
統一影像與文字生成的MiniGPT-5來了:Token變Voken,模型不僅能續寫,還會自動配圖了

- 王林轉載
- 2023-10-11 12:45:031117瀏覽
大型模型正在實現語言和視覺之間的跨越,預計將無縫地理解和生成文字和圖像內容。在最近的一系列研究中,多模態特徵整合不僅是一個不斷發展的趨勢,而且已經帶來了從多模態對話到內容創建工具等關鍵進步。大型語言模型在文本理解和生成方面已經展現出無與倫比的能力。然而,同時產生具有連貫文本敘述的圖像仍然是一個有待發展的領域
近日,加州大學聖克魯茲分校的研究團隊提出了MiniGPT-5,這是一種以「生成式voken」概念為基礎的創新交錯視覺語言生成技術。

- #論文網址:https://browse.arxiv.org/pdf /2310.02239v1.pdf
- #專案網址:https://github.com/eric-ai-lab/MiniGPT-5
#透過特殊的視覺token「生成式voken」,將穩定擴散機制與LLM結合,MiniGPT-5為熟練的多模態生成預示了一種新模式。同時,本文提出的兩階段訓練方法強調了無描述基礎階段的重要性,使模型在資料稀缺的情況下也能茁壯成長。此方法的通用階段不需要特定領域的註釋,這使得本文解決方案與現有的方法截然不同。為了確保生成的文本和圖像和諧一致,本文的雙損失策略開始發揮作用,生成式voken方法和分類方法進一步增強了這一效果
在這些技術的基礎上,這項工作標誌著一種變革性的方法。研究團隊透過使用ViT(Vision Transformer)和Qformer以及大型語言模型,將多模態輸入轉換為生成式voken,並與高解析度的Stable Diffusion2.1無縫配對,以實現上下文感知圖像生成。本文將圖像作為輔助輸入與指令調整方法相結合,並率先採用文字和圖像生成損失,從而擴大了文本和視覺之間的協同作用
MiniGPT-5 與CLIP約束等模型相匹配,巧妙地將擴散模型與MiniGPT-4 融合在一起,在不依賴特定領域註釋的情況下實現了較好的多模態結果。最重要的是,本文的策略可以利用多模態視覺語言基礎模型的進步,為增強多模態生成能力提供新藍圖。
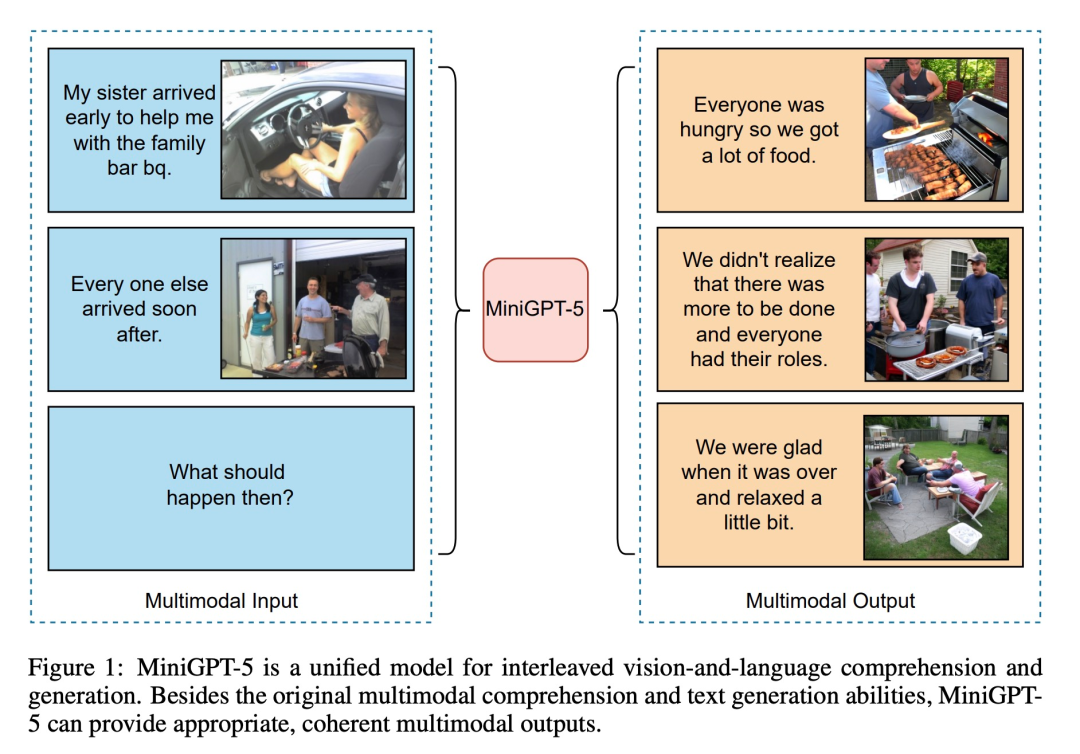
如下圖所示,除了原有的多模態理解和文本生成能力外,MiniGPT5 還能提供合理、連貫的多模態輸出:
本文貢獻體現在三個面向:
- #建議使用多模態編碼器,它代表了一種新穎的通用技術,並已被證明比LLM 和反轉生成式vokens 更有效,並將其與Stable Diffusion 相結合,產生交錯的視覺和語言輸出(可進行多模態生成的多模態語言模型)。
