
UC伯克利腦機介面突破:利用腦波重現音樂,為語言障礙者帶來福音!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-09-30 15:49:071131瀏覽
腦機介面時代,天天都有新鮮玩意兒。
今天帶來四個字:腦植音樂。
具體來說,就是先用AI來觀察某段音樂會讓人的大腦中產生什麼樣的電波,然後直接在有需要的人的大腦裡模擬這個電波的活動,以此來達到治療某類疾病的目的。
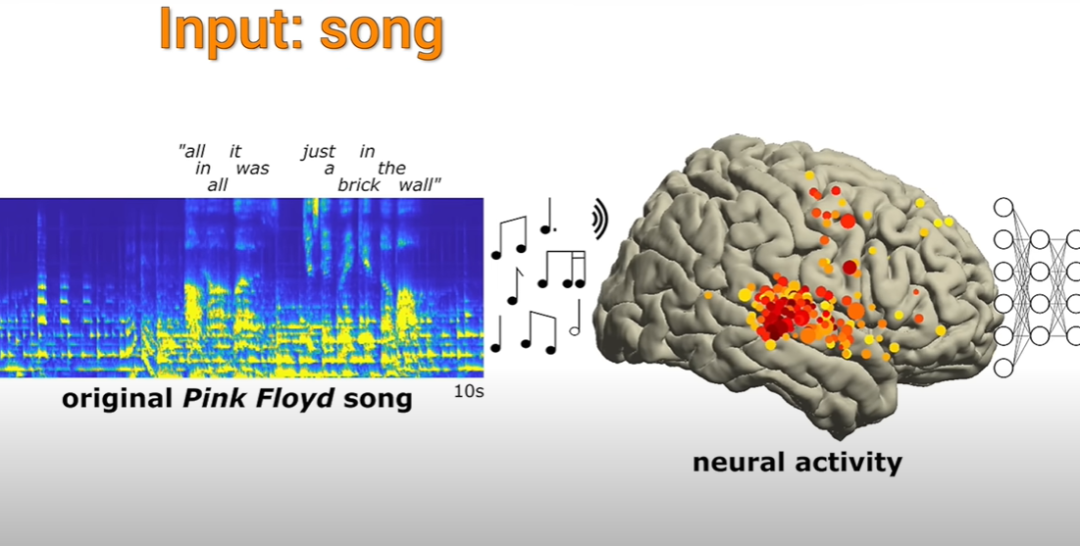
讓我們回顧一下幾年前的Albany醫療中心,看看那裡的神經科學家們是如何進行研究的
語言障礙者的福音!
在奧爾巴尼醫療中心,一首名為「另一面牆」的音樂緩緩響起,充滿了整個醫院病房
躺在病床上準備接受癲癇手術的病人們,他們並非醫生,而是在聆聽
#神經科學家們聚集在一旁,觀察電腦螢幕上顯示的病人腦電圖活動
主要觀察到的內容,就是大腦部位區域在聽到一些獨屬於音樂的東西後所產生的電極活動,然後看看透過這些記錄下來的電極活動能不能復現他們在聽什麼音樂。
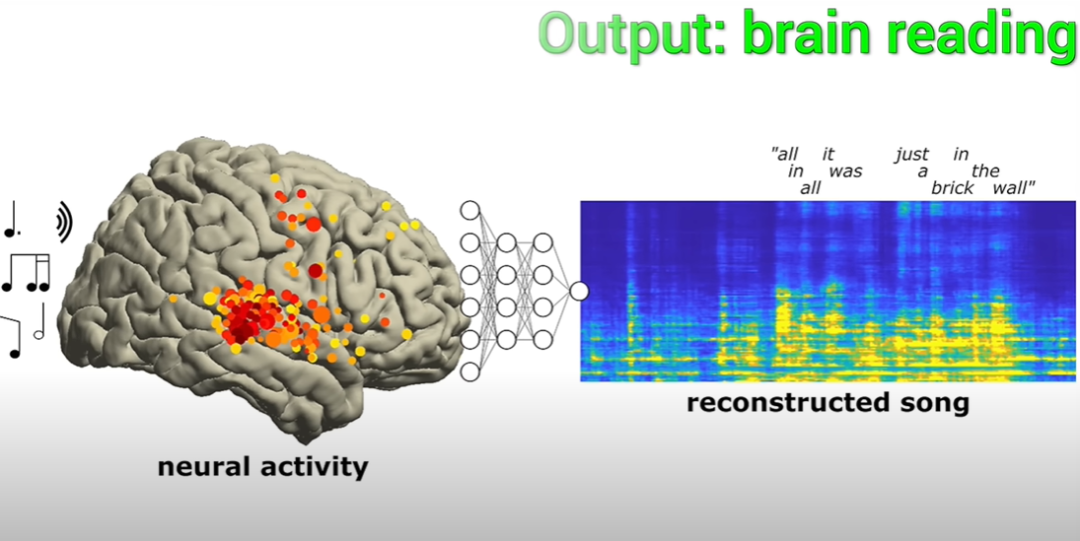
