
Salesforce與MIT研究者合作開源GPT-4改稿教程,實現更少字數卻傳遞更多訊息

- 王林轉載
- 2023-09-19 20:33:13919瀏覽
自动摘要技术近年来取得了显著的进步,这主要得益于范式的转变。过去,该技术主要依赖于在标注数据集上进行有监督微调,但现在则采用了大语言模型(LLM)进行零样本 prompt,例如GPT-4。通过细致的 prompt 设置,不需要额外的训练,就能实现对摘要长度、主题、风格等方面特征的精细控制
但一个方面常常被忽视:摘要的信息密度。从理论上讲,作为对另一个文本的压缩,摘要应该比源文件更密集,也就是包含更多的信息。考虑到 LLM 解码的高延迟,用更少的字数涵盖更多的信息非常重要,尤其是对于实时应用而言。
然而,信息量密度是一个开放式的问题:如果摘要包含的细节不足,那么相当于没有信息量;如果包含的信息过多,又不增加总长度,就会变得难以理解。要在固定的 token 预算内传递更多信息,就需要将抽象、压缩、融合三者结合起来。
在最近的研究中,来自Salesforce、MIT等机构的研究者试图通过征求人类对GPT-4生成的一组摘要的偏好来确定其密度逐渐增加的限制。这种方法为提升GPT-4等大型语言模型的"表达能力"提供了许多启示

论文链接:https://arxiv.org/pdf/2309.04269.pdf
数据集地址:https://huggingface.co/datasets/griffin/chain_of_density
具体来说,研究者们通过将每个令牌的平均实体数量作为密度的代表,生成了一个初始的、实体稀少的摘要。然后,在不增加总长度(总长度为5倍)的情况下,他们反复识别并融合前一个摘要中缺失的1-3个实体。每个摘要的实体与令牌比例都高于前一个摘要。根据人类的偏好数据,作者最终确定,人类更喜欢几乎与人类编写的摘要一样密集的摘要,而且比普通GPT-4提示生成的摘要更密集
该研究的总体贡献可以概括为以下几点:
我们需要开发一种基于 prompt 的迭代方法(CoD),以提高摘要的实体密度
