
ICCV 2023宣布ControlNet與「分割一切」等熱門論文獲獎

- 王林轉載
- 2023-10-05 21:17:03868瀏覽
本週,國際電腦視覺大會 ICCV(International Conference on Computer Vision)在法國巴黎開幕。

作為全球電腦視覺領域頂尖的學術會議,ICCV 每兩年召開一次。
和 CVPR 一樣,ICCV 的熱度屢創新高。
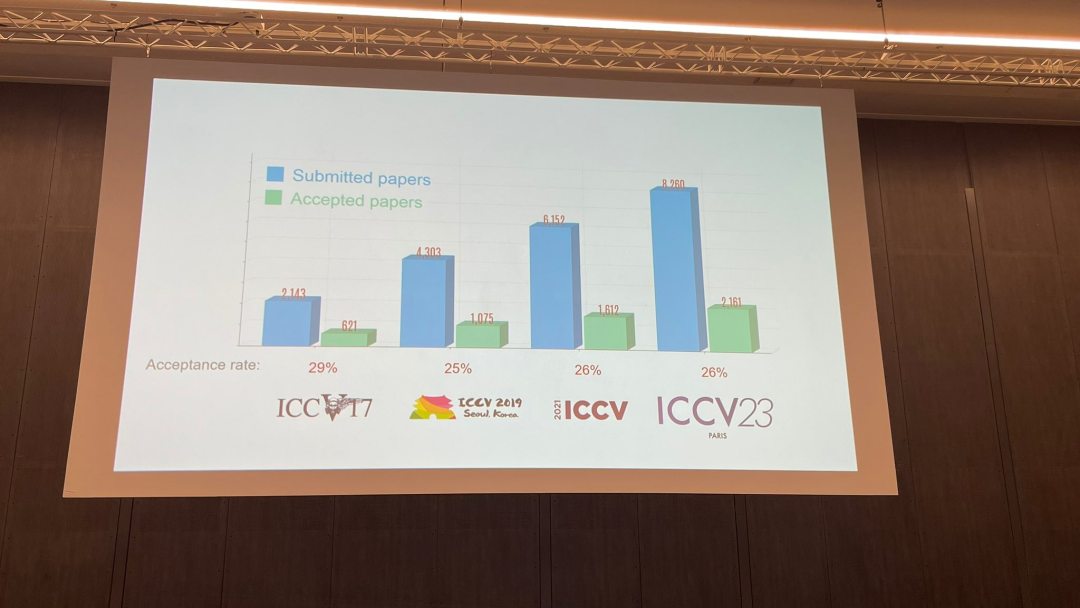
在今天的開幕式上,ICCV 官方公佈了今年的論文數據:本屆ICCV 投稿總數達到8068 篇,其中有2160 篇被接收,錄用率為26.8%,略高於上一屆ICCV 2021 的錄用率25.9%
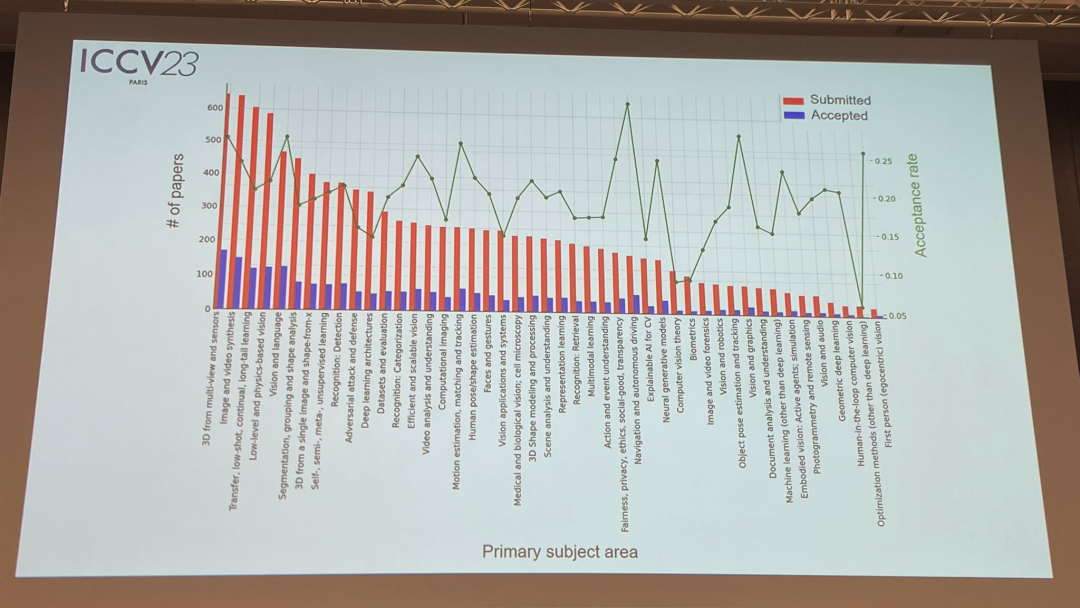
關於論文主題,官方也發布了相關數據:多重視角和感測器的3D技術熱度最高
在今天的開幕式上,最重要的部分是宣布獲獎資訊。現在,讓我們逐一揭曉最佳論文、最佳論文提名和最佳學生論文
最佳論文- 馬爾獎
共有兩篇論文獲得今年的最佳論文(馬爾獎)。
第一篇來自多倫多大學的研究者。