在前面提到的內容中,涉及音樂的元素包括音調、節奏、和聲以及歌詞
#這個研究進行了十多年。加州大學柏克萊分校的神經科學家們對29名參與實驗的癲癇患者的數據進行了詳細分析
科學家們能夠根據病人大腦中電極活動的結果,成功重建了這段音樂
在復現的歌曲中,其中的一句歌詞「All in all it was just a brick in the wall」的節奏非常完整,雖說歌詞不算太清晰,但研究人員表示,可以破解出來,並非混沌一片。
而這首歌也是科學家第一個透過大腦電極活動重建歌曲成功的案例。
結果表明,透過對腦電波的記錄和解除,是可以捕捉到一些音樂元素以及音節的。
這些音樂元素可以用專業術語稱為韻律(prosody),包括節奏、重音、抑揚頓挫等等。這些元素的意義無法僅透過語言來表達
此外,由於這些顱內腦電圖(iEEG)只記錄在大腦表層進行的活動(也就是最接近聽覺中心的部分),因此無需擔心有人會通過這種方式偷聽你在聽什麼歌(笑)
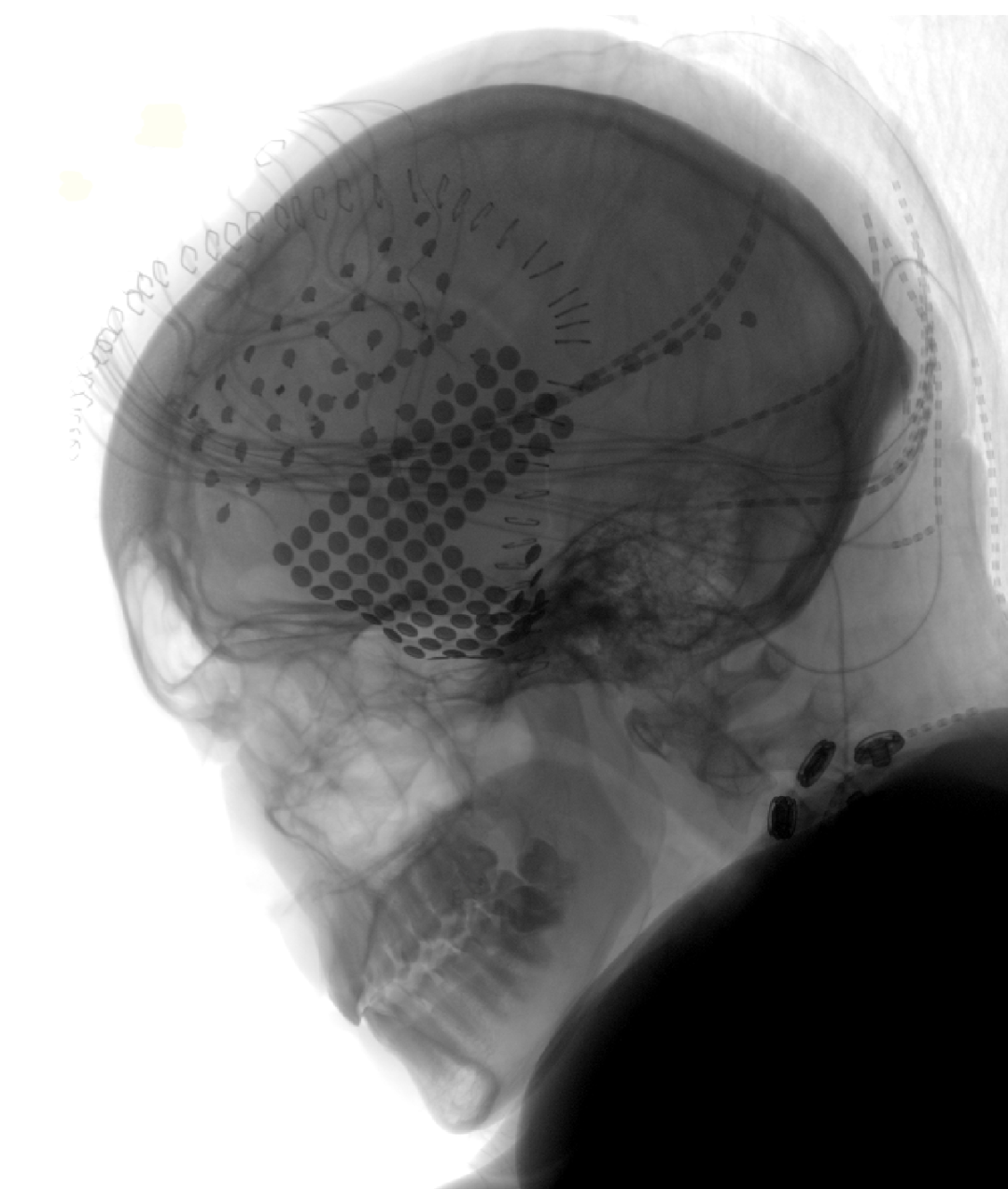
#但是,對於那些得了中風,或者癱瘓,導致溝通困難的人來說,這種從大腦表層電極活動進行的複現,可以幫助他們重現樂曲的音樂性。
顯然,這比之前那種機器人式的、語調呆呆的複現要好得多。就像上面提到的一樣,有些東西光靠文字真不夠,咱聽的是那個調調。