对CNN/《每日邮报》文章中摘要的密集程度进行人工和自动评估,以更好地了解信息量(倾向于更多实体)和清晰度(倾向于更少实体)之间的权衡
开源了 GPT-4 摘要、注释和一组 5000 篇未注释的 CoD 摘要,用于评估或提炼。
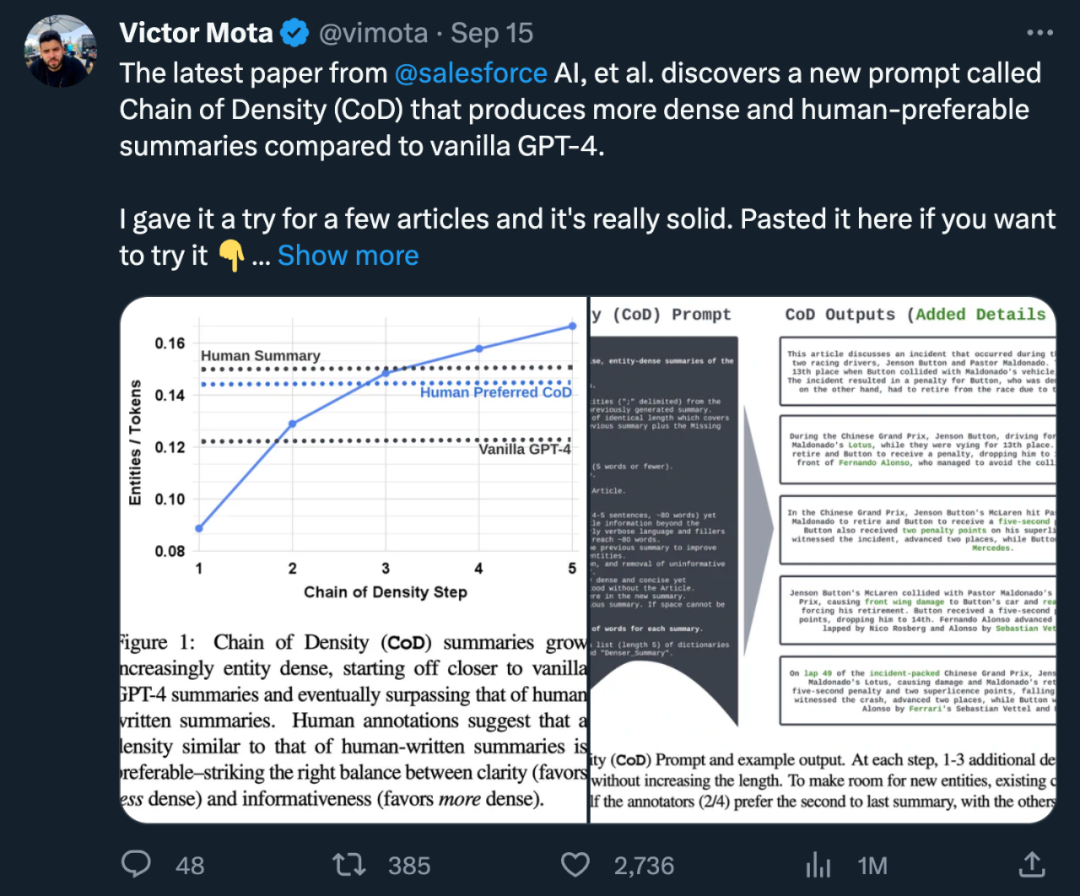
CoD 是什么意思?
作者制定了一个单一的密度链(CoD)Prompt,即生成一个初始摘要,并使其实体密度不断增加。具体来说,在一个固定的交互次数中,源文本中一组独特的突出实体被识别出来,并在不增加长度的情况下融合到之前的摘要中。
在图2中展示了提示和输出示例。作者并没有明确指定实体的类型,而是将缺失的实体定义为:
与主要故事有关:
具体:简明扼要(5个字或更少);
独特:在之前的摘要中没有提及过;
忠实:存在于文章中;
任何地方:位于文章的任何地方。

作者从 CNN/DailyMail 摘要测试集中随机抽取了 100 篇文章,为其生成 CoD 摘要。为便于参考,他们将 CoD 摘要统计数据与人类撰写的要点式参考摘要以及 GPT-4 在普通 Prompt 下生成的摘要进行比较:「写一篇非常简短的文章摘要。请勿超过 70 个字。」
统计情况
在研究中,作者从直接统计数据和间接统计数据两方面进行了总结。直接统计数据(token、实体、实体密度)由 CoD 直接控制,而间接统计数据则是密集化的预期副产品。
直接統計資料。如表 1 所示,由於從最初冗長的摘要中刪除了不必要的詞語,第二步平均減少了 5 個 token(從 72 到 67)的長度。實體密度從 0.089 開始,最初低於人類和 Vanilla GPT-4(0.151 和 0.122),經過 5 步密集化後,最終上升到 0.167。 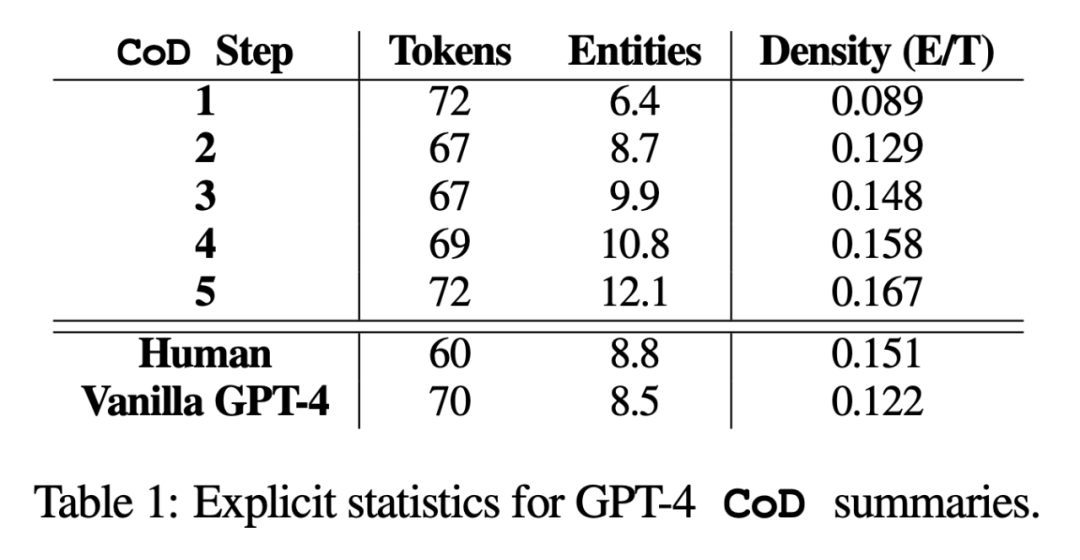 間接統計。抽象度應該會隨著每一步 CoD 的進行而增加,因為每增加一個實體,摘要就會被反覆改寫以騰出空間。