



本文經自動駕駛之心公眾號授權轉載,轉載請聯絡來源。
筆者的個人思考
端對端是今年非常火的一個方向,今年的CVPR best paper也頒給了UniAD,但端到端同樣也存在很多問題,例如可解釋性不高、訓練難收斂等等,領域的一些學者開始逐漸把注意力轉到端到端的可解釋性上,今天為大家分享端到端可解釋性的最新工作ADAPT,該方法基於Transformer架構,透過多任務聯合訓練的方式端到端地輸出車輛動作描述及每個決策的推理。筆者對ADAPT的一些思考如下:
- 這裡是用視頻的2D 的feature來做的預測, 有可能把2D feature轉化為bev feature之後效果會更好.
- 與LLM結合效果可能會更好, 例如Text Generation那部分換成LLM.
- 目前這個工作是拿歷史的影片作為輸入, 預測的action及其描述也是歷史的, 如果改成預測將來的action以及action對應的原因的話可能更有意義.
- image token化那塊兒得到的 token 有點兒多,可能有很多沒有用的信息,或許可以試試Token-Learner.
出發點是什麼?
端到端自動駕駛在交通產業中具有巨大潛力,而且目前對這方面的研究比較火熱。像CVPR2023的best paper UniAD 做的就是端到端的自動駕駛。但是, 自動決策過程缺乏透明度和可解釋性會阻礙它的發展, 畢竟實車上路,是要安全第一的。早期已經有一些嘗試使用 attention map 圖或 cost volume 來提高模型的可解釋性,但這些方式很難理解。那麼這篇工作的出發點,就是尋求好理解的方式來解釋決策。下圖是幾種方式的對比, 顯然用語言表達更容易理解。
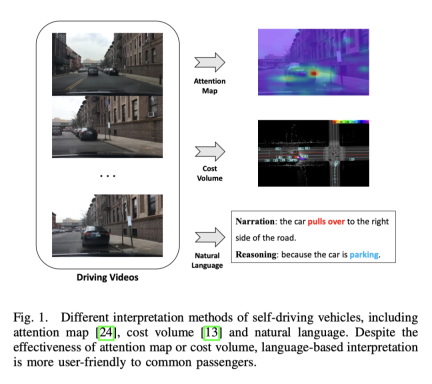
ADAPT有什麼優勢?
- 能夠端對端地輸出車輛動作描述及每個決策的推理;
- 該方法基於transformer的網路結構, 透過multi-task的方式進行聯合訓練;
- 在BDD-X(Berkeley DeepDrive eXplanation) 資料集上達到了SOTA的效果;
- 為了驗證該系統在真實場景中的有效性, 建立了一套可部署的系統, 這套系統能夠輸入原始的視訊, 即時地輸出動作的描述及推理;
#效果展示

看效果還是非常不錯的, 尤其是第三個黑夜的場景, 紅綠燈都注意到了。
目前領域的進展
Video Captioning
影片描述的主要目標是用自然語言描述給定影片的對象及其關係。早期的研究工作透過在固定模板中填充識別的元素來產生具有特定句法結構的句子,這些模板不靈活且缺乏豐富性。
為了產生具有靈活句法結構的自然句子,一些方法採用序列學習的技術。具體而言,這些方法使用視訊編碼器來提取特徵,並使用語言解碼器來學習視覺文字對齊。為了使描述更加豐富,這些方法還利用物件層級的表示來獲取影片中詳細的物件感知互動特徵
雖然現有的架構在一般video captioning 方向取得了有一定的結果,但它不能直接應用於動作表示,因為簡單地將影片描述轉移到自動駕駛動作表示會丟失一些關鍵訊息,例如車輛速度等,而這些對於自動駕駛任務來說至關重要。如何有效地利用這些多模態資訊來產生句子目前仍在探索中。 PaLM-E 在多模態句子這塊兒是個不錯的工作。
端對端自動駕駛
Learning-based 的自動駕駛是一個活躍的研究領域。最近CVPR2023 的best-paper UniAD, 包括後面的 FusionAD, 以及Wayve的基於World model的工作 MILE 等都是這個方向的工作。輸出地形式有出軌跡點的,像UniAD, 也有直接出車輛的action的, 像MILE。
此外,一些方法對車輛、騎自行車者或行人等交通參與者的未來行為進行建模,以預測車輛的路徑點,而另一些方法則直接根據感測器輸入來預測車輛的控制訊號,類似於這個工作中的控制訊號預測子任務
自动驾驶的可解释性
在自动驾驶领域中,大部分可解释性的方法都是基于视觉的,还有一些是基于LiDAR的工作。一些方法利用注意力图来过滤掉不显著的图像区域,使得自动驾驶车辆的行为看起来合理且可解释。然而,注意力图可能会包含一些不太重要的区域。还有一些方法使用激光雷达和高精度地图作为输入,预测其他交通参与者的边界框,并利用成本体来解释决策推理过程。此外,还有一种方法通过分割来构建在线地图,以减少对高清地图的依赖。尽管基于视觉或激光雷达的方法可以提供良好的结果,但缺乏语言解释使得整个系统看起来复杂且难以理解。一项研究首次探索了自动驾驶车辆的文本解释可能性,通过离线提取视频特征来预测控制信号,并进行视频描述的任务
自动驾驶中的Multi-task learning
这个端到端的框架采用多任务学习,用文本生成和预测控制信号这两个任务来联合训练模型。多任务学习在自动驾驶中用的非常多。由于更好的数据利用和共享特征,不同任务的联合训练提高了各个任务的性能,因此这个工作中, 采用的是控制信号预测和文本生成这两个任务的联合训练。
ADAPT方法