Helen Wills神經科學研究所的神經科學家,兼加州大學柏克萊分校的心理學教授Robert Knight表示,這是一項了不起的成果。
「對我來說,音樂的魅力之一就在於它的前奏和所要表達的情感內容。而隨著腦機介面領域的不斷突破,這項技術就可以給有需要的人,透過植入的方式提供只有音樂才能提供的東西。受眾可能包括患有漸凍人症的病人,或是癲癇病人,總之一切因為病症影響到語言輸出神經的人。」
換句話說,我們現在能做的不只是語言本身,與音樂相比,文字所表達的情感可能會顯得有些單薄。我相信,從現在開始,我們才真正踏上了解閱讀之旅
而隨著腦電波記錄技術的更迭,未來的某一天我們也有可能在不打開大腦的情況下,透過附著在頭皮上的電極進行記錄。
Knight表示,目前的頭皮腦電圖已經可以測量並記錄一些大腦活動,比方說從一大串字母中檢測出單個字母。雖說效率不高,每個字母都得花至少20秒鐘,但總歸是個開始。
大力發展頭皮電極的原因在於目前無創技術的熟練程度不夠。換句話說,開顱測量無法百分之百確保安全性
頭皮電極的測量準確度,特別是對於大腦深層的測量,仍然有待提高。可以說已經取得了一定的成功,但並不完全成功
能讀心術嗎?
