



AI Agent 是目前炙手可熱的一個領域,在OpenAI 應用研究主管LilianWeng 寫的一篇長篇文章中[1],她提出了Agent = LLM 記憶規劃技能工具使用的概念
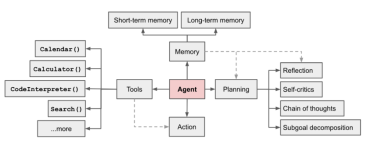
圖1 Overview of a LLM-powered autonomous agent system
Agent的作用是利用LLM的強大語言理解和邏輯推理能力,呼叫工具來幫助人類完成任務。然而,這也帶來了一些挑戰,例如基礎模型的能力決定了Agent調用工具的效率,但基礎模型本身存在著大模型幻覺等問題
本文以「輸入一段指令自動實現複雜任務拆分與函數呼叫」的場景為例,來建構基礎Agent 流程,並著重講解如何透過「基礎模型選擇」、「Prompt設計」等來成功建構「任務拆分”和“函數調用”模組。
重新寫的內容是:位址:
https://sota. jiqizhixin.com/project/smart_agent
#GitHub Repo:
要重寫的內容是:https://github.com/zzlgreat/smart_agent
任務拆分&函數呼叫Agent 流程
##對於實現「輸入一段指令自動實現複雜任務拆分和函數呼叫」,專案建構的Agent 流程如下:
- planner:根據使用者輸入的指令拆分任務。確定自己擁有的工具清單toolkit,告訴拆分任務的大模型planner 自己具有哪些工具,需要完成什麼樣的任務,planner 把任務拆分為計劃1,2,3...
- distributor:負責選擇適當的工具來toolkit 執行計劃。函數呼叫模型需要根據計劃的不同分別選擇對應的工具。
- worker:負責呼叫工具箱中的任務,並且傳回任務呼叫的結果。
- solver:整理出來的分佈計畫和對應的結果組合為一個 long story,再由 solver 進行總結歸納。
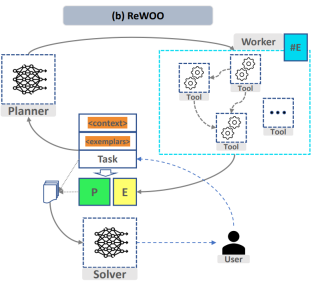
#圖1 《ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models》
# #為了實現上述流程,在「任務拆分」和「函數呼叫」模組中,專案分別設計了兩個微調模型,以實現將複雜任務拆分並按需調用自訂函數的功能。歸納總結的模型solver,可以與拆分任務模型相同
#微調任務拆分&函數呼叫模型
#2.1 微調經驗總結
在「任務拆分」模組中,大模型需要具備將複雜任務分解為簡單任務的能力。 「任務拆分」的成功與否主要取決於兩個因素:
- #基礎模型選擇:為了分割複雜任務,選擇微調的基礎模型本身需要良好的理解和泛化能力,也就是根據prompt 指令拆分訓練集中未見的任務。目前來講,選擇高參數的大模型更容易做到這一點。
- Prompt 設計#:prompt 能否成功地呼叫模型的思維鏈,將任務拆分為子任務。
同時希望任務分割模型在給定prompt 範本下的輸出格式可以盡可能相對固定,但也不會過度擬合喪失模型原本的推理和泛化能力,這裡採取lora 微調qv 層,對原模型的結構改變盡可能少。
在「函數呼叫」模組中,大模型需要具備穩定呼叫工具的能力,以適應處理任務的要求:
###- 損失函數調整:除選擇的基礎模型本身泛化能力、Prompt 設計外,為實現模型的輸出盡可能地固定、根據輸出穩定調用所需函數,採用「prompt loss-mask」的方法[2]進行qlora 訓練(詳見下文闡述),並透過魔改attention mask 的方式,在qlora 微調中使用插入eos token 的小技巧來穩定住模型的輸出。
此外,在算力使用方面,透過lora/qlora 微調實現了低算力條件下大型語言模型的微調和推理,並採用量化部署的方式,進一步降低推理的門檻。
2.2 基礎模型選擇
#對於選擇「任務拆分」模型,我們希望模型具備強大的泛化能力和一定的思維鏈能力。在這方面,我們可以參考HuggingFace上的Open LLM排行榜來選擇模型,我們更關注的是衡量文本模型多任務準確性的測試MMLU和綜合評分Average
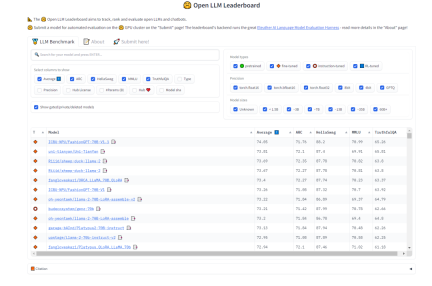
需要重新書寫的內容是:圖2 HuggingFace 開放的LLM排行榜(0921)
本專案選擇了任務分割模型型號為:
- #AIDC-ai-business/Marcoroni-70B:此模型基於Llama2 70B 微調,負責拆分任務。根據HuggingFace 上Open LLM Leaderboard 顯示,該模型的MMLU 和average 都比較高,而且該模型的訓練過程中加入了大量的Orca 風格的數據,適用於多輪對話,在plan-distribute-work-plan-work ……summary 的流程中效果表現會更好。