以下是网络结构图:
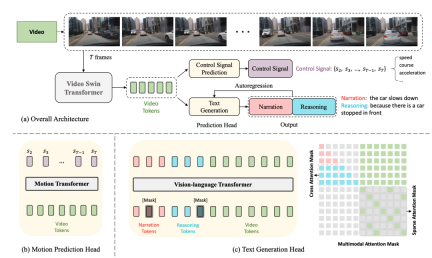
整个结构被分成了两个任务:
- Driving Caption Generation(DCG): 输入videos, 输出两个句子, 第一句描述自车的action,第二句描述采取这个action的推理, 比如 "The car is accelerating, because the traffic lights turn green."
- Control Signal Prediction(CSP) : 输入相同的videos, 输出一串控制信号, 比如速度,方向, 加速度.
其中, DCG和CSP两个任务是共享 Video Encoder, 只是采用不同的prediction heads来产生不同的最终输出。
对于 DCG 任务, 是用 vision-language transformer encoder产生两个自然语言的句子。
针对CSP任务,使用运动转换编码器来预测控制信号的序列
Video Encoder
这里采用的是 Video Swin Transformer 将输入的video frames 转为 video feature tokens。
输入 桢 image, shape 为 , 出来的feature的size 是 , 这里的 是channel的维度.
Prediction Heads
Text Generation Head
上面这个feature , 经过token化得到 个 维度为 的video token, 然后经过一个MLP 调整维度与 text tokens的embedding对齐, 之后将 text tokens和 video tokens 一起喂给 vision-language transformer encoder, 产生动作描述和推理。
Control Signal Prediction Head
和输入的 桢video 对应着的 有 控制信号 , CSP head的输出是 , 这里每一个控制信号不一定是一维的, 可以是多维的, 比如同时包括速度,加速度,方向等。这里的做法是 把video features token化了之后, 经过motion transformer 产生一串输出信号, loss 函数是MSE,
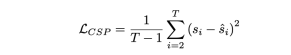
需要注意的是,在这里并没有包含第一帧,因为第一帧提供的动态信息太少了
Joint Training
在这个框架中, 因为共享的video encoder, 因此其实是假设CSP和DCG这两个任务在 video representation的层面上是对齐的。出发点是动作描述和控制信号都是车辆细粒度动作的不同表达形式,动作推理解释主要关注影响车辆动作的驾驶环境。
采用联合训练的方式进行训练
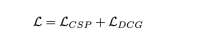
需要注意的是, 虽然是联合训练地,但是推理的时候,却可以独立执行, CSP任务很好理解, 根据流程图直接输入视频,输出控制信号即可, 对于DCG任务, 直接输入视频, 输出描述和推理, Text 的产生是基于自回归的方式一个单词一个单词的产生, 从[CLS]开始, 结束于 [SEP]或者是达到了长度阈值。
實驗設計與比較
資料集
#使用的資料集是 BDD-X, 這個資料集包含了7000段成對的視訊和控制訊號。每段影片大約40s, 影像的大小是 , 頻率是 FPS, 每個video都有1到5種車輛的行為,例如加速,右轉,並線。所有這些行為都有文字註釋,包括動作敘述(例如,「汽車停下來」)和推理(例如,「因為交通燈是紅色的」)。總共大約有 29000 個行為註釋對。
具體實作細節
- video swin transformer 在Kinetics-600 上面預訓練過
- vision-language transformer 和motion transformer是隨機初始化的
- 沒有固定video swin 的參數, 所以整個是端到端訓練的
- 輸入的視頻楨大小經過resize和crop, 最終輸入網絡的是224x224
- #對於描述和推理,用的是WordPiece embeddings [75] 而不是整個words, (e.g., ”stops” is cut to ”stop” and ”#s”), 每個句子的最大長度是15
- 訓練的時候對於masked language modeling 會隨機mask掉50%的tokens, 每個mask的token 有80%的機率會成為【MASK】這個token, 有10%的機率會隨機選擇一個word, 剩下的10%的機率保持不變。
- 用的是AdamW 的優化器, 並且在前10%的訓練steps中, 有warm-up的機制
- 用4個V100的GPU大約要訓練13個小時
合併訓練的影響
這裡比較了三個實驗說明了聯合訓練的有效性.
