



如何用Python for NLP自動標記並擷取PDF檔案中的關鍵資訊?
摘要:
自然語言處理(Natural Language Processing,簡稱NLP)是一門研究人與電腦之間如何進行自然語言互動的學科。在實際應用中,我們經常需要處理大量的文字數據,其中包含了各種各樣的資訊。本文將介紹如何使用Python中的NLP技術,結合第三方函式庫和工具,來自動標記和擷取PDF檔案中的關鍵資訊。
關鍵字:Python, NLP, PDF, 標籤, 提取
一、環境設定和依賴安裝
要使用Python for NLP自動標記和提取PDF文件中的關鍵信息,我們需要先搭建對應的環境,並安裝必要的依賴函式庫。以下是一些常用的庫和工具:
- pdfplumber:用於處理PDF文件,可以提取文字和表格等資訊。
- nltk:自然語言處理工具包,提供了各種文字處理和分析的功能。
- scikit-learn:機器學習函式庫,包含了一些常用的文字特徵提取和分類演算法。
可以使用以下指令安裝這些函式庫:
pip install pdfplumber
pip install nltk
pip install scikit-learn
二、PDF文本提取
使用pdfplumber庫可以很方便地從PDF文件中提取文字資訊。以下是一個簡單的範例程式碼:
import pdfplumber
def extract_text_from_pdf(file_path):
with pdfplumber.open(file_path) as pdf:
text = []
for page in pdf.pages:
text.append(page.extract_text())
return text
file_path = "example.pdf"
text = extract_text_from_pdf(file_path)
print(text)以上程式碼將會開啟名為"example.pdf"的PDF文件,並將其所有頁面的文字提取出來。提取的文字會以列表的形式傳回。
三、文字預處理和標記
在進行文字標記之前,我們通常需要進行一些預處理操作,以便提高標記的準確性和效果。常用的預處理操作包括移除標點符號、停用詞、數字等。我們可以使用nltk函式庫來實現這些功能。以下是一個簡單的範例程式碼:
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
def preprocess_text(text):
# 分词
tokens = word_tokenize(text)
# 去除标点符号和停用词
tokens = [token for token in tokens if token.isalpha() and token.lower() not in stopwords.words("english")]
# 词形还原
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(token) for token in tokens]
return tokens
preprocessed_text = [preprocess_text(t) for t in text]
print(preprocessed_text)以上程式碼首先使用nltk的word_tokenize函數對文字進行分詞,然後移除了標點符號和停用詞,並對單字進行了詞形還原。最終,將預處理後的文字以列表的形式傳回。
四、關鍵資訊擷取
在標記文字之後,我們可以使用機器學習演算法來擷取關鍵資訊。常用的方法包括文字分類、實體辨識等。以下是一個簡單的範例程式碼,示範如何使用scikit-learn函式庫進行文字分類:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
