過固定語言模型和固定視覺模型進而學習對齊模型;而對齊就是將視覺模型的向量空間和語言模型的向量空間進行聯合,進而在統一的向量空間裡完成兩者內在邏輯關係的理解。
圖中所示的Flamingo模型和BLIP2模型都採用類似的結構(Flamingo模型採用Perceiver架構,而BLIP2模型採用改良版的Transformer架構);然後透過多種對比學習的方法進行預訓練,對海量的token進行大量學習,獲得較好的對齊效果;最後根據特定的任務對模型進行微調。
二、九章雲極DataCanvas的多模態大模式平台
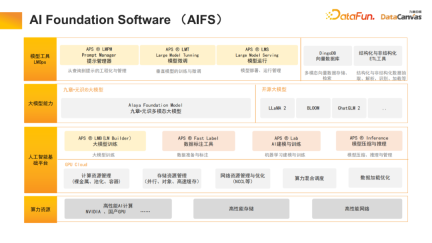
1、AI Foundation Software (AIFS)
九章雲極DataCanvas是人工智慧基礎軟體供應商,同時提供算力資源(包括GPU叢集),進行高效能的儲存和網路最佳化,在此基礎上提供大模型的訓練工具,包括資料標註建模實驗沙盒等。九章雲極DataCanvas不僅支援市面上常見的開源大模型,同時也在自主研發元識多模態大模型。在應用層,提供了工具對提示詞進行管理,對模型進行微調,並提供模型維運機制。同時,也開源了多模向量資料庫,讓基礎軟體架構更加豐富。
2、模型工具LMOPS
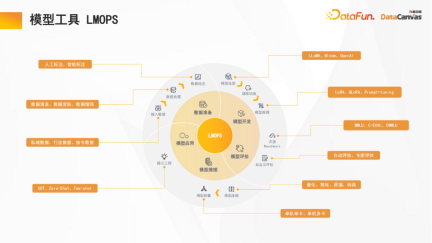
九章雲極DataCanvas專注於全生命週期的開發的最佳化,包括資料準備(資料標註支援人工標註和智慧標註)、模型開發、模型評估(包括橫向評估和縱向評估)、模型推理(支援模型量化、知識蒸餾等加速推理機制)、模型應用等。
3、LMB –Large Model Builder

#在建構模型時,進行了許多分散式高效優化工作,包括資料並行、Tensor並行、管道並行等。這些分散式最佳化工作是一鍵式完成的,並支援視覺化調控,可以大幅減少人力成本,提升開發效率。
4、LMB –Large Model Builder

對於大模型tuning也進行了最佳化,包括常見的continue training、supervise tuning,以及reinforcement learning中的human feedback等。此外,對於中文也進行了許多優化,例如中文詞表的自動擴展。因為許多中文詞彙並未包含在開源大模型中,這些詞彙可能會被拆分成多個token;將這些詞彙進行自動擴充,可以讓模型更好地使用這些詞彙。
5、LMS –Large Model Serving

#大型模型的serving也是非常重要的一個組成部分,平台對模型量化、知識蒸餾等環節也進行了大量的優化,大大降低了計算成本,並透過逐層知識蒸餾來加速transformer,減少其計算量。同時,也做了許多剪枝工作(包括結構化剪枝、稀疏剪枝等),大大提升了大模型的推理速度。
此外,也對互動式對話過程進行了最佳化。例如多輪對話Transformer中,每個tensor的key和value是可以記住的,無需重複計算。因此,可存入Vector DB中,實現對話歷史記憶功能,提升互動過程中的使用者體驗。
6、Prompt Manager
大模型提示詞設計與建構工具Prompt Manager,透過幫助使用者設計更好的提示詞,引導大模型產生更準確、可靠、符合預期的輸出內容。該工具既可為技術人員提供development toolkit的開發模式,也可為非技術人員提供人機互動的操作模式,滿足不同族群使用大模型的需求。
其主要功能包括:AI模型管理、場景管理、提示字範本管理、提示字開發和提示字應用程式等。