作者以萃取密度來衡量抽象性:萃取片段的平均平方長度 (Grusky et al., 2018)。同樣,隨著實體被添加到固定長度的摘要中,概念融合度也應隨之單調增加。作者用與每個摘要句子對齊的來源句子的平均數量來表示融合度。在對齊上,作者使用相對 ROUGE 增益法 (Zhou et al., 2018),,該方法將源句與目標句對齊,直到額外句子的相對 ROUGE 增益不再為正。他們也預期內容分佈(Content Distribution),也就是摘要內容所來源的文章中位置,會有所改變。
間接統計。抽象度應該會隨著每一步 CoD 的進行而增加,因為每增加一個實體,摘要就會被反覆改寫以騰出空間。作者以萃取密度來衡量抽象性:萃取片段的平均平方長度 (Grusky et al., 2018)。同樣,隨著實體被添加到固定長度的摘要中,概念融合度也應隨之單調增加。作者用與每個摘要句子對齊的來源句子的平均數量來表示融合度。在對齊上,作者使用相對 ROUGE 增益法 (Zhou et al., 2018),,該方法將源句與目標句對齊,直到額外句子的相對 ROUGE 增益不再為正。他們也預期內容分佈(Content Distribution),也就是摘要內容所來源的文章中位置,會有所改變。
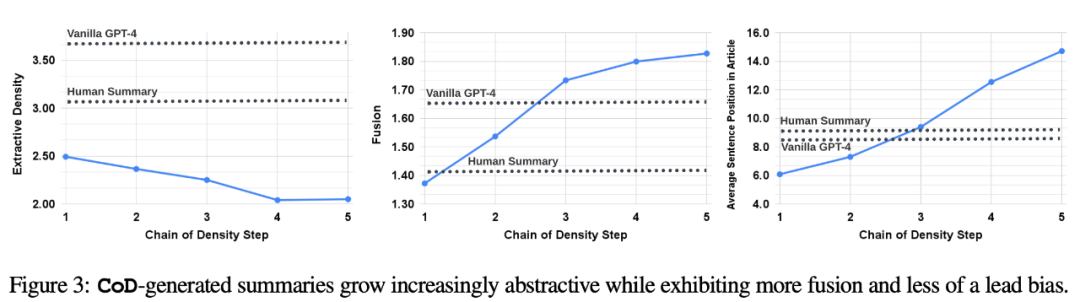
具體來說,作者預期 CoD 摘要最初會表現出強烈的「引導偏向」(Lead Bias),但隨後會逐漸開始從文章的中間和末尾引入實體。為了測量這一點,他們使用了融合中的對齊重寫內容時,需要使用中文進行重寫,不需要出現原句,並測量了所有對齊源句的平均句子等級。
圖3證實了這些假設:隨著重寫步驟的增加,抽象性也增加(左圖顯示提取密度較低),融合率也上升(中圖顯示),摘要開始包含文章中間和末尾的內容(右圖顯示)。有趣的是,與人類撰寫的摘要和基準摘要相比,所有CoD摘要都更加抽象
#重寫內容時,需要使用中文進行重寫,不需要出現原句
為了更好地理解CoD 摘要的tradeoff,作者開展了一項基於偏好的人類研究,並使用GPT-4 進行了基於評級的評估。