對於選擇"函數呼叫"模型,meta開源的Llama2版本的CodeLlama程式設計模型的原始訓練資料包含了大量的程式碼數據,因此可以嘗試使用qlora進行自訂腳本微調。對於函數呼叫模型,選擇CodeLlama模型(34b/13b/7b均可)作為基準
本項目選擇了函數呼叫模型型號為:
################################################################################################################## ###############codellama 34b/7b:負責函數呼叫的模型,該模型採用大量程式碼資料訓練,程式碼資料中必然包含大量對函數的描述類自然語言,對於給定函數的描述具有良好的zero-shot 能力。 ##################為了對「函數呼叫」模型進行微調,該專案採用了 prompt loss mask 的訓練方式,以穩定處理模型的輸出。以下是損失函數的調整方式:######
- 損失掩碼(loss_mask):
- loss_mask 是一個與輸入序列input_ids形狀相同的張量(tensor)。每個元素都是 0 或 1,其中 1 表示對應的位置的標籤應被考慮在損失計算中,而 0 表示不應被考慮。
- 例如,如果某些標籤是填充的(通常是因為批次中的序列長度不同),不想在損失的計算中考慮這些填充的標籤。在這種情況下,loss_mask 為這些位置提供了一個 0,從而遮蔽了這些位置的損失。
- #損失計算:
-
首先,使用了CrossEntropyLoss 來計算未mask 的損失。
設定 reductinotallow='none' 來確保為序列中的每個位置都傳回一個損失值,而不是一個總和或平均值。 - 然後,使用 loss_mask 來 mask 損失。透過將 loss_mask 與 losses 相乘,得到了 masked_loss。這樣,loss_mask 中為 0 的位置在 masked_loss 的損失值也是 0。
- #損失聚合:
- 將所有的masked_loss 求和,並透過loss_mask.sum() 來歸一化。這確保了你只考慮了被 mask 為 1 的標籤的損失。為了防止除以零的情況,再加一個很小的數 1e-9。
- 如果 loss_mask 的所有值都是 0(即 loss_mask.sum() == 0),那麼直接傳回一個 0 的損失值。
2.3 硬體需求:
- 6*4090 for Marcoroni-70B's 16bit lora
- #2*4090 for codellama 34b's qlora / 1*4090 for codellama 13/7b's qlora
2.4 Prompt 格式設計
任務拆分方面,該專案使用了大型語言模型高效推理框架ReWOO(Reasoning WithOut Observation)中planner 設計的Prompt 格式。只需要將'Wikipedia[input]'等函數替換為相應的函數和描述即可,以下是該範例prompt:
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
對於函數調用,因為後續會進行qlora 微調,所以直接採用huggingface 上開源函數呼叫資料集[3] 中的prompt 樣式。請參見下文。
指令資料集準備
3.1 資料來源
- #拆除任務模型: Marcoroni-70B 採用的是alpaca 的提示範本。此模型在 Llama2 70B 上進行指令微調,為和原始模型的範本進行對齊,需採用 alpaca 格式的資料集。這裡使用 rewoo 的 planner 資料集格式,但在原始資料集中只有呼叫 wiki 和自己的選項,所以可以套用該模板,並採用 gpt4 的介面來製作該樣式的資料集。
- 函數呼叫模型:儘管所選用的HuggingFace 開源函數呼叫的資料集的資料量較少(55 行),但qlora 十分有效,在該資料集中也附帶了程式碼訓練模板。
3.2 資料集格式
- #任務分割模型資料格式:alpaca
