




目前,在自動駕駛的車輛中已經配備了多種資訊擷取感測器,如雷射雷達、毫米波雷達以及相機感測器。從目前來看,多種感測器在自動駕駛的感知任務中顯示出了巨大的發展前景。例如,相機採集到的2D影像資訊捕捉了豐富的語義特徵,雷射雷達收集到的點雲資料可以為感知模型提供物體的準確位置資訊和幾何資訊。透過充分利用不同感測器所獲得的信息,可以減少自動駕駛感知過程中的不確定性因素的發生,同時提升感知模型的檢測魯棒性
今天介紹的是一篇來自曠視的自動駕駛感知論文,並且中稿了今年的ICCV2023 視覺頂會,該文章的主要特點是類似PETR這類End-to-End的BEV感知演算法(不再需要利用NMS後處理操作過濾感知結果中的冗餘餘框),同時又額外使用了雷射雷達的點雲資訊來提高模型的感知性能,是一篇非常不錯的自動駕駛感知方向的論文,文章的連結和官方開源倉庫連結如下:
- 論文連結:https://arxiv.org/pdf/2301.01283.pdf
- 程式碼連結:https://github.com/junjie18/CMT
#CMT演算法模型整體結構
接下來,我們將對CMT感知模型的網路結構進行整體介紹,如下圖所示:
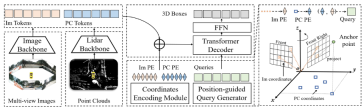
透過整個演算法框圖可以看出,整個演算法模型主要包括三個部分
- 雷射雷達主幹網路相機主幹網路(Image Backbone Lidar Backbone):用於取得點雲和環視圖像的特徵得到Point Cloud Token**(PC Tokens)以及Image Token(Im Tokens)**
- 位置編碼的產生:針對不同感測器收集到的資料訊息,Im Tokens產生對應的座標位置編碼Im PE,PC Tokens產生對應的座標位置編碼PC PE,同時Object Queries也產生對應的座標位置編碼查詢嵌入
- Transformer Decoder FFN網路:輸入為Object Queries 查詢嵌入 以及完成位置編碼的Im Tokens和PC Tokens進行交叉注意力的計算,利用FFN產生最終的3D Boxes 類別預測
在詳細介紹了網路的整體結構之後,接下來將詳細介紹上述提到的三個子部分
雷射雷達主幹網路相機主幹網路(Image Backbone Lidar Backbone)
- 雷射雷達主幹網路
通常所採用的光達主幹網路擷取點雲資料特徵包括以下五個部分
- 點雲資訊體素化
- #體素特徵編碼
- # 3D Backbone(常用VoxelResBackBone8x網路)對體素特徵編碼後的結果進行3D特徵的提取
- 將3D Backbone提取到特徵的Z軸進行壓縮,得到BEV空間下的特徵
- #利用2D Backbone對投影到BEV空間的特徵做進一步的特徵擬合
- 由於2D Backbone輸出的特徵圖的通道數與Image輸出的通道數不一致,用了一個卷積層進行通道數的對齊(針對本文模型而言,做了一個通道數量的對齊,但並不屬於原有點雲資訊提取的範疇)
- 相機主幹網路
一般採用的相機主幹網路提取2D影像特徵包括以下兩個部分: #輸入:2D Backbone輸出的降採樣16倍和32倍的特徵圖
輸出:將下取樣16倍和32倍的影像特徵進行融合,取得降採樣16倍的特徵圖
Tensor([bs * N, 1024, H / 16 , W / 16])Tensor([bs * N,2048,H / 16,W / 16])需要重新寫的內容是:張量([bs * N,256,H / 16,W / 16])重寫內容:使用ResNet-50網路來擷取環視圖像的特徵
#輸出:輸出下取樣16倍和32倍的影像特徵
輸入張量:
Tensor([bs * N,3,H,W])- ##輸出張量:
Tensor([bs * N,1024,H / 16,W / 16])
- 輸出張量:``Tensor([bs * N,2048, H / 32,W / 32])`
- 需要進行改寫的內容是:2D骨架擷取影像特徵
- Neck(CEFPN)
- Image Position Embedding(Im PE)
- Image Position Embedding的生成過程與PETR中圖像位置編碼的生成邏輯是一樣的(具體可以參考PETR論文原文,這裡不做過多的闡述),可以總結為以下四個步驟:
- 在圖像座標系下產生3D圖像視錐點雲
- # 3D影像視錐點雲利用相機內參矩陣變換到相機座標系下得到3D相機座標點
- #相機座標系下的3D點利用cam2ego座標變換矩陣轉換到BEV座標系下
- 將轉換後的BEV 3D 座標利用MLP層進行位置編碼得到最終的影像位置編碼
- Point Cloud Position Embedding(PC PE)
- Point Cloud Position Embedding的產生過程可以分為以下兩個步驟
-
在BEV空間的網格座標點利用#pos2embed()
函數將二維的橫縱座標點轉換到高維度的特徵空間# 点云位置编码`bev_pos_embeds`的生成bev_pos_embeds = self.bev_embedding(pos2embed(self.coords_bev.to(device), num_pos_feats=self.hidden_dim))def coords_bev(self):x_size, y_size = (grid_size[0] // downsample_scale,grid_size[1] // downsample_scale)meshgrid = [[0, y_size - 1, y_size], [0, x_size - 1, x_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = (batch_x + 0.5) / x_sizebatch_y = (batch_y + 0.5) / y_sizecoord_base = torch.cat([batch_x[None], batch_y[None]], dim=0) # 生成BEV网格.coord_base = coord_base.view(2, -1).transpose(1, 0)return coord_base# shape: (x_size *y_size, 2)def pos2embed(pos, num_pos_feats=256, temperature=10000):scale = 2 * math.pipos = pos * scaledim_t = torch.arange(num_pos_feats, dtype=torch.float32, device=pos.device)dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)pos_x = pos[..., 0, None] / dim_tpos_y = pos[..., 1, None] / dim_tpos_x = torch.stack((pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()), dim=-1).flatten(-2)pos_y = torch.stack((pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()), dim=-1).flatten(-2)posemb = torch.cat((pos_y, pos_x), dim=-1)return posemb# 将二维的x,y坐标编码成512维的高维向量
-
#透過使用多層感知器(MLP)網絡進行空間轉換,確保通道數的對齊
-
#查詢嵌入
#為了讓Object Queries、Image Token以及Lidar Token之間計算相似性更加的準確,論文中的查詢嵌入會利用Lidar和Camera生成位置編碼的邏輯來產生;具體而言查詢嵌入= Image Position Embedding(同下面的rv_query_embeds) Point Cloud Position Embedding(同下面的bev_query_embeds)。 -
bev_query_embeds產生邏輯
因為論文中的Object Query原本是BEV空間進行初始化的,所以直接重複使用Point Cloud Position Embedding產生邏輯中的位置編碼和bev_embedding()函數即可,對應關鍵程式碼如下:def _bev_query_embed(self, ref_points, img_metas):bev_embeds = self.bev_embedding(pos2embed(ref_points, num_pos_feats=self.hidden_dim))return bev_embeds# (bs, Num, 256)
-
rv_query_embeds產生邏輯需要重新寫
#在前面提到的內容中,Object Query是在BEV座標系下的初始點。為了遵循Image Position Embedding的生成過程,論文中需要先將BEV座標系下的3D空間點投影到影像座標系下,然後再利用先前產生Image Position Embedding的處理邏輯,以確保生成過程的邏輯相同。以下是核心程式碼:def _rv_query_embed(self, ref_points, img_metas):pad_h, pad_w = pad_shape# 由归一化坐标点映射回正常的roi range下的3D坐标点ref_points = ref_points * (pc_range[3:] - pc_range[:3]) + pc_range[:3]points = torch.cat([ref_points, ref_points.shape[:-1]], dim=-1)points = bda_mat.inverse().matmul(points)points = points.unsqueeze(1)points = sensor2ego_mats.inverse().matmul(points)points =intrin_mats.matmul(points)proj_points_clone = points.clone() # 选择有效的投影点z_mask = proj_points_clone[..., 2:3, :].detach() > 0proj_points_clone[..., :3, :] = points[..., :3, :] / (points[..., 2:3, :].detach() + z_mask * 1e-6 - (~z_mask) * 1e-6)proj_points_clone = ida_mats.matmul(proj_points_clone)proj_points_clone = proj_points_clone.squeeze(-1)mask = ((proj_points_clone[..., 0] = 0)& (proj_points_clone[..., 1] = 0))mask &= z_mask.view(*mask.shape)coords_d = (1 + torch.arange(depth_num).float() * (pc_range[4] - 1) / depth_num)projback_points = (ida_mats.inverse().matmul(proj_points_clone))projback_points = torch.einsum("bvnc, d -> bvndc", projback_points, coords_d)projback_points = torch.cat([projback_points[..., :3], projback_points.shape[:-1]], dim=-1)projback_points = (sensor2ego_mats.matmul(intrin_mats).matmul(projback_points))projback_points = (bda_mat@ projback_points)projback_points = (projback_points[..., :3] - pc_range[:3]) / (pc_range[3:] - self.pc_range[:3])rv_embeds = self.rv_embedding(projback_points)rv_embeds = (rv_embeds * mask).sum(dim=1)return rv_embeds透過上述的變換,即完成了BEV空間座標系下的點先投影到影像座標系,再利用先前產生Image Position Embedding的處理邏輯產生rv_query_embeds的過程。 最後查詢嵌入 = rv_query_embeds bev_query_embeds
#
Transformer Decoder FFN網路
- Transformer Decoder
這裡與Transformer中的Decoder運算邏輯是完全一樣的,但在輸入資料上有點不同
- 第一點是Memory:這裡的Memory是Image Token和Lidar Token進行Concat後的結果(可以理解為兩個模態的融
- 第二點是位置編碼:這裡的位置編碼是rv_query_embeds和bev_query_embeds進行concat的結果,query_embed是rv_query_embeds bev_query_embeds;
- ##FFN
- #這個FFN網路的作用與PETR中的作用是完全相同PETR中的作用是完全相同PETR中的作用是完全相同PETR中的作用是完全相同PETR中的作用是完全相同PETR中的作用是完全相同PETR中的作用是完全相同PETR中的作用是與PETR中的作用是完全相同的,具體的輸出結果可以看PETR原文,這裡就不做過多的贅述了。
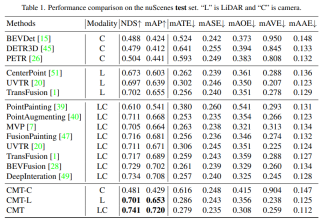
論文實驗結果##先放出來CMT和其他自動駕駛感知演算法的比較實驗,論文作者分別在nuScenes的test和val集上進行了比較,實驗結果如下
各個感知演算法在nuScenes的test set上的感知結果對比- 表格中的Modality代表輸入到感知演算法中的感測器類別,C代表相機感測器,模型只餵入相機資料。L代表雷射雷達感測器,模型只餵入點雲資料。LC代表雷射雷達和相機感測器,模型輸入的是多模態的資料。透過實驗結果可以看出,CMT-C模型的性能高於BEVDet和DETR3D。CMT-L模型的性能要高於CenterPoint和UVTR這類純雷射雷達的感知演算法模型。而當CMT採用光達的點雲資料和相機資料後超越了現有的所有單模態方法,得到了SOTA的結果。
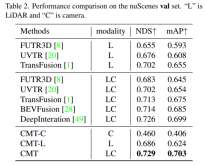
- 透過實驗結果可以看出,CMT-L的感知模型的性能超越了FUTR3D和UVTR。當同時採用雷射雷達的點雲數據和相機資料後,CMT較大幅度超越了現有的採用多模態的感知演算法,像FUTR3D、UVTR、TransFusion、BEVFusion等多模態演算法,取得了val set上的SOTA結果。
 接下來是CMT創新點的消融實驗部分
接下來是CMT創新點的消融實驗部分
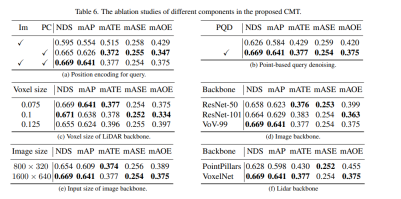 #首先,我們進行了一系列消融實驗,來確定是否採用位置編碼。透過實驗結果發現,當同時採用影像和雷射雷達的位置編碼時,NDS和mAP指標實現了最佳效果。接下來,在消融實驗的(c)和(f)部分,我們對點雲主幹網路的類型和體素大小進行了不同的嘗試。而在(d)和(e)部分的消融實驗中,我們則對相機主幹網路的類型和輸入解析度的大小進行了不同的嘗試。以上只是對實驗內容的簡要概括,如需了解更多詳細的消融實驗,請參閱原文
#首先,我們進行了一系列消融實驗,來確定是否採用位置編碼。透過實驗結果發現,當同時採用影像和雷射雷達的位置編碼時,NDS和mAP指標實現了最佳效果。接下來,在消融實驗的(c)和(f)部分,我們對點雲主幹網路的類型和體素大小進行了不同的嘗試。而在(d)和(e)部分的消融實驗中,我們則對相機主幹網路的類型和輸入解析度的大小進行了不同的嘗試。以上只是對實驗內容的簡要概括,如需了解更多詳細的消融實驗,請參閱原文
最後放一張CMT的感知結果在nuScenes數據集上可視化結果的展示,通過實驗結果可以看出,CMT還是有較好的感知結果的。

目前,將各種模態融合在一起以提升模型的感知性能已經成為一個熱門的研究方向(尤其是在自動駕駛汽車上,配備了多種感測器)。同時,CMT是一個完全端到端的感知演算法,不需要額外的後處理步驟,並且在nuScenes資料集上具有最先進的精確度。本文對這篇文章進行了詳細介紹,希望對大家有幫助
需要重寫的內容是: 原文連結:https://mp.weixin.qq.com/s/Fx7dkv8f2ibkfO66-5hEXA
以上是跨模態Transformer:面向快速穩健的3D目標偵測的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM
从VAE到扩散模型:一文解读以文生图新范式Apr 08, 2023 pm 08:41 PM1 前言在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至
 找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PM