- 重點介紹了一種新的兩階段訓練策略,用於無描述多模態生成。單模態對齊階段從大量文字影像對中獲取高品質的文字對齊視覺特徵。多模態學習階段包括一項新穎的訓練任務,即 prompt 語境生成,確保視覺和文字 prompt 能夠很好地協調生成。在訓練階段加入無分類器指導,進一步提高了生成品質。
- 與其他多模態生成模型相比, MiniGPT-5 在 CC3M 資料集上取得了最先進的效能。 MiniGPT-5 也在 VIST 和 MMDialog 等著名資料集上建立了新的基準。
現在,讓我們一起來詳細了解這項研究的內容
方法概覽
#為了讓大型語言模型具備多模態生成能力,研究者引入了一個結構化框架,將預先訓練好的多模態大型語言模型和文字到圖像生成模型整合在一起。為了解決不同模型領域之間的差異,他們引入了特殊的視覺符號「生成式 voken」(generative vokens),能夠直接在原始影像上進行訓練。此外,還推進了兩階段訓練方法,並結合無分類器引導策略,以進一步提高生成品質。
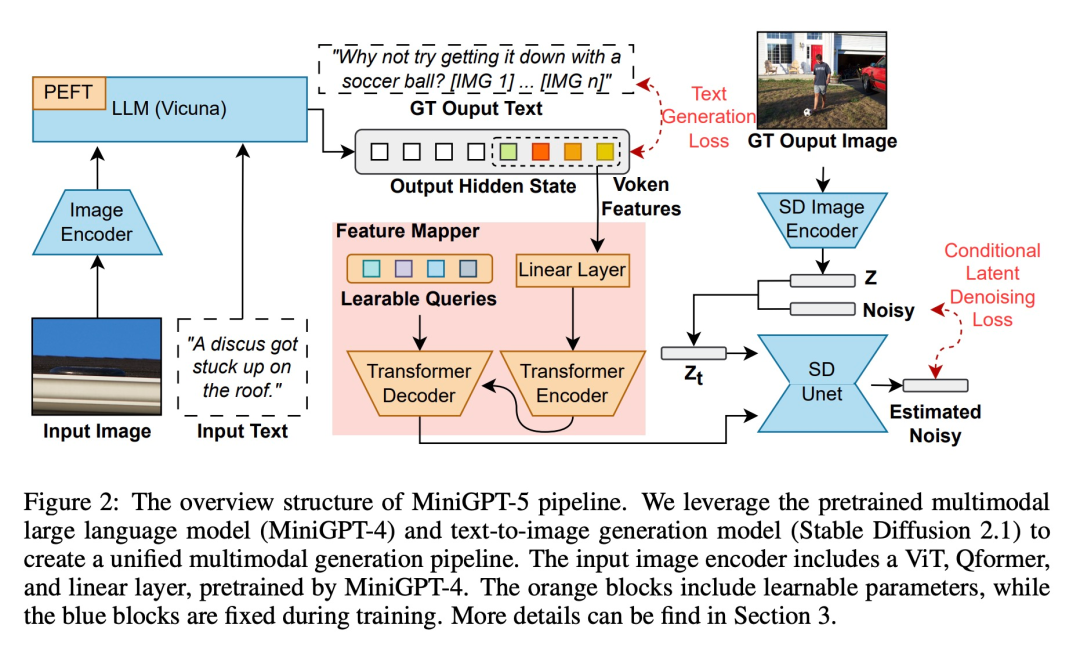
多模態輸入階段
多模態大模型(如MiniGPT-4)的最新進展主要集中在多模態理解方面,能夠處理作為連續輸入的影像。為了將其功能擴展到多模態生成,研究者引入了專為輸出視覺特徵而設計的生成式 vokens。此外,他們還在大語言模型(LLM)框架內採用了參數效率高的微調技術,用於多模態輸出學習
多模態輸出生成
為了確保生成式token 與生成模型精確對齊,研究人員開發了一個緊湊型映射模組,用於維度匹配,並引入了幾個監督損失,包括文本空間損失和潛在擴散模型損失。文字空間損失有助於模型準確學習 token 的位置,而潛在擴散損失則直接將 token 與適當的視覺特徵對齊。由於生成式符號的特徵直接由圖像引導,因此此方法無需完整的圖像描述,實現了無描述學習
訓練策略
#鑑於文字域和圖像域之間存在不可忽略的領域偏移,研究者發現直接在有限的文字和圖像交錯資料集上進行訓練可能會導致錯位和影像品質下降。
因此,他們採用了兩種不同的訓練策略來緩解這個問題。第一種策略包括採用無分類器引導技術,在整個擴散過程中提高生成token 的有效性;第二種策略分兩個階段展開:最初的預訓練階段側重於粗略的特徵對齊,隨後的微調階段致力於複雜的特徵學習。
實驗及結果
為了評估模型的效果,研究人員選擇了多個基準進行了一系列評估。實驗的目的是解決幾個關鍵問題:
- MiniGPT-5 能否產生可信賴的圖像和合理的文字?
- 在單輪和多輪交錯視覺語言生成任務中,MiniGPT-5 與其他 SOTA 模型相比表現如何?
- 每個模組的設計對整體效能有什麼影響?
為了評估MiniGPT-5模型在不同訓練階段上的表現,我們進行了定量分析,結果如圖3所示:

為了展示所提模型的通用性和穩健性,我們對其進行了評估,涵蓋了視覺(圖像相關指標)和語言(文本指標)兩個領域
VIST Final-Step 評估
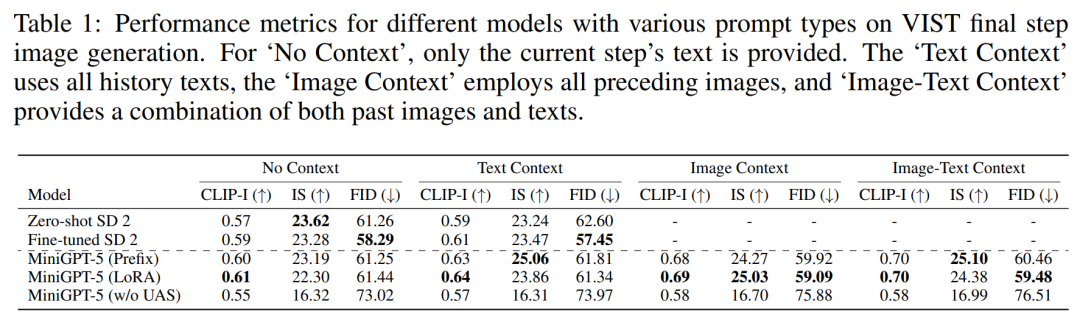
#第一組實驗涉及單步評估,即根據最後一步的prompt 模型產生對應的影像,結果如表1 所示。
在所有三種設定中,MiniGPT-5的效能都優於微調後的SD 2。值得注意的是,MiniGPT-5(LoRA)模型的CLIP得分在多種prompt類型中始終優於其他變體,尤其是在結合影像和文字prompt時。另一方面,FID分數凸顯了MiniGPT-5(前綴)模型的競爭力,顯示影像嵌入品質(由CLIP分數反映)與影像的多樣性和真實性(由FID分數反映)之間可能存在權衡。與直接在VIST上進行訓練而不包含單模態配準階段的模型(MiniGPT-5 w/o UAS)相比,雖然該模型保留了生成有意義圖像的能力,但圖像品質和一致性明顯下降。這項觀察結果凸顯了兩階段訓練策略的重要性
#VIST Multi-Step 評估
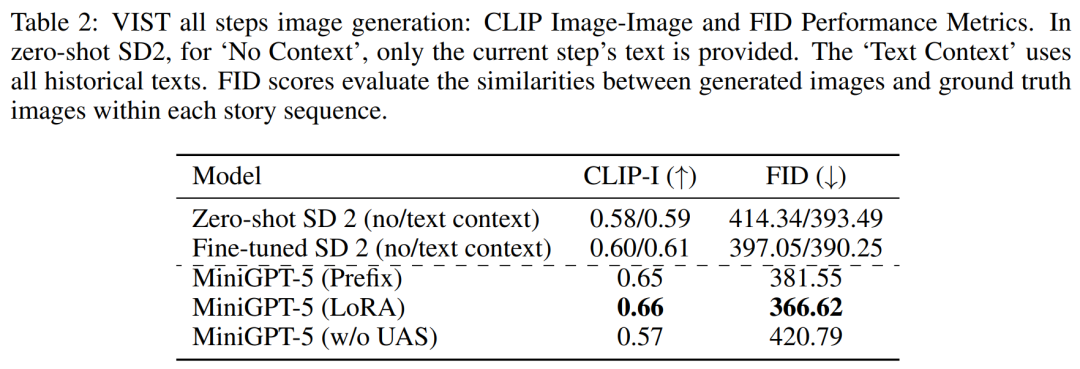
在更詳細、更全面的評估中,研究者係統性地為模型提供了先前的歷史背景,並隨後在每個步驟中對生成的圖像和敘述進行評估。
表2和表3總結了這些實驗的結果,分別概述了圖像和語言指標的表現。實驗結果表明,MiniGPT-5能夠利用長水平多模態輸入提示在所有數據中產生連貫、高品質的圖像,而不會影響原始模型的多模態理解能力。這突顯了MiniGPT-5在不同環境中的有效性