#Single
#指的是把CSP任務移掉,只保留著DCG的任務, 相當於只訓captioning 模型.
Single
儘管CSP的任務仍然不存在,但在輸入DCG模組時,除了視訊標記之外,還需要輸入控制訊號標記
效果對比如下
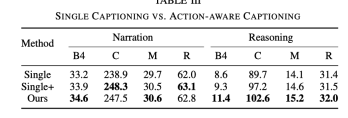
#相比只有DCG任務,ADAPT的Reasoning效果明顯更好。雖然有控制訊號輸入時效果有提升,但仍不如加入CSP任務的效果好。加入CSP任務後,對影片的表示和理解能力更強
另外下面這個表格也說明了聯合訓練對於CSP的效果也是有提升的.

這裡 可以理解為精確度, 這樣會把預測的控制訊號做一個截斷,公式如下
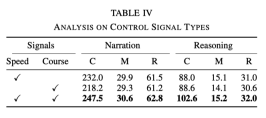
不同型別控制訊號的影響
在實驗中,使用的基礎訊號有速度和航向。然而,實驗發現,當只使用其中任何一個訊號時,效果都不如同時使用兩個訊號的效果好,具體數據如下表所示:
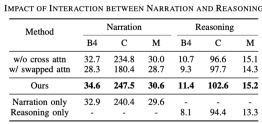
動作描述與推理之間的交互
與一般描述任務相比,駕駛描述任務產生是兩個句子,即動作描述和推理。透過下表可以發現:- 第1,3行說明使用cross attention效果要更好一些, 這也好理解, 基於描述來做推理有利於模型的訓練;
- 第2,3行說明交換推理和描述的順序也會掉點, 這說明了推理是依賴於描述的;
- 後面三行對比來看, 只輸出描述和只輸出推理都不如二者都輸出的時候效果好;
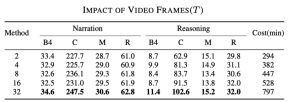
#Sampling Rates 的影響##這個結果是可以猜到的, 使用的幀越多,結果越好,但是對應的速度也會變慢, 如下表所示
 需要重寫的內容是:原文連結:https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
需要重寫的內容是:原文連結:https://mp.weixin.qq.com/s/MSTyr4ksh0TOqTdQ2WnSeQ
以上是新標題:ADAPT:端到端自動駕駛可解釋性的初步探索的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM
SOA中的软件架构设计及软硬件解耦方法论Apr 08, 2023 pm 11:21 PM对于下一代集中式电子电器架构而言,采用central+zonal 中央计算单元与区域控制器布局已经成为各主机厂或者tier1玩家的必争选项,关于中央计算单元的架构方式,有三种方式:分离SOC、硬件隔离、软件虚拟化。集中式中央计算单元将整合自动驾驶,智能座舱和车辆控制三大域的核心业务功能,标准化的区域控制器主要有三个职责:电力分配、数据服务、区域网关。因此,中央计算单元将会集成一个高吞吐量的以太网交换机。随着整车集成化的程度越来越高,越来越多ECU的功能将会慢慢的被吸收到区域控制器当中。而平台化
 新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM
新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM新视角图像生成(NVS)是计算机视觉的一个应用领域,在1998年SuperBowl的比赛,CMU的RI曾展示过给定多摄像头立体视觉(MVS)的NVS,当时这个技术曾转让给美国一家体育电视台,但最终没有商业化;英国BBC广播公司为此做过研发投入,但是没有真正产品化。在基于图像渲染(IBR)领域,NVS应用有一个分支,即基于深度图像的渲染(DBIR)。另外,在2010年曾很火的3D TV,也是需要从单目视频中得到双目立体,但是由于技术的不成熟,最终没有流行起来。当时基于机器学习的方法已经开始研究,比
 如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM
如何让自动驾驶汽车“认得路”Apr 09, 2023 pm 01:41 PM与人类行走一样,自动驾驶汽车想要完成出行过程也需要有独立思考,可以对交通环境进行判断、决策的能力。随着高级辅助驾驶系统技术的提升,驾驶员驾驶汽车的安全性不断提高,驾驶员参与驾驶决策的程度也逐渐降低,自动驾驶离我们越来越近。自动驾驶汽车又称为无人驾驶车,其本质就是高智能机器人,可以仅需要驾驶员辅助或完全不需要驾驶员操作即可完成出行行为的高智能机器人。自动驾驶主要通过感知层、决策层及执行层来实现,作为自动化载具,自动驾驶汽车可以通过加装的雷达(毫米波雷达、激光雷达)、车载摄像头、全球导航卫星系统(G