- #論文網址:https://openaccess.thecvf.com/content/ICCV2023/ papers/Wei_Passive_Ultra-Wideband_Single-Photon_Imaging_ICCV_2023_paper.pdf
- 作者:Mian Wei、Sotiris Nousias、Rahul Gulve、David B. Lindell、Kirilakakos N. Kutu #機構:多倫多大學
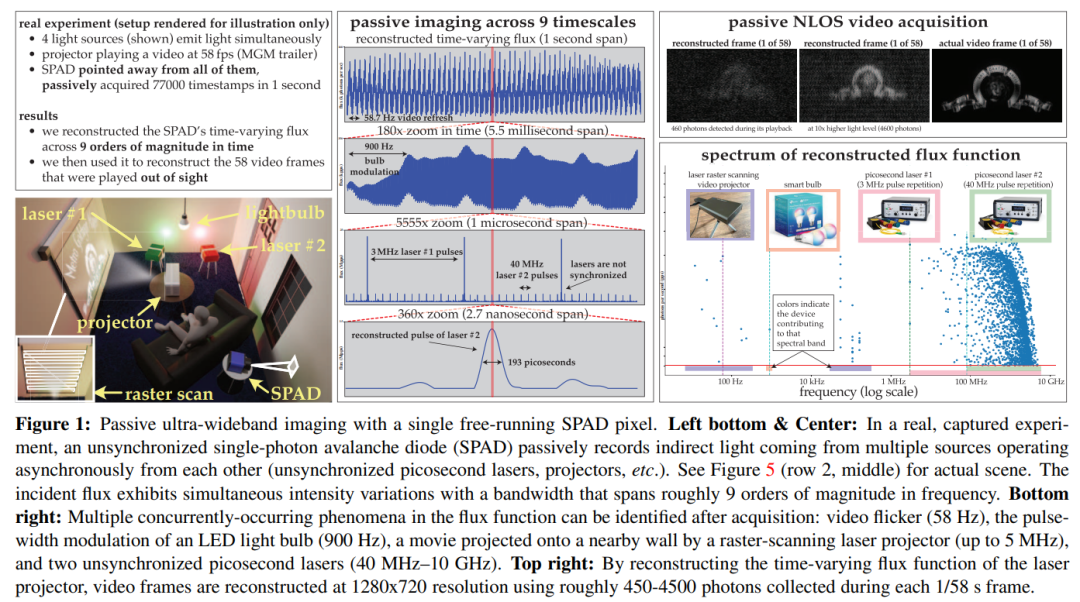
本文利用這個理論來表明,被動自由運行SPAD相機在低通量條件下具有可實現的頻率頻寬,可以跨越整個DC到31 GHz的範圍。同時,本文也推導出了一種新穎的傅立葉域通量重建演算法,並確保該演算法的雜訊模型在非常低的光子計數或不可忽略的死區時間下仍然有效
#透過實驗展示了這種非同步成像機制的潛力:(1)對於由以不同速度運行的光源(如燈泡、投影機、多個脈衝雷射)同時照明的場景進行成像,無需同步; (2)實現被動非視距視頻採集;(3)記錄超寬頻視頻,稍後以30 Hz的速度播放以展示日常運動,也可以以慢十億倍的速度播放以展示光本身的傳播