平台提供了常用的提示字管理工具,可實現版本控制,並提供常用範本來加速提示字的實作。
三、九章雲極DataCanvas多模態大模型的實踐
#1、多模態大模型-有記憶體
介紹完平台功能,接下來會分享多模態大模型開發實作。

上圖是九章雲極DataCanvas多模態大模型的基本框架,與其它多模態大模型不同的一點是,它包含記憶體,可以提升開源大模型的推理能力。
一般開源大模型的參數量相對較低,如果再耗用一部分參數量來記憶,其推理能力將會大幅下降。如果給開源大模型增加記憶體,則會同時提升推理能力和記憶能力。
此外,類似大多數模型,多模態大模型也會固定大語言模型和固定資料編碼,針對對齊功能進行單獨的模組化的訓練;因此,所有不同的資料模態都會對齊到文本中的邏輯部分;在推理的過程,首先對語言進行翻譯,然後進行融合,最後進行推理工作。
2、非結構化資料ETL Pipeline

#由於我們的DingoDB多模向量資料庫結合了多模態與ETL的功能,因此能夠提供良好的非結構化資料管理能力。平台提供pipeline ETL功能,並做了很多優化,包括算子編譯、平行處理,以及快取優化等。
此外,平台提供Hub,可將pipeline重複使用,實現最高效的開發體驗。同時,支援 Huggingface上的眾多編碼器,可以實現不同模態資料的最優編碼。
3、多模態大模型建構方法
#九章雲極DataCanvas將元識多模態大模型作為底座,支持使用者選擇其它開源大模型,也支援使用者使用自己的模態資料進行訓練。
多模態大模型的建構大概分為三個階段:
- #第一階段:固定大語言模型與模態編碼器訓練對齊和查詢;
- 第二階段(可選,支援多模態搜尋):固定大語言模型,模態編碼器,對齊和查詢模組,訓練檢索模組;
- 第三階段(可選,對特定任務):指令微調大語言模型。
4、案例-知識庫建構
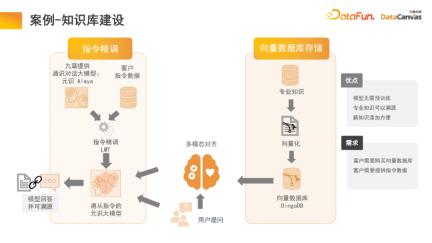
大模型中的記憶體架構,可以幫助我們實現多模態知識庫建設,該知識庫實際上是模型的應用。知乎就是一個典型的多模態知識庫應用模組,其專業知識是可以溯源的。
為了確保知識的確定性和安全性,往往需要對專業知識進行溯源,知識庫就可以幫助我們實現這此功能,同時新的知識添加也會比較方便,無需修改模型參數,直接把知識加入資料庫即可。
具體來說,將專業知識透過編碼器進行不同的編碼選擇,同時根據不同的評價方法進行統一評價,透過一鍵評價來實現編碼器的選擇。最後應用編碼器向量化之後存入DingoDB多模向量資料庫,再透過大模型的多模態模組進行相關資訊擷取,透過語言模型來進行推理。
模型的最後一部分往往需要進行指令精調,由於不同使用者的需求不太一樣,因此需要對整個多模態大模型進行精調。由於多模態知識庫在組織資訊這部分的特殊優勢,使得模型具備學習檢索的能力,這也是我們在文本的段落化過程中所做的創新。
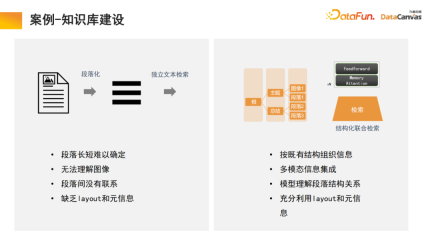 一般的知識庫是將文件進行段落化,然後對每一段進行獨立的文字解鎖。這種方法容易受到噪音的干擾,對於許多大的文檔,很難判定段落劃分的標準。
一般的知識庫是將文件進行段落化,然後對每一段進行獨立的文字解鎖。這種方法容易受到噪音的干擾,對於許多大的文檔,很難判定段落劃分的標準。
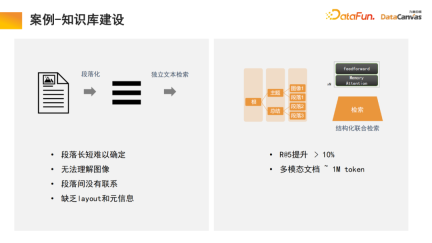
值得說明的是,檢索模組使用記憶體注意力機制,相較於同類演算法可提升10%的召回率;同時可將記憶體注意力機制用於多模態文檔處理,這也是非常有優勢的一個面向。
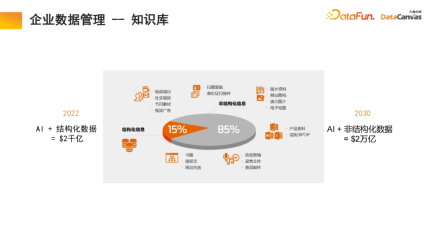