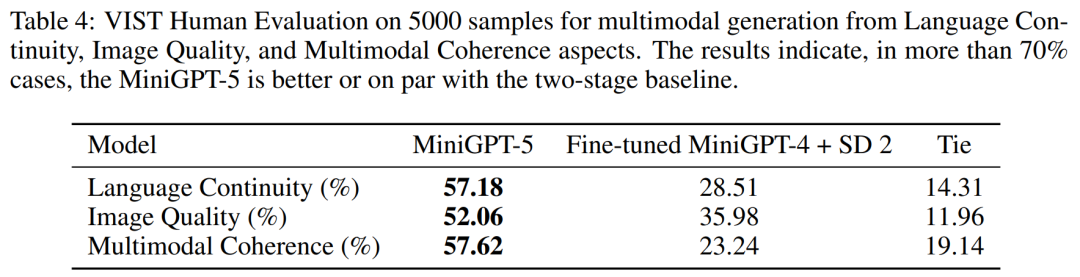
VIST 人類評估
#如表4 所示,MiniGPT-5 在57.18% 的情況下生成了更貼切的文本敘述,在52.06% 的情況下提供了更出色的圖像質量,在57.62% 的場景中產生了更連貫的多模態輸出。與採用文字到圖像 prompt 敘述而不包含虛擬語氣的兩階段基線相比,這些數據明顯展示了其更強的多模態生成能力。
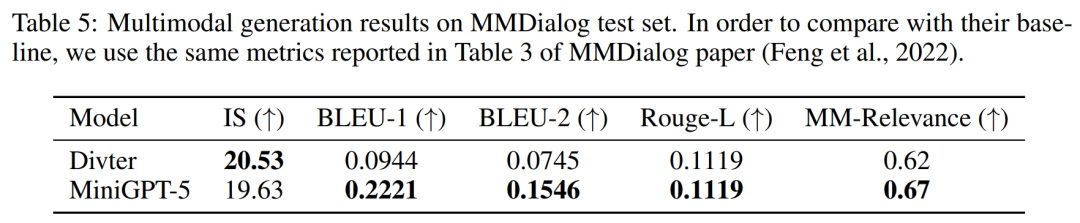
MMDialog 多輪評估
根據表5的結果顯示,MiniGPT-5在產生文字回覆方面比基線模型Divter更準確。儘管生成的影像品質相似,但與基準模型相比,MiniGPT-5在MM相關性方面更出色,這表明它能夠更好地學習如何適當地定位影像生成,並產生高度一致的多模態反應
我們來看看MiniGPT-5 的輸出結果,看看它的效果如何。下圖7 展示了MiniGPT-5 在CC3M 驗證集上與基準模型的比較

下圖8展示了MiniGPT-5與VIST驗證集上基準模型的比較

#下圖9 為MiniGPT-5 與MMDialog 測試集上基線模型的比較。

更多研究細節,可參考原文。
以上是統一影像與文字生成的MiniGPT-5來了:Token變Voken,模型不僅能續寫,還會自動配圖了的詳細內容。更多資訊請關注PHP中文網其他相關文章!