- #論文網址:https://arxiv.org/pdf/2302.05543.pdf
- #作者:Lvmin Zhang、Anyi Rao、Maneesh Agrawala
- #機構:史丹佛大學
- ##摘要:本研究提出了一種名為ControlNet的端對端神經網路架構。該架構透過添加額外的條件來控制擴散模型(如穩定擴散),以改善影像生成效果。同時,ControlNet能夠實現線稿生成全彩圖、生成具有相同深度結構的圖像,並透過手部關鍵點優化手部生成效果等
#
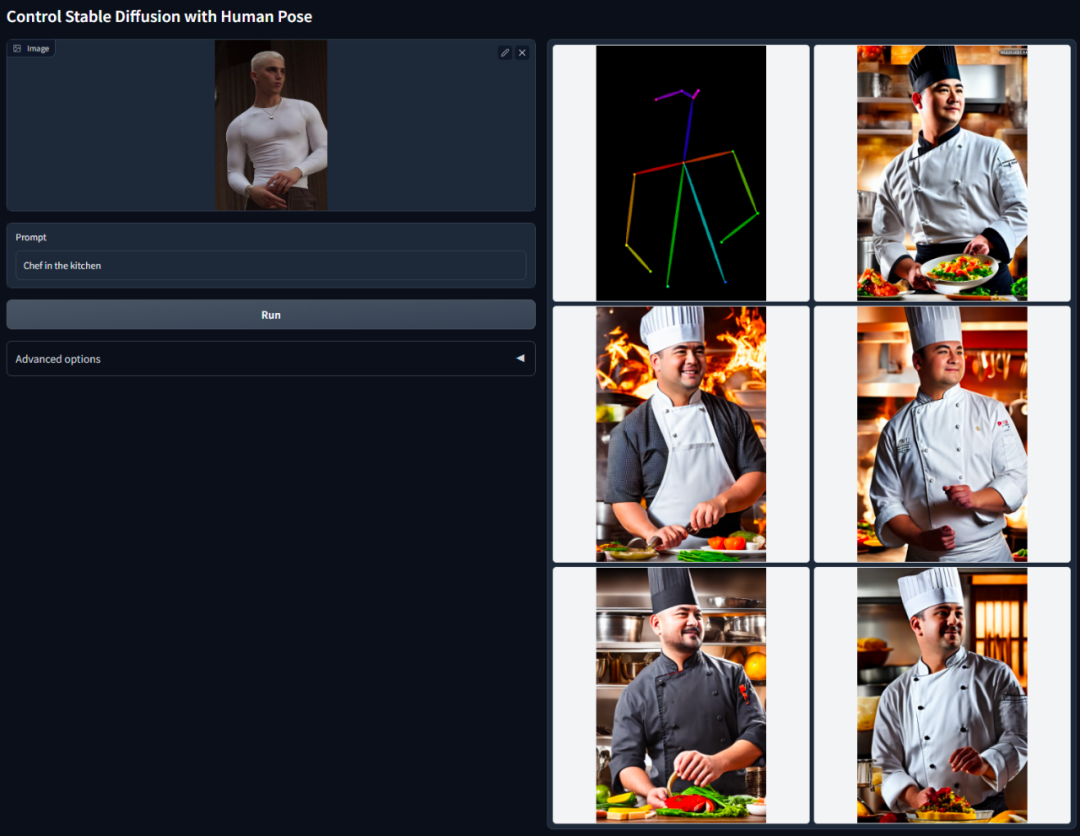
ControlNet 的核心思想是在文字描述之外添加一些額外條件來控制擴散模型(如 Stable Diffusion),從而更好地控制生成圖像的人物姿態、深度、畫面結構等資訊。
這裡的額外條件以影像的形式來輸入,模型可以基於這張輸入影像進行Canny 邊緣偵測、深度偵測、語意分割、霍夫變換直線偵測、整體嵌套邊緣偵測(HED)、人體姿態辨識等,然後在生成的影像中保留這些資訊。利用這個模型,我們可以直接把線稿或塗鴉轉換成全彩圖,產生具有相同深度結構的圖等等,透過手部關鍵點還能優化人物手部的生成。
請參閱機器之心的報道《AI降維打擊人類畫家,文生圖引入ControlNet,深度、邊緣資訊全能復用》以取得更詳細的介紹
最佳論文提名:SAM
#今年四月,Meta發布了名為「分割一切(SAM) 」的人工智慧模型,該模型能夠為任何圖像或視頻中的物體生成掩碼,這讓計算機視覺領域的研究者感到非常震驚,有人甚至說“計算機視覺不復存在了”
如今,這篇備受關注的論文摘要的最佳論文提名。