# 假设我们有一个训练集,包含了已标记的文本和对应的标签
train_data = [("This is a positive text", "Positive"),
("This is a negative text", "Negative")]
# 使用管道构建分类器模型
text_classifier = Pipeline([
("tfidf", TfidfVectorizer()),
("clf", MultinomialNB())
])
# 训练模型
text_classifier.fit(train_data)
# 使用模型进行预测
test_data = ["This is a test text"]
predicted_label = text_classifier.predict(test_data)
print(predicted_label)以上程式碼首先建立了一個基於TF-IDF特徵擷取和樸素貝葉斯分類演算法的文字分類器模型。然後使用訓練資料進行訓練,並使用模型對測試資料進行預測。最終,將預測的標籤列印出來。
五、總結
使用Python for NLP自動標記和提取PDF檔案中的關鍵資訊是一項非常有用的技術。本文介紹如何使用pdfplumber、nltk和scikit-learn等函式庫和工具,在Python環境中進行PDF文字擷取、文字預處理、文字標記和關鍵資訊擷取。希望本文對讀者能夠有所幫助,並鼓勵讀者進一步深入研究和應用NLP技術。
以上是如何用Python for NLP自動標記並擷取PDF檔案中的關鍵資訊?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM
如何利用Python for NLP将PDF文件中的文本进行翻译?Sep 28, 2023 pm 01:13 PM如何利用PythonforNLP将PDF文件中的文本进行翻译?随着全球化的进程日益加深,跨语言翻译的需求也越来越大。而PDF文件作为一种常见的文档形式,其中可能包含了大量的文本信息。如果我们想将PDF文件中的文字内容进行翻译,可以运用Python的自然语言处理(NLP)技术来实现。本文将介绍一种利用PythonforNLP进行PDF文本翻译的方法,并
 如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM
如何利用Python for NLP处理PDF文件中的表格数据?Sep 27, 2023 pm 03:04 PM如何利用PythonforNLP处理PDF文件中的表格数据?摘要:自然语言处理(NaturalLanguageProcessing,简称NLP)是一个涉及计算机科学和人工智能领域的重要领域,而处理PDF文件中的表格数据是NLP中一个常见的任务。本文将介绍如何使用Python和一些常用的库来处理PDF文件中的表格数据,包括提取表格数据、数据预处理和转换
 详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM
详细讲解Python之Seaborn(数据可视化)Apr 21, 2022 pm 06:08 PM本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于Seaborn的相关问题,包括了数据可视化处理的散点图、折线图、条形图等等内容,下面一起来看一下,希望对大家有帮助。
 Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PM
