



在时间序列问题中,有一种类型的时间序列不是等频采样的,即每组相邻两个观测值的时间间隔不一样。时间序列表示学习在等频采样的时间序列中已经进行了比较多的研究,但是在这种不规则采样的时间序列中研究比较少,并且这类时间序列的建模方式和等频采样中的建模方式有比较大的差别
今天介绍的这篇文章,在不规则采样的时间序列问题中,探索了表示学习的应用方法,借鉴了NLP中的相关经验,在下游任务上取得了比较显著的效果。
 图片
图片
- 论文标题:PAITS: Pretraining and Augmentation for Irregularly-Sampled Time Series
- 下载地址:https://arxiv.org/pdf/2308.13703v1.pdf
1、不规则时间序列数据定义
以下是不规则时间序列数据的一种表示形式,如下图所示。每个时间序列由一组三元组组成,每个三元组包含时间、数值和特征三个字段,分别表示时间序列中每个元素的采样时间、数值和其他特征。除了这些三元组之外,每个序列还包括其他不随时间变化的静态特征,以及每个时间序列的标签
 图片
图片
一般这种不规则时间序列建模方法,常见的结构是将上述triple数据分别embedding后,拼接到一起,输入到transformer等模型中,这种方式将每个时刻的信息,以及每个时刻的时间表征融合到一起输入到模型,进行后续任务的预测。
 图片
图片
在本文的任务中,使用的数据既包括这些有label的数据外,还包括无label的数据,用于做无监督预训练。
2、方法概览
本文的预训练方法参考了自然语言处理领域的经验,主要涵盖了两个方面
预训练任务的设计:为了处理不规则的时间序列,需要设计适当的预训练任务,让模型能够从无监督数据中学习到有效的表示。本文主要介绍了基于预测和基于重构的两种预训练任务
数据增强方式设计:本研究中设计了用于无监督学习的数据增强方式,其中包括添加噪声、增加随机mask等方式
另外,文章还介绍了一种针对不同分布数据集的算法,用于探索最优的无监督学习方法
3、预训练任务设计
本文提出了两种不规则时间序列上的预训练任务,分别是Forecasting pretraining和Reconstruction pretraining。
在Forecasting pretraining中,对于时间序列中的每个特征,根据某个大小的时间窗口前序序列,预测它的取值。这里的特征指的是triplet中的feature。由于每种feature在一个时间窗口中可能出现多次,或者不会出现,因此文中采用了这个feature第一次出现的值作为label进行预训练。这其中输入的数据包括原始序列,以及增强后的时间序列。
在重建预训练中,首先对于一个原始的时间序列,通过某种数据增强方式生成一个增强后的序列,然后使用增强后的序列作为输入,经过编码器生成表示向量,再输入到一个解码器中还原原始的时间序列。文章中通过一个掩码来指导需要还原哪些部分的序列,如果这个掩码都为1就是还原整个序列
在得到预训练参数后,可以直接应用于下游的finetune任务,整个的pretrain-finetune流程如下图所示。
 图片
图片
4、数据增强方式设计
在这篇文章中,我们提出了两种数据增强的方法。第一种方法是增加噪音,通过在数据中引入一些随机的干扰来增加数据的多样性。第二种方法是随机遮盖,通过随机选择一些数据的部分进行遮盖,从而促使模型学习更加鲁棒的特征。这些数据增强的方法可以帮助我们提高模型的性能和泛化能力
对于原始序列的每个值或时间点,可以通过增加高斯噪声的方式来增加噪声。具体计算方法如下:
 图片
图片
随机mask的方式借鉴了NLP中的思路,通过随机选择time、feature、value等元素进行随机mask和替换,构造增强后的时间序列。
下图展示了上述两种类型数据增强方法的效果:
 图片
图片
此外,文中将数据增强、预训练方式等进行不同组合,针对不同的时间序列数据,从这些组合中search到最优的预训练方法。
5、实验结果
在文中进行了多个数据集的实验,对比了不同预训练方法在这些数据集上的效果。可以观察到,文中提出的预训练方式在大部分数据集上都取得了显著的效果提升
 图片
图片
以上是Google:非等頻取樣時間序列表示學習新方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 谷歌三件套指的是哪三个软件Sep 30, 2022 pm 01:54 PM
谷歌三件套指的是哪三个软件Sep 30, 2022 pm 01:54 PM谷歌三件套指的是:1、google play商店,即下载各种应用程序的平台,类似于移动助手,安卓用户可以在商店下载免费或付费的游戏和软件;2、Google Play服务,用于更新Google本家的应用和Google Play提供的其他第三方应用;3、谷歌服务框架(GMS),是系统软件里面可以删除的一个APK程序,通过谷歌平台上架的应用和游戏都需要框架的支持。
 为什么中国不卖google手机Mar 30, 2023 pm 05:31 PM
为什么中国不卖google手机Mar 30, 2023 pm 05:31 PM中国不卖google手机的原因:谷歌已经全面退出中国市场了,所以不能在中国销售,在国内是没有合法途径销售。在中国消费市场中,消费者大都倾向于物美价廉以及功能实用的产品,所以竞争实力本就因政治因素大打折扣的谷歌手机主体市场一直不在中国大陆。
 谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM
谷歌超强AI超算碾压英伟达A100!TPU v4性能提升10倍,细节首次公开Apr 07, 2023 pm 02:54 PM虽然谷歌早在2020年,就在自家的数据中心上部署了当时最强的AI芯片——TPU v4。但直到今年的4月4日,谷歌才首次公布了这台AI超算的技术细节。论文地址:https://arxiv.org/abs/2304.01433相比于TPU v3,TPU v4的性能要高出2.1倍,而在整合4096个芯片之后,超算的性能更是提升了10倍。另外,谷歌还声称,自家芯片要比英伟达A100更快、更节能。与A100对打,速度快1.7倍论文中,谷歌表示,对于规模相当的系统,TPU v4可以提供比英伟达A100强1.
 LLM之战,谷歌输了!越来越多顶尖研究员跳槽OpenAIApr 07, 2023 pm 05:48 PM
LLM之战,谷歌输了!越来越多顶尖研究员跳槽OpenAIApr 07, 2023 pm 05:48 PM前几天,谷歌差点遭遇一场公关危机,Bert一作、已跳槽OpenAI的前员工Jacob Devlin曝出,Bard竟是用ChatGPT的数据训练的。随后,谷歌火速否认。而这场争议,也牵出了一场大讨论:为什么越来越多Google顶尖研究员跳槽OpenAI?这场LLM战役它还能打赢吗?知友回复莱斯大学博士、知友「一堆废纸」表示,其实谷歌和OpenAI的差距,是数据的差距。「OpenAI对LLM有强大的执念,这是Google这类公司完全比不上的。当然人的差距只是一个方面,数据的差距以及对待数据的态度才
 谷歌并未放弃TensorFlow,将于2023年发布新版,明确四大支柱Apr 12, 2023 am 11:52 AM
谷歌并未放弃TensorFlow,将于2023年发布新版,明确四大支柱Apr 12, 2023 am 11:52 AM2015 年,谷歌大脑开放了一个名为「TensorFlow」的研究项目,这款产品迅速流行起来,成为人工智能业界的主流深度学习框架,塑造了现代机器学习的生态系统。从那时起,成千上万的开源贡献者以及众多的开发人员、社区组织者、研究人员和教育工作者等都投入到这一开源软件库上。然而七年后的今天,故事的走向已经完全不同:谷歌的 TensorFlow 失去了开发者的拥护。因为 TensorFlow 用户已经开始转向 Meta 推出的另一款框架 PyTorch。众多开发者都认为 TensorFlow 已经输掉
 四分钟对打300多次,谷歌教会机器人打乒乓球Apr 10, 2023 am 09:11 AM
四分钟对打300多次,谷歌教会机器人打乒乓球Apr 10, 2023 am 09:11 AM让一位乒乓球爱好者和机器人对打,按照机器人的发展趋势来看,谁输谁赢还真说不准。机器人拥有灵巧的可操作性、腿部运动灵活、抓握能力出色…… 已被广泛应用于各种挑战任务。但在与人类互动紧密的任务中,机器人的表现又如何呢?就拿乒乓球来说,这需要双方高度配合,并且球的运动非常快速,这对算法提出了重大挑战。在乒乓球比赛中,首要的就是速度和精度,这对学习算法提出了很高的要求。同时,这项运动具有高度结构化(具有固定的、可预测的环境)和多智能体协作(机器人可以与人类或其他机器人一起对打)两大特点,使其成为研究人
 参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」Apr 11, 2023 pm 11:16 PM
参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」Apr 11, 2023 pm 11:16 PM由于可以做一些没训练过的事情,大型语言模型似乎具有某种魔力,也因此成为了媒体和研究员炒作和关注的焦点。当扩展大型语言模型时,偶尔会出现一些较小模型没有的新能力,这种类似于「创造力」的属性被称作「突现」能力,代表我们向通用人工智能迈进了一大步。如今,来自谷歌、斯坦福、Deepmind和北卡罗来纳大学的研究人员,正在探索大型语言模型中的「突现」能力。解码器提示的 DALL-E神奇的「突现」能力自然语言处理(NLP)已经被基于大量文本数据训练的语言模型彻底改变。扩大语言模型的规模通常会提高一系列下游N
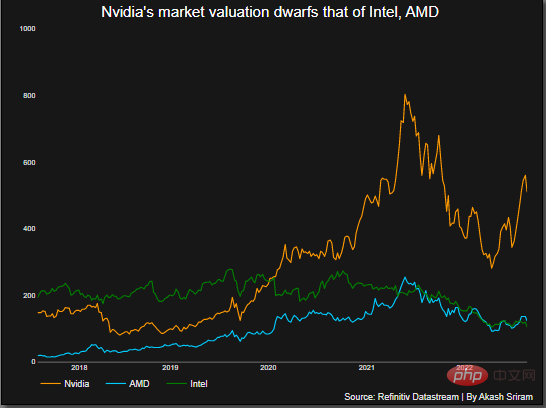 超5800亿美元!微软谷歌神仙打架,让英伟达市值飙升,约为5个英特尔Apr 11, 2023 pm 04:31 PM
超5800亿美元!微软谷歌神仙打架,让英伟达市值飙升,约为5个英特尔Apr 11, 2023 pm 04:31 PMChatGPT在手,有问必答。你可知,与它每次对话的计算成本简直让人泪目。此前,分析师称ChatGPT回复一次,需要2美分。要知道,人工智能聊天机器人所需的算力背后烧的可是GPU。这恰恰让像英伟达这样的芯片公司豪赚了一把。2月23日,英伟达股价飙升,使其市值增加了700多亿美元,总市值超5800亿美元,大约是英特尔的5倍。在英伟达之外,AMD可以称得上是图形处理器行业的第二大厂商,市场份额约为20%。而英特尔持有不到1%的市场份额。ChatGPT在跑,英伟达在赚随着ChatGPT解锁潜在的应用案


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

SublimeText3漢化版
中文版,非常好用

