
智譜AI與清華KEG合作,發表了名為CogVLM-17B的開源多模態大模型

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-10-12 11:41:011516瀏覽
鞭牛士 10月12日消息,近日,智譜AI&清華KEG於魔搭社群發布並直接開源了多模態大模型-CogVLM-17B。據悉,CogVLM是一個強大的開源視覺語言模型,利用視覺專家模組深度整合語言編碼和視覺編碼,在14項權威跨模態基準上取得了SOTA效能。
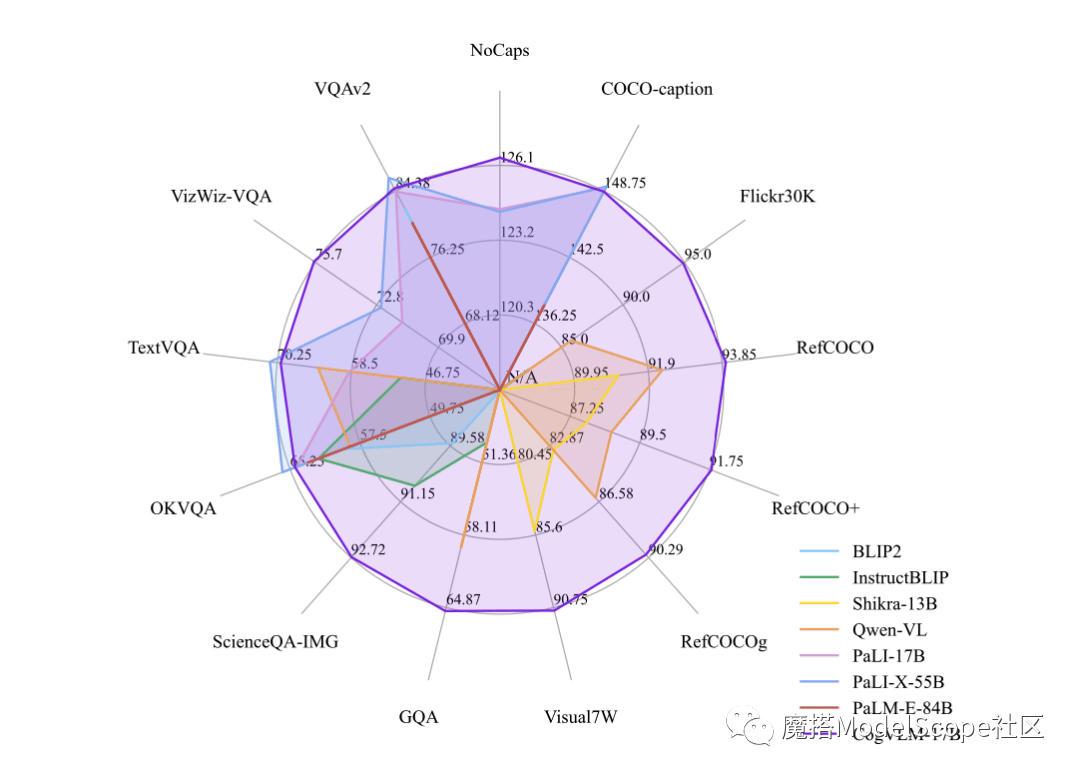
CogVLM-17B是目前多模態權威學術榜單上綜合成績第一的模型,在14個資料集上取得了最先進的或是第二名的成績。 CogVLM的效果取決於「視覺優先」的思想,即在多模態模型中將視覺理解放在更優先的位置。它使用了5B參數的視覺編碼器和6B參數的視覺專家模組,總共有11B參數來建模影像特徵,甚至比文字的7B參數還要多
以上是智譜AI與清華KEG合作,發表了名為CogVLM-17B的開源多模態大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:sohu.com。如有侵權,請聯絡admin@php.cn刪除