- #論文網址:https://arxiv.org/abs/2304.02643
- 機構:Meta AI
重寫後的內容:在解決分割問題之前,通常有兩種方法。第一種是互動式分割,這種方法可以用來分割任何類別的對象,但需要一個人透過迭代細化遮罩來指導方法。第二種是自動分割,可以用來分割預先定義的特定物件類別(例如貓或椅子),但需要大量手動註釋物件來進行訓練(例如數千甚至數萬個分割貓的例子)。然而,這兩種方法都沒有提供通用的、全自動的分割方法
Meta 提出的 SAM 很好的概括了這兩種方法。它是一個單一的模型,可以輕鬆地執行互動式分割和自動分割。此模型的可提示介面允許使用者以靈活的方式使用它,只需為模型設計正確的提示(點擊、框選、文字等),就可以完成廣泛的分割任務
總結一下,這些功能使得SAM能夠適應新的任務和領域。這種彈性在影像分割領域是獨一無二的
詳細介紹請參考機器之心報道:《CV 不存在了? Meta 發布「分割一切」AI 模型,CV 或迎來GPT-3 時刻》
#最佳學生論文
該研究由來自康乃爾大學、Google研究院和UC 柏克萊的研究者共同完成,一作是來自Cornell Tech 的博士生Qianqian Wang。他們共同提出了一種完整且全局一致的運動表徵 OmniMotion,並提出一種新的測試時(test-time)最佳化方法,對影片中每個像素進行準確、完整的運動估計。

- #論文網址:https://arxiv.org/abs/2306.05422
- 專案首頁:https://omnimotion.github.io/
#摘要:在電腦視覺領域,常用的運動估計方法有兩種:稀疏特徵追蹤和密集光流。但這兩種方法各有缺點,稀疏特徵追蹤不能建模所有像素的運動;密集光流無法長時間捕捉運動軌跡。
該研究提出的 OmniMotion 使用 quasi-3D 規範體積來表徵視頻,並透過局部空間和規範空間之間的雙射(bijection)對每個像素進行追蹤。這種表徵能夠確保全局一致性,即使在物體被遮蔽的情況下也能進行運動追踪,並對相機和物體運動的任何組合進行建模。該研究透過實驗顯示所提方法大大優於現有 SOTA 方法。
請參考機器之心報道《隨時隨地,追蹤每個像素,連遮擋都不怕的「追蹤一切」視訊演算法來了》以獲得更詳細的介紹
今年ICCV 除了這些得獎論文外,還有許多其他優秀論文值得大家關注。以下是17篇獲獎論文的初始清單

以上是ICCV 2023宣布ControlNet與「分割一切」等熱門論文獲獎的詳細內容。更多資訊請關注PHP中文網其他相關文章!