 多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM
多无人机协同3D打印盖房子,研究登上Nature封面Apr 09, 2023 am 11:51 AM我们经常可以看到蜜蜂、蚂蚁等各种动物忙碌地筑巢。经过自然选择,它们的工作效率高到叹为观止这些动物的分工合作能力已经「传给」了无人机,来自英国帝国理工学院的一项研究向我们展示了未来的方向,就像这样:无人机 3D 打灰:本周三,这一研究成果登上了《自然》封面。论文地址:https://www.nature.com/articles/s41586-022-04988-4为了展示无人机的能力,研究人员使用泡沫和一种特殊的轻质水泥材料,建造了高度从 0.18 米到 2.05 米不等的结构。与预想的原始蓝图
 超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM
超逼真渲染!虚幻引擎技术大牛解读全局光照系统LumenApr 08, 2023 pm 10:21 PM实时全局光照(Real-time GI)一直是计算机图形学的圣杯。多年来,业界也提出多种方法来解决这个问题。常用的方法包通过利用某些假设来约束问题域,比如静态几何,粗糙的场景表示或者追踪粗糙探针,以及在两者之间插值照明。在虚幻引擎中,全局光照和反射系统Lumen这一技术便是由Krzysztof Narkowicz和Daniel Wright一起创立的。目标是构建一个与前人不同的方案,能够实现统一照明,以及类似烘烤一样的照明质量。近期,在SIGGRAPH 2022上,Krzysztof Narko
 internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PM
internet的基本结构与技术起源于什么Dec 15, 2020 pm 04:48 PMinternet的基本结构与技术起源于ARPANET。ARPANET是计算机网络技术发展中的一个里程碑,它的研究成果对促进网络技术的发展起到了重要的作用,并未internet的形成奠定了基础。arpanet(阿帕网)为美国国防部高级研究计划署开发的世界上第一个运营的封包交换网络,它是全球互联网的始祖。
 一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM
一文聊聊智能驾驶系统与软件升级的关联设计方案Apr 11, 2023 pm 07:49 PM由于智能汽车集中化趋势,导致在网络连接上已经由传统的低带宽Can网络升级转换到高带宽以太网网络为主的升级过程。为了提升车辆升级能力,基于为车主提供持续且优质的体验和服务,需要在现有系统基础(由原始只对车机上传统的 ECU 进行升级,转换到实现以太网增量升级的过程)之上开发一套可兼容现有 OTA 系统的全新 OTA 服务系统,实现对整车软件、固件、服务的 OTA 升级能力,从而最终提升用户的使用体验和服务体验。软件升级触及的两大领域-FOTA/SOTA整车软件升级是通过OTA技术,是对车载娱乐、导
 综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PM
综述:自动驾驶的协同感知技术Apr 08, 2023 pm 03:01 PMarXiv综述论文“Collaborative Perception for Autonomous Driving: Current Status and Future Trend“,2022年8月23日,上海交大。感知是自主驾驶系统的关键模块之一,然而单车的有限能力造成感知性能提高的瓶颈。为了突破单个感知的限制,提出协同感知,使车辆能够共享信息,感知视线之外和视野以外的环境。本文回顾了很有前途的协同感知技术相关工作,包括基本概念、协同模式以及关键要素和应用。最后,讨论该研究领域的开放挑战和问题


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3 Linux新版
SublimeText3 Linux最新版

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

