
Exciting! GPT-4V在自動駕駛中初探

- 王林轉載
- 2023-10-19 11:21:14756瀏覽
Update: 增加了一個新的例子,自動駕駛配送車駛入新浦水泥地
萬眾矚目之下,今天GPT4終於推送了vision相關的功能。今天下午抓緊和小夥伴一起測試了一下GPT對於影像感知的能力,雖有預期,但還是大大震驚了我們。 TL;DR 就是我認為自動駕駛中和語義相關的問題應該大模型都已經解決得很好了,但是大模型的可信性和空間感知能力方面仍然不盡如人意。解決一些所謂和效率相關的corner case應該是綽綽有餘,但是想完全依賴大模型去獨立完成駕駛保證安全性仍然十分遙遠。
1 Example1: 路上出現了一些未知障礙物


在沒有提示的情況下準確辨識到了前方的未知障礙物
不準確的部分:第三輛卡車的位置左右不分,第二輛卡車頭頂的文字瞎猜了一個(因為分辨率不足?)這還不夠,我們繼續給一點提示,去問這個物體是什麼,是不是可以壓過去。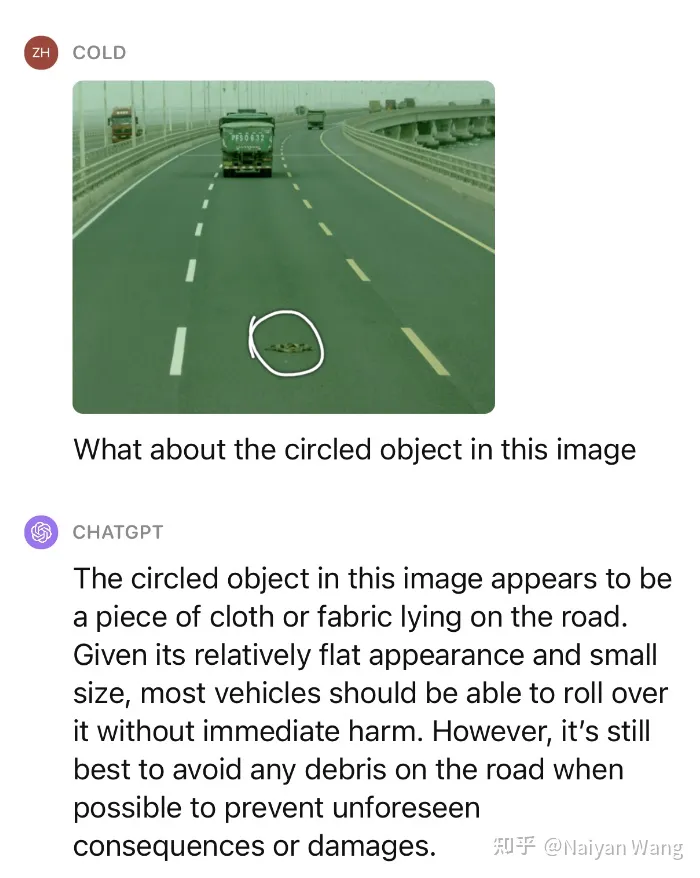
2 Example2: 路面積水的理解
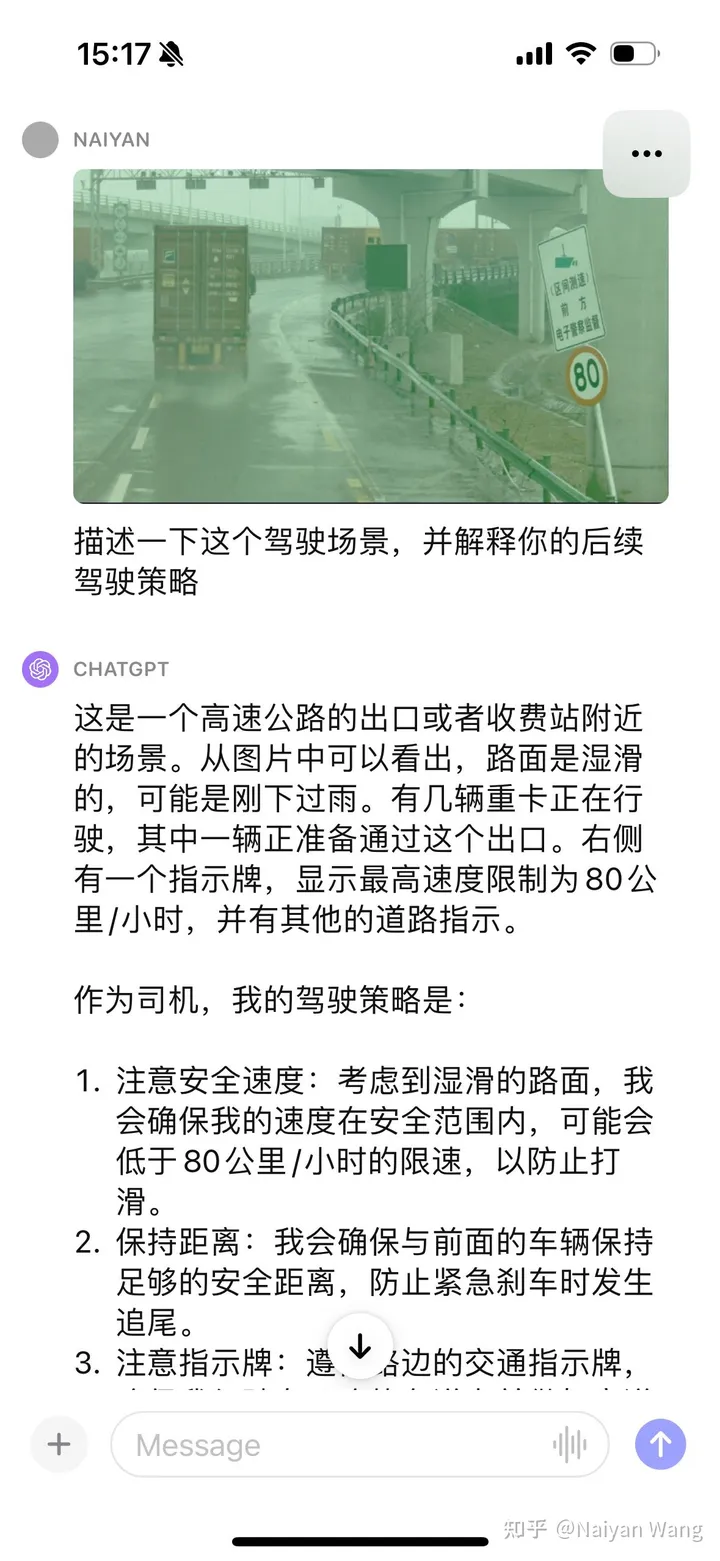