Python for NLP:如何处理包含多个章节的PDF文件?Sep 27, 2023 pm 08:55 PMPythonforNLP:如何处理包含多个章节的PDF文件?在自然语言处理(NLP)任务中,我们常常需要处理包含多个章节的PDF文件。这些文件往往是学术论文、小说、技术手册等,每个章节都有其特定的格式和内容。本文将介绍如何使用Python处理这类PDF文件,并提供具体的代码示例。首先,我们需要安装一些Python库来帮助我们处理PDF文件。其中最常用的是
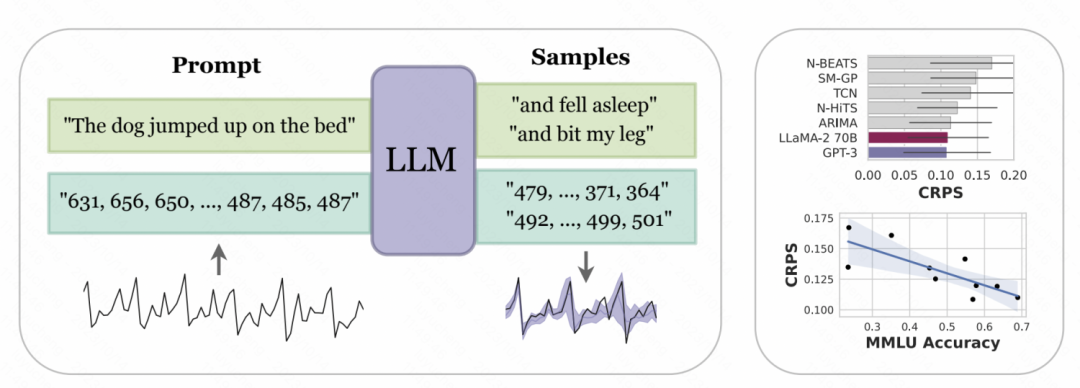 一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM
一篇学会大模型浪潮下的时间序列预测Nov 06, 2023 am 08:13 AM今天跟大家聊一聊大模型在时间序列预测中的应用。随着大模型在NLP领域的发展,越来越多的工作尝试将大模型应用到时间序列预测领域中。这篇文章介绍了大模型应用到时间序列预测的主要方法,并汇总了近期相关的一些工作,帮助大家理解大模型时代时间序列预测的研究方法。1、大模型时间序列预测方法最近三个月涌现了很多大模型做时间序列预测的工作,基本可以分为2种类型。重写后的内容:一种方法是直接使用NLP的大型模型进行时间序列预测。在这种方法中,使用GPT、Llama等NLP大型模型来进行时间序列预测,关键在于如何将
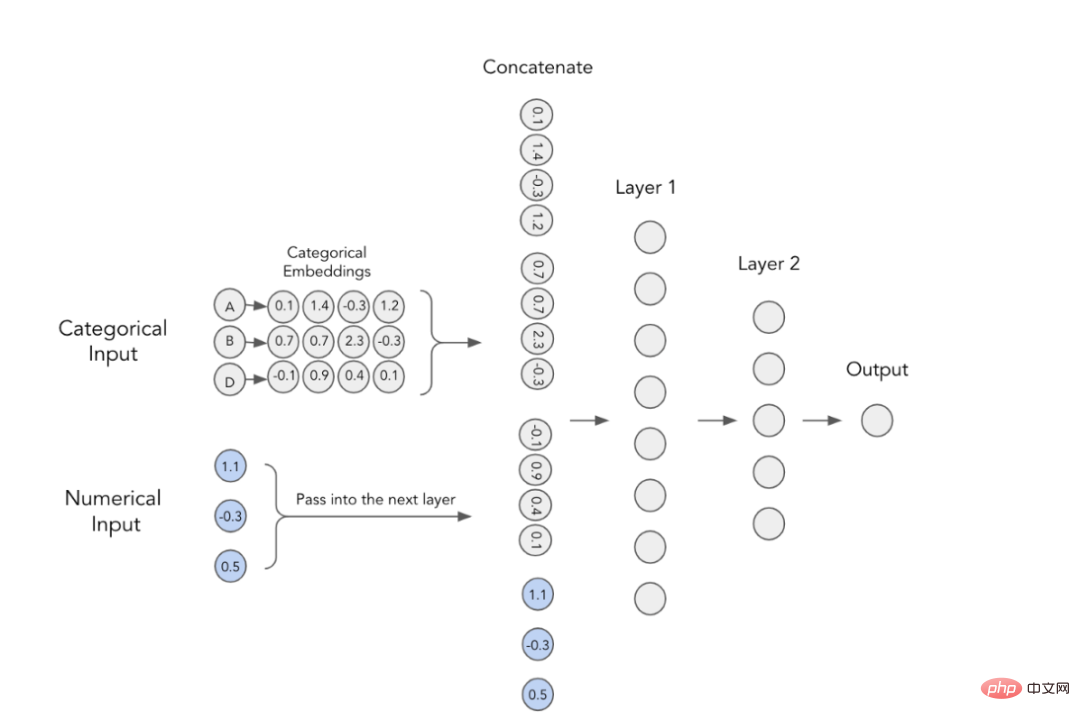 TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM
TabTransformer转换器提升多层感知机性能深度解析Apr 17, 2023 pm 03:25 PM如今,转换器(Transformers)成为大多数先进的自然语言处理(NLP)和计算机视觉(CV)体系结构中的关键模块。然而,表格式数据领域仍然主要以梯度提升决策树(GBDT)算法为主导。于是,有人试图弥合这一差距。其中,第一篇基于转换器的表格数据建模论文是由Huang等人于2020年发表的论文《TabTransformer:使用上下文嵌入的表格数据建模》。本文旨在提供该论文内容的基本展示,同时将深入探讨TabTransformer模型的实现细节,并向您展示如何针对我们自己的数据来具体使用Ta
 分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AM
分享10款高效的VSCode插件,总有一款能够惊艳到你!!Mar 09, 2021 am 10:15 AMVS Code的确是一款非常热门、有强大用户基础的一款开发工具。本文给大家介绍一下10款高效、好用的插件,能够让原本单薄的VS Code如虎添翼,开发效率顿时提升到一个新的阶段。
 Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AM
Python for NLP:如何从PDF文件中提取并分析脚注和尾注?Sep 28, 2023 am 11:45 AMPythonforNLP:如何从PDF文件中提取并分析脚注和尾注引言:自然语言处理(NLP)是计算机科学和人工智能领域中的一个重要研究方向。PDF文件作为一种常见的文档格式,在实际应用中经常遇到。本文介绍如何使用Python从PDF文件中提取并分析脚注和尾注,为NLP任务提供更全面的文本信息。文章将结合具体的代码示例进行介绍。一、安装和导入相关库要实现从


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

WebStorm Mac版
好用的JavaScript開發工具

Dreamweaver Mac版
視覺化網頁開發工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

記事本++7.3.1
好用且免費的程式碼編輯器