### Instruction:<prompt> (without the )### Response:如:### Instruction:For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result. What movies did the director of 'Oppenheim' direct? List the top 10 best.### Response:Step 1: Identify the director of "Oppenheimer" movie.#E1 = search_wiki("Director of Oppenheimer")Step 2: Retrieve information about the director's other works.If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.For example, if Christopher Nolan is found as the director of "Oppenheimer":#E2 = search_bing("Filmography of Christopher Nolan")Step 3: Extract the list of films directed by this person from the retrieved information.From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.</prompt>
- 函數呼叫模型資料格式:
採用trelis 資料集的格式。資料集規模較小,僅有55行。其結構實際上與alpaca格式相似。分為systemPrompt,userPrompt和assistantResponse,分別對應alpaca的Instruction,prompt和Response。以下是範例:
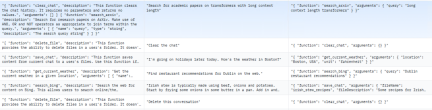
圖3 HuggingFace 函數呼叫開源資料集範例
微调过程说明
4.1 微调环境
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
4.2 微调步骤
需要进行针对 Marcoroni-70B 的 lora 微调
- LLaMA-Efficient-Tuning 框架支持 deepspeed 集成,在训练开始前输入 accelerate config 进行设置,根据提示选择 deepspeed zero stage 3,因为是 6 卡总计 144G 的 VRAM 做 lora 微调,offload optimizer states 可以选择 none, 不卸载优化器状态到内存。
- offload parameters 需要设置为 cpu,将参数量卸载到内存中,这样内存峰值占用最高可以到 240G 左右。gradient accumulation 需要和训练脚本保持一致,这里选择的是 4。gradient clipping 用来对误差梯度向量进行归一化,设置为 1 可以防止梯度爆炸。
- zero.init 可以进行 partitioned 并转换为半精度,加速模型初始化并使高参数的模型能够在 CPU 内存中全部进行分配。这里也可以选 yes。
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。
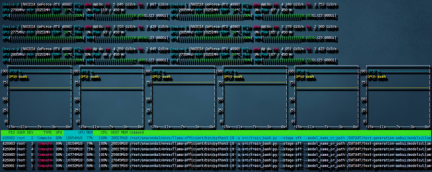
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
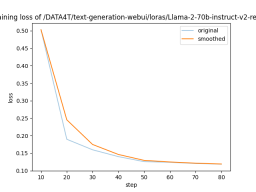
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
4.3微调完成后的测试效果
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
- 必应搜索
- 维基搜索
- bilibili 搜索
- 获取当前时间
- 保存文件
- ...
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
給定一段不在訓練集的複雜任務描述,同時在 toolkit 中加入訓練集中不包含的函數和對應描述。如果 planner 可以完成對任務進行拆分,distributor 可以呼叫函數,solver 可以根據整個流程對結果進行總結。
需要重新寫的內容是:2)測試結果
任務拆分:首先使用text-generation -webui 快速測試任務拆分模型的效果,如下圖所示:

#圖6 任務拆分測試結果
#這裡可以寫一個簡單的restful_api 接口,方便在agent 測試環境下的呼叫(請參閱專案程式碼fllama_api.py)。
函數呼叫:在專案中已經寫好了一個簡單的 planner-distributor-worker-solver 的邏輯。接下來就讓測試一下這個任務。輸入一段指令:what movies did the director of 'Killers of the Flower Moon' direct? List one of them and search it in bilibili.