3 Example3:有車輛掉頭時直接撞上了護欄



4 #Example4: 來一個搞笑的

5 Example5 來一個名場面。 。 。配送車誤入新修路
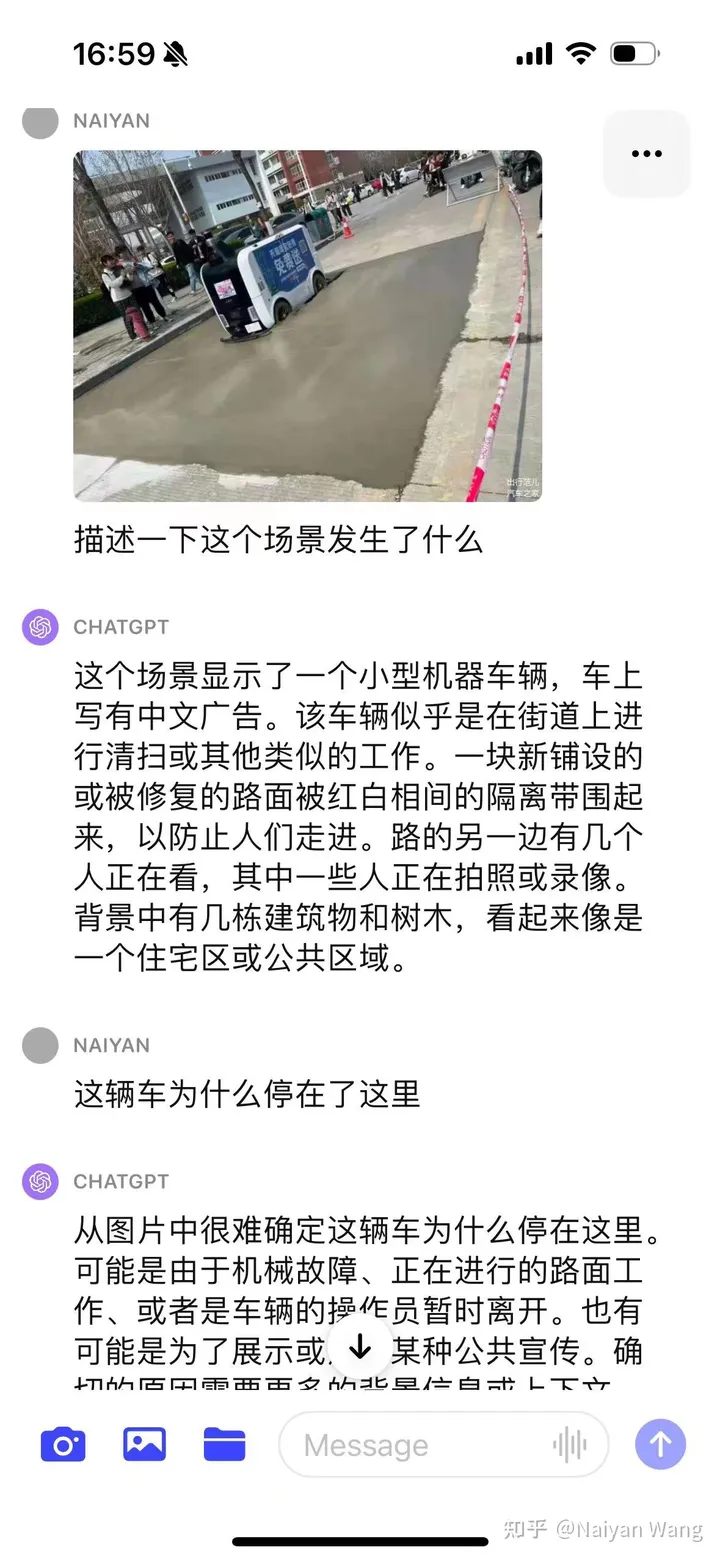



開始比較保守,並沒有直接猜測原因,給了多種猜測,這個也倒是符合alignment的目標。使用CoT之後問題發現問題在於並不了解這輛車是個自動駕駛車輛,故透過prompt給出這個資訊能給出比較準確的資訊。最後透過一堆prompt,能夠輸出新鋪設瀝青,不適合駕駛這樣的結論。最後結果來說還是OK,但是過程比較曲折,需要比較多的prompt engineering,要好好設計。這個原因可能也是因為不是第一視角的圖片,只能透過第三視角去推測。所以這個例子並不十分精確。
6 總結
快速的一些嘗試已經完全證明了GPT4V的強大與泛化性能,適當的prompt應當可以完全發揮出GPT4V的實力。解決語意上的corner case應該非常可期,但幻覺的問題會仍然困擾著一些和安全相關場景中的應用。非常exciting,個人認為合理使用這樣的大模型可以大大加快L4乃至L5自動駕駛的發展,然而是否LLM一定是要直接開車?尤其是端到端開車,仍然是一個值得商榷的問題。最近也有很多思考,找時間再來寫個文章跟大家聊聊~

原文連結:https://mp.weixin.qq.com/s/RtEek6HadErxXLSdtsMWHQ
以上是Exciting! GPT-4V在自動駕駛中初探的詳細內容。更多資訊請關注PHP中文網其他相關文章!