



論文:https://arxiv.org/pdf/2309.03852.pdf
需要重寫的內容是:模型連結:https://huggingface.co/CofeAI/FLM-101B
語言本質上是符號的。已經有一些研究在使用符號而非類別標籤來評估 LLM 的智慧程度。類似地,團隊使用了一種符號映射方法來測試 LLM 在未曾見過的上下文上的泛化能力。
人類智慧的一大重要能力是理解給定的規則並採取相應的行動。這種測試方法已被廣泛地用在各種等級的測驗中。因此,規則理解成為這裡的第二項測試。
重寫後的內容:模式挖掘是智慧的重要組成部分,它涉及歸納和演繹。在科學發展歷史中,這種方法扮演著至關重要的角色。此外,各種競賽的測試題也常常需要這種能力才能解答。基於這些原因,我們選擇了模式挖掘作為第三個評估指標
最後一個也很重要的指標是抗干擾能力,這也是智慧的核心能力之一。已有研究指出,語言和影像都很容易被雜訊幹擾。考慮到這一點,團隊把抗干擾用作了最後一個評估指標。
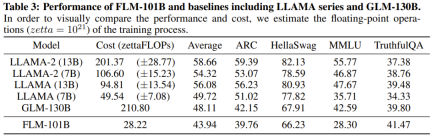
研究者表示,這是一個使用成長策略從頭開始訓練超過千億參數的LLM研究嘗試。同時,這也是目前成本最低的千億參數模型,只需10萬美元成本
#透過改進FreeLM 訓練目標、有潛力的超參數搜尋方法和功能保留型成長,這項研究解決了不穩定問題。研究者相信此方法也能為更廣大的科學研究社群提供助力。
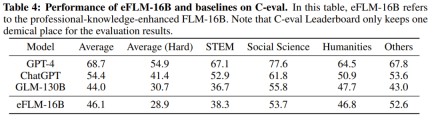
研究人員也對新模型與先前的強大模型進行了實驗比較,包括使用知識導向的基準和新提出的系統性IQ評估基準。實驗結果顯示,FLM-101B模型具有競爭力且穩健
團隊會發布模型檢查點、程式碼、相關工具等,以推進千億參數規模的漢語和英語雙語 LLM 的研究開發。
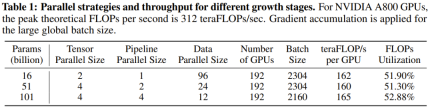
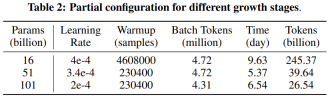
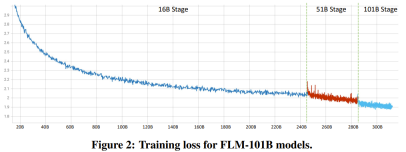




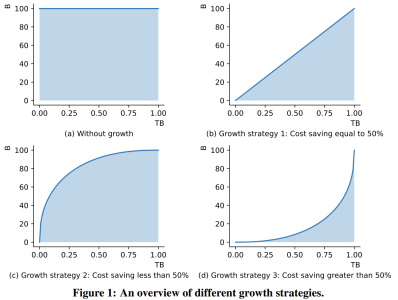
以上是10萬美元+26天,一個低成本千億參數LLM就誕生了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 潛在的醫療補助削減威脅孕產婦醫療保健Apr 17, 2025 am 11:18 AM
潛在的醫療補助削減威脅孕產婦醫療保健Apr 17, 2025 am 11:18 AM眾議院和參議院都同意在周末進行預算框架。該框架要求削減支出,以支付削減稅收的費用,這些減稅量不成比例,以防止赤字增加,同時也增加
 Snowflake首席執行官說,AI ROI始於正確獲取數據Apr 17, 2025 am 11:13 AM
Snowflake首席執行官說,AI ROI始於正確獲取數據Apr 17, 2025 am 11:13 AM雪花首席執行官在坐下來告訴我:“人工智能不應該是大爆炸。” “這應該是一系列小項目,顯示出每一步的價值。”但是,正如拉馬斯瓦米(Ramaswamy)指出的那樣,雖然這聽起來可能謹慎,但實際上是策略。 在中間
 每天上傳到Deezer的20,000個AI生成的歌曲Apr 17, 2025 am 11:11 AM
每天上傳到Deezer的20,000個AI生成的歌曲Apr 17, 2025 am 11:11 AMDeezer的首席創新官Aurelien Herault在一份聲明中說:“ AI產生的內容繼續傳到Deezer等洪水流媒體平台,我們沒有看到它放慢速度的跡象。” 儘管沒有減輕洪水的跡象,但Deezer確實有
 從體育場到場外:AI如何重塑體育的未來Apr 17, 2025 am 11:10 AM
從體育場到場外:AI如何重塑體育的未來Apr 17, 2025 am 11:10 AM這種轉變不再是理論上的。 卡夫集團(Kraft Group) - 新英格蘭愛國者隊,新英格蘭革命和吉列特體育場(Gillette Stadium)的所有者 - 剛剛宣布與NWN建立戰略合作夥伴關係,以現代化和轉變KR的技術
 什麼是及時工程中的問題鏈? - 分析VidhyaApr 17, 2025 am 11:06 AM
什麼是及時工程中的問題鏈? - 分析VidhyaApr 17, 2025 am 11:06 AM問題鏈:革命性及時工程 想像一下與AI的對話,每個問題都基於上一個問題,從而導致越來越有見地的答案。這是及時工程中的問題鏈(COQ)的力量
 訪問Mistral Nemo:功能,應用程序和含義Apr 17, 2025 am 11:04 AM
訪問Mistral Nemo:功能,應用程序和含義Apr 17, 2025 am 11:04 AMMistral Nemo:強大的開源多語言LLM Mistral AI和Nvidia的合作努力Mismtral Nemo是一種尖端的開源大語模型(LLM),提供最先進的自然語言處理。 這120億桿
 Excel中的回合功能是什麼? - 分析VidhyaApr 17, 2025 am 10:56 AM
Excel中的回合功能是什麼? - 分析VidhyaApr 17, 2025 am 10:56 AM掌握Microsoft Excel的圓形功能,以獲得精確的數值數據 數字是電子表格的基礎,但是實現準確性和可讀性通常不僅需要原始數據。 Microsoft Excel的圓形功能是TRA的強大工具
 使用LlamainDex的反射劑指南Apr 17, 2025 am 10:41 AM
使用LlamainDex的反射劑指南Apr 17, 2025 am 10:41 AM增強AI智能:深入研究LlamainDex的反射性AI代理 想像一個AI不僅可以解決問題,而且還反映了自己的改進思維過程。這是反光AI代理的領域,本文探討了


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

WebStorm Mac版
好用的JavaScript開發工具

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