人類偏好。具體來說,對於同樣的 100 篇文章(5 個 step *100 = 總共 500 篇摘要),作者向論文的前四位作者隨機展示了經過“重新創作”的 CoD 摘要以及文章。根據 Stiennon et al. (2020) 對「好摘要」的定義,每位註釋者都給出了自己最喜歡的摘要。表 2 報告了各註釋者在 CoD 階段的第一名得票情況,以及各註釋者的總結情況。總的來說,61% 的第一名摘要(23.0 22.5 15.5)涉及≥3 個緻密化步驟。首選 CoD 步數的中位數位於中間(3),預期步數為 3.06。
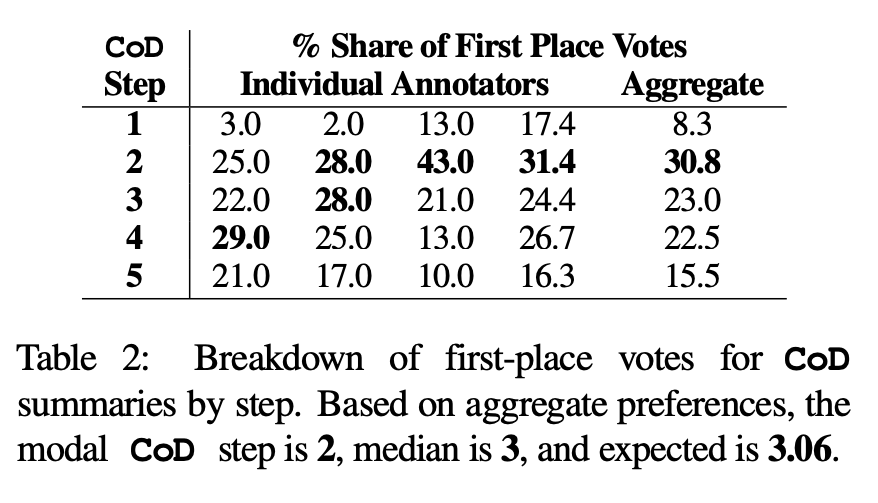
根據第三步驟的平均密度推測,所有CoD候選者的首選實體密度約為0.15。從表1可以看出,這個密度與人類編寫的摘要(0.151)一致,但明顯高於用普通GPT-4 Prompt編寫的摘要(0.122)
自動度量。作為人工評估的補充(如下),作者以 GPT-4 從 5 個維度對 CoD 摘要進行評分(1-5 分):資訊量、品質、連貫性、可歸屬性和整體性。如表 3 所示,密集度與資訊量相關,但有一個限度,在步驟 4(4.74)時得分達到頂峰。
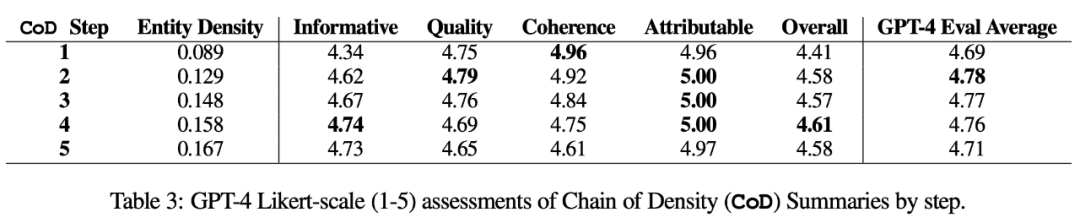
從各維度的平均分數來看,CoD 的第一個和最後一個步驟得分最低,而中間三個步驟得分接近(分別為4.78、4.77 和4.76)。
定性分析。摘要的連貫性 / 可讀性與資訊量之間存在著明顯的 trade-off。圖 4 中展示了兩個 CoD 步驟:一個步驟的摘要因更多細節而得到改善,另一個步驟的摘要則受到損害。平均而言,中間 CoD 摘要最能達到這種平衡,但這種 tradeoff 仍需在未來的工作中去精確定義和量化。
 更多論文細節,可參考原文。
更多論文細節,可參考原文。
以上是Salesforce與MIT研究者合作開源GPT-4改稿教程,實現更少字數卻傳遞更多訊息的詳細內容。更多資訊請關注PHP中文網其他相關文章!