直接給答案:no。
打個比方,對於那些說話有障礙的人來說,腦機介面技術相當於給了他們一把「鍵盤」,透過捕捉腦電波的活動,他們就可以在這張「鍵盤」上打字,表達他們所想表達的。
例如,以霍金為例,他所使用的裝置就是透過捕捉他的腦電波來產生機器人聲音的語音

透過類比,你應該可以理解了。光是看到這個「鍵盤」,你無法知道它在想些什麼。現在的技術使得鍵盤可以啟動並輸出語音。如果沒有人想要輸入,鍵盤就不會啟動,你也無法知道它在想什麼
所以,讀心術是不可行的
實驗內容
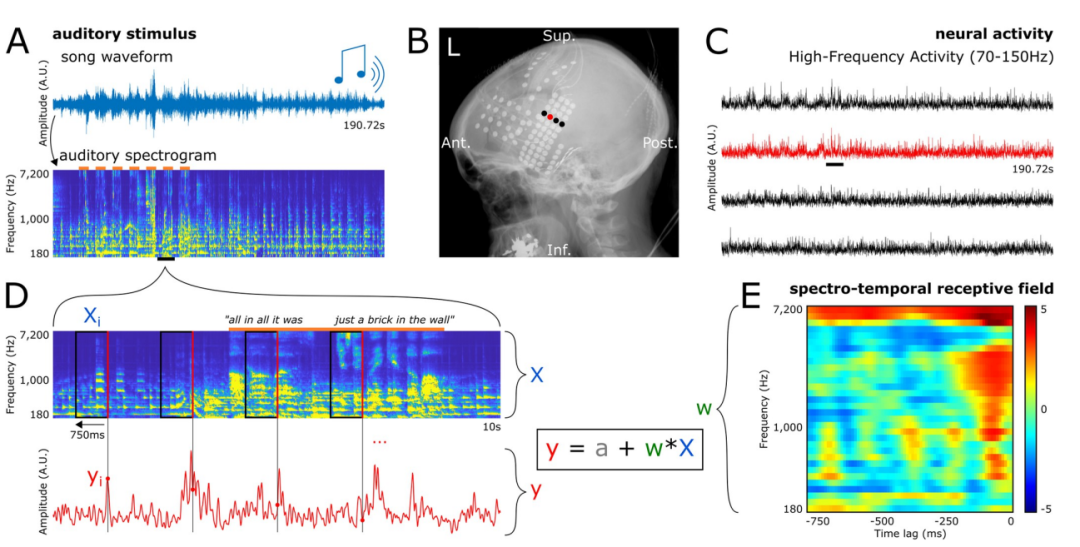
請看下圖,圖A展示了實驗中所使用的歌曲的整體波形圖。圖A下方是該歌曲的聽覺頻譜圖,最頂部的橘色條表示有人聲出現
圖B為X光片下,一名患者的電極覆蓋圖。每一個點代表一個電極。
C圖展示了B圖中四個電極的電極訊號。同時,圖中也顯示了歌曲刺激引發的高頻活動(HFA),以下滑的黑色短線表示,頻率在70到150赫茲之間
圖D展示了A中一小段(10秒)歌曲播放時的放大聽覺頻譜圖和電極神經活動圖。我們可以觀察到,HFA的時間點與頻譜圖中每個標示的矩形的右側紅色線條相吻合
這些配對情況就構成了研究人員用於訓練和評估編碼模型的範例。
研究人員的實驗結果顯示,解碼模型中用作預測因子的電極數量與預測準確率之間存在對數關係,如下圖所示。
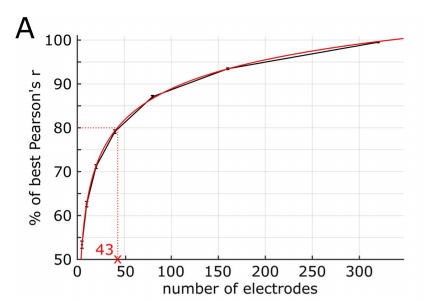
例如,使用43個電極(或12.4%)可以獲得80%的最佳預測準確率(最佳預測準確率即為使用所有347個電極的結果)。
在單一患者身上觀察到了相同的關係,這是研究人員的發現