找不到中文语音预训练模型?中文版 Wav2vec 2.0和HuBERT来了Apr 08, 2023 pm 06:21 PMWav2vec 2.0 [1],HuBERT [2] 和 WavLM [3] 等语音预训练模型,通过在多达上万小时的无标注语音数据(如 Libri-light )上的自监督学习,显著提升了自动语音识别(Automatic Speech Recognition, ASR),语音合成(Text-to-speech, TTS)和语音转换(Voice Conversation,VC)等语音下游任务的性能。然而这些模型都没有公开的中文版本,不便于应用在中文语音研究场景。 WenetSpeech [4] 是
 普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM
普林斯顿陈丹琦:如何让「大模型」变小Apr 08, 2023 pm 04:01 PM“Making large models smaller”这是很多语言模型研究人员的学术追求,针对大模型昂贵的环境和训练成本,陈丹琦在智源大会青源学术年会上做了题为“Making large models smaller”的特邀报告。报告中重点提及了基于记忆增强的TRIME算法和基于粗细粒度联合剪枝和逐层蒸馏的CofiPruning算法。前者能够在不改变模型结构的基础上兼顾语言模型困惑度和检索速度方面的优势;而后者可以在保证下游任务准确度的同时实现更快的处理速度,具有更小的模型结构。陈丹琦 普
 解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM
解锁CNN和Transformer正确结合方法,字节跳动提出有效的下一代视觉TransformerApr 09, 2023 pm 02:01 PM由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?近期一些工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。基于此,来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer——Next-ViT。从延迟 / 准确性权衡的角度看,
 Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM
Stable Diffusion XL 现已推出—有什么新功能,你知道吗?Apr 07, 2023 pm 11:21 PM3月27号,Stability AI的创始人兼首席执行官Emad Mostaque在一条推文中宣布,Stable Diffusion XL 现已可用于公开测试。以下是一些事项:“XL”不是这个新的AI模型的官方名称。一旦发布稳定性AI公司的官方公告,名称将会更改。与先前版本相比,图像质量有所提高与先前版本相比,图像生成速度大大加快。示例图像让我们看看新旧AI模型在结果上的差异。Prompt: Luxury sports car with aerodynamic curves, shot in a
 什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM
什么是Transformer机器学习模型?Apr 08, 2023 pm 06:31 PM译者 | 李睿审校 | 孙淑娟近年来, Transformer 机器学习模型已经成为深度学习和深度神经网络技术进步的主要亮点之一。它主要用于自然语言处理中的高级应用。谷歌正在使用它来增强其搜索引擎结果。OpenAI 使用 Transformer 创建了著名的 GPT-2和 GPT-3模型。自从2017年首次亮相以来,Transformer 架构不断发展并扩展到多种不同的变体,从语言任务扩展到其他领域。它们已被用于时间序列预测。它们是 DeepMind 的蛋白质结构预测模型 AlphaFold
 五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM
五年后AI所需算力超100万倍!十二家机构联合发表88页长文:「智能计算」是解药Apr 09, 2023 pm 07:01 PM人工智能就是一个「拼财力」的行业,如果没有高性能计算设备,别说开发基础模型,就连微调模型都做不到。但如果只靠拼硬件,单靠当前计算性能的发展速度,迟早有一天无法满足日益膨胀的需求,所以还需要配套的软件来协调统筹计算能力,这时候就需要用到「智能计算」技术。最近,来自之江实验室、中国工程院、国防科技大学、浙江大学等多达十二个国内外研究机构共同发表了一篇论文,首次对智能计算领域进行了全面的调研,涵盖了理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。论文链接:https://spj.scien
 AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM
AI模型告诉你,为啥巴西最可能在今年夺冠!曾精准预测前两届冠军Apr 09, 2023 pm 01:51 PM说起2010年南非世界杯的最大网红,一定非「章鱼保罗」莫属!这只位于德国海洋生物中心的神奇章鱼,不仅成功预测了德国队全部七场比赛的结果,还顺利地选出了最终的总冠军西班牙队。不幸的是,保罗已经永远地离开了我们,但它的「遗产」却在人们预测足球比赛结果的尝试中持续存在。在艾伦图灵研究所(The Alan Turing Institute),随着2022年卡塔尔世界杯的持续进行,三位研究员Nick Barlow、Jack Roberts和Ryan Chan决定用一种AI算法预测今年的冠军归属。预测模型图


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

Dreamweaver CS6
視覺化網頁開發工具

WebStorm Mac版
好用的JavaScript開發工具