「搜尋 bilibili 」這個函數是不包含在專案的函數呼叫訓練集中的。同時這部電影也是一部還沒上映的新電影,不確定模型本身的訓練資料有沒有包含。可以看到模型很好地將輸入指令進行拆分:
- 從維基百科上搜尋該電影的導演
- 根據1 的結果,從bing 搜尋電影Goodfellas 的結果
- 在bilibili 上搜尋電影Goodfellas
同時進行函數調用得到了以下結果:點擊結果是Goodfellas,和該部電影的導演配對得上。
總結
本專案以「輸入一段指令自動實現複雜任務拆分與函數呼叫」場景為例,設計了一套基本agent 流程:toolkit-plan-distribute-worker-solver 來實現一個可以執行無法一步完成的初級複雜任務的agent。透過基礎模型的選型和 lora 微調使得低算力條件下一樣可以完成大模型的微調和推理。並採用量化部署的方式,進一步降低推理的門檻。最後透過該 pipeline 實現了一個搜尋電影導演其他作品的範例,實現了基礎的複雜任務完成。
限制:本文只是基於搜尋和基本操作的 toolkit 設計了函數呼叫和任務拆分。使用的工具集非常簡單,並沒有太多設計。針對容錯機制也沒有太多考慮。透過本項目,大家也可以繼續向前一步探索 RPA 領域上的應用,進一步完善 agent 流程,實現更高程度的智慧自動化提升流程的可管理性。
以上是AI Agent 如何實現? 6張4090 魔改Llama2:一句指令拆分任務、呼叫函數的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Markitdown MCP可以將任何文檔轉換為Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP可以將任何文檔轉換為Markdowns!Apr 27, 2025 am 09:47 AM處理文檔不再只是在您的AI項目中打開文件,而是將混亂變成清晰度。諸如PDF,PowerPoints和Word之類的文檔以各種形狀和大小淹沒了我們的工作流程。檢索結構化
 如何使用Google ADK進行建築代理? - 分析VidhyaApr 27, 2025 am 09:42 AM
如何使用Google ADK進行建築代理? - 分析VidhyaApr 27, 2025 am 09:42 AM利用Google的代理開發套件(ADK)的力量創建具有現實世界功能的智能代理!該教程通過使用ADK來構建對話代理,並支持Gemini和GPT等各種語言模型。 w
 在LLM上使用SLM進行有效解決問題-Analytics VidhyaApr 27, 2025 am 09:27 AM
在LLM上使用SLM進行有效解決問題-Analytics VidhyaApr 27, 2025 am 09:27 AM摘要: 小型語言模型 (SLM) 專為效率而設計。在資源匱乏、實時性和隱私敏感的環境中,它們比大型語言模型 (LLM) 更勝一籌。 最適合專注型任務,尤其是在領域特異性、控制性和可解釋性比通用知識或創造力更重要的情況下。 SLM 並非 LLMs 的替代品,但在精度、速度和成本效益至關重要時,它們是理想之選。 技術幫助我們用更少的資源取得更多成就。它一直是推動者,而非驅動者。從蒸汽機時代到互聯網泡沫時期,技術的威力在於它幫助我們解決問題的程度。人工智能 (AI) 以及最近的生成式 AI 也不例
 如何將Google Gemini模型用於計算機視覺任務? - 分析VidhyaApr 27, 2025 am 09:26 AM
如何將Google Gemini模型用於計算機視覺任務? - 分析VidhyaApr 27, 2025 am 09:26 AM利用Google雙子座的力量用於計算機視覺:綜合指南 領先的AI聊天機器人Google Gemini擴展了其功能,超越了對話,以涵蓋強大的計算機視覺功能。 本指南詳細說明瞭如何利用
 Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好嗎?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好嗎?Apr 27, 2025 am 09:20 AM2025年的AI景觀正在充滿活力,而Google的Gemini 2.0 Flash和Openai的O4-Mini的到來。 這些尖端的車型分開了幾週,具有可比的高級功能和令人印象深刻的基準分數。這個深入的比較
 如何使用OpenAI GPT-Image-1 API生成和編輯圖像Apr 27, 2025 am 09:16 AM
如何使用OpenAI GPT-Image-1 API生成和編輯圖像Apr 27, 2025 am 09:16 AMOpenai的最新多模式模型GPT-Image-1徹底改變了Chatgpt和API的形像生成。 本文探討了其功能,用法和應用程序。 目錄 了解gpt-image-1 gpt-image-1的關鍵功能
 如何使用清潔行執行數據預處理? - 分析VidhyaApr 27, 2025 am 09:15 AM
如何使用清潔行執行數據預處理? - 分析VidhyaApr 27, 2025 am 09:15 AM數據預處理對於成功的機器學習至關重要,但是實際數據集通常包含錯誤。清潔行提供了一種有效的解決方案,它使用其Python軟件包來實施自信的學習算法。 它自動檢測和
 AI技能差距正在減慢供應鏈Apr 26, 2025 am 11:13 AM
AI技能差距正在減慢供應鏈Apr 26, 2025 am 11:13 AM經常使用“ AI-Ready勞動力”一詞,但是在供應鏈行業中確實意味著什麼? 供應鏈管理協會(ASCM)首席執行官安倍·埃什肯納齊(Abe Eshkenazi)表示,它表示能夠評論家的專業人員


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

Dreamweaver Mac版
視覺化網頁開發工具

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

WebStorm Mac版
好用的JavaScript開發工具