此外,透過引導分析,研究人員觀察到資料集持續的時間與預測準確率之間也存在類似的對數關係,如下圖所示。
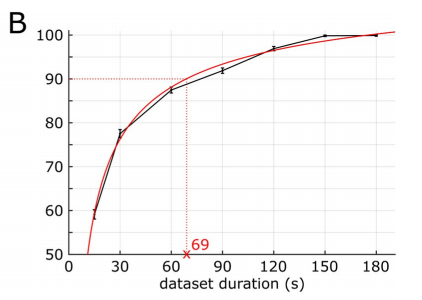
舉個例子,如果使用長度為69秒(佔總長度的36.1%)的數據,可以獲得90%的最佳效能(最佳性能是指使用整首歌長190.72秒的數據得出的)
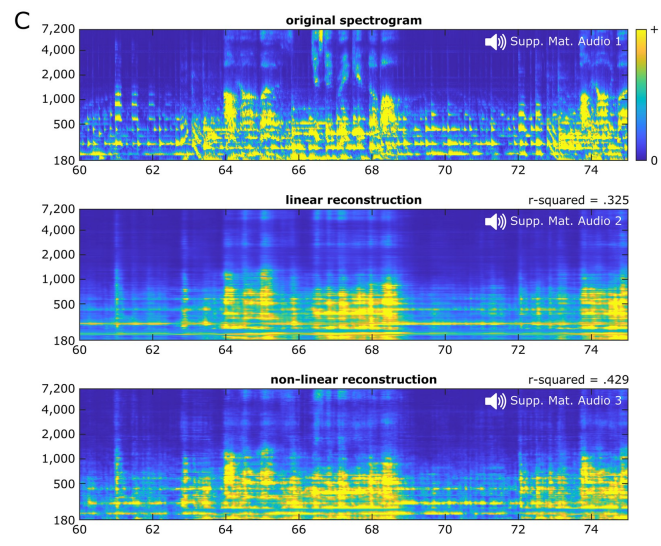
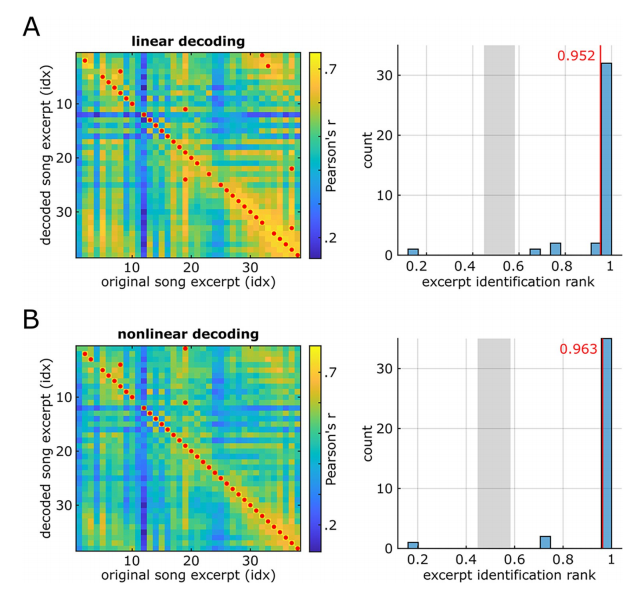
#而關於模型類型,線性解碼的平均解碼準確率為0.325,而使用雙層全連接神經網路的非線性解碼的平均解碼準確率則為0.429。
整體而言,線性音樂歌曲重建(音訊S2)聽起來悶悶的,對一些音樂元素(指人聲音節和主音吉他)的存在有很強的節奏提示,但可能對另外一些元素的感知有限。
非線性歌曲重建的(音訊S3)再現了一首可辨識的歌曲,與線性重建相比,細節更加豐富。音高和音色等頻譜元素的感知品質明顯提高,音素特徵也更清晰可辨。線性重建中存在的一些識別盲區也得到了一定程度的改進
以下是圖示:
所以研究人員使用非線性模型透過第29個患者的61個電極重建了歌曲。
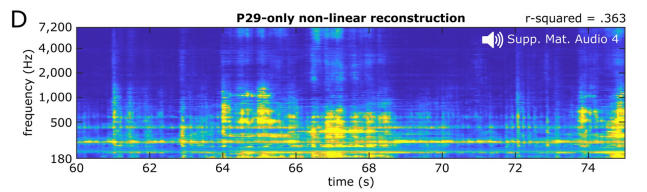
這些模型的表現優於基於所有病患電極的線性重建,但解碼準確度不如使用所有病患的347個電極所獲得的準確度
在感知方面,這些基於單一患者的模型提供了足夠高的頻譜-時間的細節,足以讓研究人員識別出歌曲(音訊S4)