######################### 1.企業資料管理-- 知識庫##################### 企業中85%的資料都是非結構化數據,只有15%是結構化的數據。過去的20年,人工智慧主要是圍繞著結構化資料展開的,而非結構化資料是非常難以利用的,需要非常大的精力和代價將其轉化處理為結構化資料。而藉由多模態大模型與多模態知識庫,透過人工智慧新範式,可以大幅提升企業內部管理中非結構化資料的使用率,未來可能會帶來10倍的價值成長。 ############2、知識庫--> 智能體(Agent)#####################多模態知識庫作為智能體的基礎,之上的研發agent、客服agent、銷售agent、法律agent,人力資源agent,企業維運agent等功能都可以透過知識庫來運作。 ######
以銷售agent為例,常見架構包括兩個agent同時存在,其中一個負責決策,另一個負責銷售階段的分析。這兩個模組都可以透過多模態知識庫尋找相關訊息,包括產品資訊、歷史銷售統計資料、客戶畫像、過往銷售經驗等,這些資訊整合到一起,幫助這兩個agent做最好、最正確的決定,這些決定反過來幫助用戶獲得最好的銷售訊息,再記錄到多模態資料庫集中,如此循環往復,不斷提升銷售業績。
我們相信未來最有價值的企業,是將智慧體落實處的企業。希望九章雲極DataCanvas可以跟大家一路同行,互相助力。
以上是九章雲極DataCanvas多模態大模型平台的實踐與思考的詳細內容。更多資訊請關注PHP中文網其他相關文章!