同時,為了評估基於單一患者的解碼下限,研究人員從另外3位患者的腦神經活動中重建了歌曲,這3位患者的電極數量較少,分別為23、17和10個,而上述第29個患者的電極數為61個,電極密度也相對較低。當然,還是涵蓋了歌曲的反應區域,線性解碼的準確度也算良好。
在重建的波形圖(音訊檔案S5、S6 和 S7)中,研究人員檢索到了部分人聲。然後,他們將原始歌曲與解碼歌曲的頻譜圖進行關聯,對解碼歌曲的可識別性進行了量化。
線性重構(下圖A)和非線性重構(下圖B)都提供了較高比例的正確辨識率。
另外,研究人員分析了所有347個重要電極的STRF(頻譜-時間接受域)係數,以評估不同音樂元素在不同腦區的編碼情形。
這項分析揭示了不同頻譜和時間的調諧模式
#為了全面描述歌曲頻譜圖與神經活動之間的關係,研究人員對所有重要的STRFs進行了獨立成分分析(ICA)。
研究人員發現了3個具有不同頻譜-時間調諧模式的組成部分,每個部分的變異解釋率均超過了5%,合計變異數解釋率達52.5%,如下圖所示。
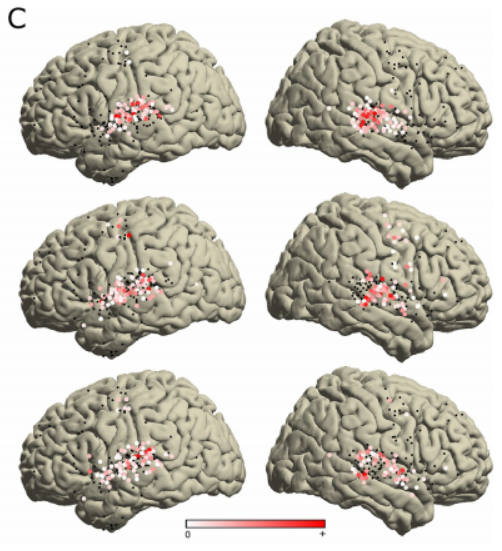
第一個部分(解釋方差為28%)展示了一個正係數的集群,該集群在大約500Hz到7000Hz的寬頻率範圍內分佈,並且在觀察到HFA之前的約90ms的狹窄時間視窗內可見
這個瞬時集群顯示了聲音起始的調諧。這部分稱為起始部分,只出現在雙側STG後部的電極上,如下圖所示的位置
最後,研究人員表示,未來的研究可能會擴大電極的覆蓋範圍,改變模型的特徵和目標,或增加新的行為維度
以上是UC伯克利腦機介面突破:利用腦波重現音樂,為語言障礙者帶來福音!的詳細內容。更多資訊請關注PHP中文網其他相關文章!