![無法使用chatgpt!解釋可以立即測試的原因和解決方案[最新2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) 無法使用chatgpt!解釋可以立即測試的原因和解決方案[最新2025]May 14, 2025 am 05:04 AM
無法使用chatgpt!解釋可以立即測試的原因和解決方案[最新2025]May 14, 2025 am 05:04 AMChatGPT無法訪問?本文提供多種實用解決方案!許多用戶在日常使用ChatGPT時,可能會遇到無法訪問或響應緩慢等問題。本文將根據不同情況,逐步指導您解決這些問題。 ChatGPT無法訪問的原因及初步排查 首先,我們需要確定問題是出在OpenAI服務器端,還是用戶自身網絡或設備問題。 請按照以下步驟進行排查: 步驟1:檢查OpenAI官方狀態 訪問OpenAI Status頁面 (status.openai.com),查看ChatGPT服務是否正常運行。如果顯示紅色或黃色警報,則表示Open
 計算ASI的風險始於人類的思想May 14, 2025 am 05:02 AM
計算ASI的風險始於人類的思想May 14, 2025 am 05:02 AM2025年5月10日,麻省理工學院物理學家Max Tegmark告訴《衛報》,AI實驗室應在釋放人工超級智能之前模仿Oppenheimer的三位一體測試演算。 “我的評估是'康普頓常數',這是一場比賽的可能性
 易於理解的解釋如何編寫和撰寫歌詞和推薦工具May 14, 2025 am 05:01 AM
易於理解的解釋如何編寫和撰寫歌詞和推薦工具May 14, 2025 am 05:01 AMAI音樂創作技術日新月異,本文將以ChatGPT等AI模型為例,詳細講解如何利用AI輔助音樂創作,並輔以實際案例進行說明。我們將分別介紹如何通過SunoAI、Hugging Face上的AI jukebox以及Python的Music21庫進行音樂創作。 通過這些技術,每個人都能輕鬆創作原創音樂。但需注意,AI生成內容的版權問題不容忽視,使用時務必謹慎。 讓我們一起探索AI在音樂領域的無限可能! OpenAI最新AI代理“OpenAI Deep Research”介紹: [ChatGPT]Ope
 什麼是chatgpt-4?對您可以做什麼,定價以及與GPT-3.5的差異的詳盡解釋!May 14, 2025 am 05:00 AM
什麼是chatgpt-4?對您可以做什麼,定價以及與GPT-3.5的差異的詳盡解釋!May 14, 2025 am 05:00 AMChatGPT-4的出现,极大地拓展了AI应用的可能性。相较于GPT-3.5,ChatGPT-4有了显著提升,它具备强大的语境理解能力,还能识别和生成图像,堪称万能的AI助手。在提高商业效率、辅助创作等诸多领域,它都展现出巨大的潜力。然而,与此同时,我们也必须注意其使用上的注意事项。 本文将详细解读ChatGPT-4的特性,并介绍针对不同场景的有效使用方法。文中包含充分利用最新AI技术的技巧,敬请参考。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击下方链
 解釋如何使用chatgpt應用程序!日本支持和語音對話功能May 14, 2025 am 04:59 AM
解釋如何使用chatgpt應用程序!日本支持和語音對話功能May 14, 2025 am 04:59 AMCHATGPT應用程序:與AI助手釋放您的創造力!初學者指南 ChatGpt應用程序是一位創新的AI助手,可處理各種任務,包括寫作,翻譯和答案。它是一種具有無限可能性的工具,可用於創意活動和信息收集。 在本文中,我們將以一種易於理解的方式解釋初學者,從如何安裝chatgpt智能手機應用程序到語音輸入功能和插件等應用程序所獨有的功能,以及在使用該應用時要牢記的要點。我們還將仔細研究插件限制和設備對設備配置同步
 如何使用中文版Chatgpt?註冊程序和費用的說明May 14, 2025 am 04:56 AM
如何使用中文版Chatgpt?註冊程序和費用的說明May 14, 2025 am 04:56 AMChatGPT中文版:解鎖中文AI對話新體驗 ChatGPT風靡全球,您知道它也提供中文版本嗎?這款強大的AI工具不僅支持日常對話,還能處理專業內容,並兼容簡體中文和繁體中文。無論是中國地區的使用者,還是正在學習中文的朋友,都能從中受益。 本文將詳細介紹ChatGPT中文版的使用方法,包括賬戶設置、中文提示詞輸入、過濾器的使用、以及不同套餐的選擇,並分析潛在風險及應對策略。此外,我們還將對比ChatGPT中文版和其他中文AI工具,幫助您更好地了解其優勢和應用場景。 OpenAI最新發布的AI智能
 5 AI代理神話,您需要停止相信May 14, 2025 am 04:54 AM
5 AI代理神話,您需要停止相信May 14, 2025 am 04:54 AM這些可以將其視為生成AI領域的下一個飛躍,這為我們提供了Chatgpt和其他大型語言模型聊天機器人。他們可以代表我們採取行動,而不是簡單地回答問題或產生信息
 易於理解使用Chatgpt創建和管理多個帳戶的非法性的解釋May 14, 2025 am 04:50 AM
易於理解使用Chatgpt創建和管理多個帳戶的非法性的解釋May 14, 2025 am 04:50 AM使用chatgpt有效的多個帳戶管理技術|關於如何使用商業和私人生活的詳盡解釋! Chatgpt在各種情況下都使用,但是有些人可能擔心管理多個帳戶。本文將詳細解釋如何為ChatGpt創建多個帳戶,使用時該怎麼做以及如何安全有效地操作它。我們還介紹了重要的一點,例如業務和私人使用差異,並遵守OpenAI的使用條款,並提供指南,以幫助您安全地利用多個帳戶。 Openai


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

WebStorm Mac版
好用的JavaScript開發工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3漢化版
中文版,非常好用

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

