




字串是一個對象,它表示資料字元的序列。字串是始終表示為文字格式的資料容器。它也用於概念、比較、拆分、連接、替換、修剪、長度、實習、等於、比較、子字串操作。使用快速排序分區演算法的陣列中的 K 個最大(或最小)元素。
這是一個陣列 R[],其中包含 N 個不同的整數。任務是找到那個特定元素,該元素嚴格大於其前面的所有元素,並且嚴格大於其右側的至少 K 個元素。該問題指出,一個由N 個不同元素和整數K 組成的數組arr[ ](數組R);我們必須找出比其左側所有元素都大的元素個數,並且其右側至少有K 個元素。
Input: R[] = {16,07,10,22,2001,1997}, K = 3
Output: 16
Therefore, the count is 2.
有兩種方法可以找出大於左側所有元素且右側至少 K 個元素的陣列元素。
樸素方法 - 這是遍歷特定陣列最簡單的方法。在這個方法中,我們必須向左遍歷所有元素來檢查它是否較小。否則,向右遍歷,檢查最小的 K 個元素是否較小。對於這種方法,時間複雜度為 O(N2),輔助空間為 O(1)。
高效率方法 - 這是一個可以透過自平衡 BST 完成的最佳化過程。透過AVL Tree從右向左一一遍歷數組。 AVL Tree 產生一個陣列 countSmaller[]。這裡時間複雜度是O(NlogN),輔助空間是O(N)。對於滿足滿足條件的每個元素,增加計數。
讓我們找出陣列元素的數量大於其左側所有元素且右側至少有 K 個元素。
計算大於所有元素的陣列元素的演算法:-
在此演算法中,我們將按照一步一步的過程來計算陣列元素的數量。透過這個,我們將建立一些 C 程式碼來找到所有元素中最大的元素。
第 1 步 - 開始。
第 2 步 - 從右向左遍歷陣列。
第 3 步 - 將所有元素插入 AVL 樹。
第 4 步 - 透過使用 AVL 樹產生陣列 countSmaller[]。
第 5 步 - 它包含每個陣列元素右側較小元素的計數。
第 6 步 - 遍歷陣列並尋找每個元素。
第 7 步 - 檢查是否是迄今為止獲得的最大值,並且 countSmaller[i] 是否大於或等於 K。
第 8 步 - 如果滿足條件,則增加計數。
第 9 步 - 列印 count 的最終值作為答案。
第 10 步 - 終止。
文法
for (i = k; i < array.length; i++){
minIndex = 0;
for (int j = 0; j < k; j++){
if(array[j] < array[minIndex]){
minIndex = j;
array[minIndex] = array[j];
}
}
if (array[minIndex] < array[i]){
int temp = array[minIndex];
array[minIndex] = array[i];
array[i] = temp;
}
這裡是一個整數陣列num,整數為K。它將傳回數組中的第K個元素。我們必須以 O(n) 的時間複雜度來解決它。
方法
方法 1 - 使用排序尋找 K 個最大(或最小)元素。
方法 2 - 找出陣列中 K 最大(或最小)元素的有效方法。
使用排序來找出 K 最大(或最小)元素
透過排序的方法我們可以得到這個問題的結果。以下是步驟 -
元素降序排序。
列印該排序數組中的前 K 個數字。
範例 1
#include <bits/stdc++.h>
using namespace std;
void kLargest(int arr[], int a, int b){
sort(arr, arr + a, greater<int>());
for (int i = 0; i < b; i++)
cout << arr[i] << " ";
}
int main(){
int arr[] = { 10, 16, 07, 2001, 1997, 2022, 50 };
int n = sizeof(arr) / sizeof(arr[0]);
int k = 3;
kLargest(arr, n, k);
}
</int>
輸出
2022 2001 1997
找出陣列中 K 個最大(或最小)元素的有效方法
在此方法中,我們將按照以下步驟找出結果 -
開始。
從右向左遍歷陣列。
插入 AVL 樹中的所有元素。
產生陣列 countSmaller[]。
每個陣列元素右側較小元素的計數。
如果是最大值,則countSmaller[i]大於等於K。
然後增加計數。
列印該值。
結束。
範例 2
#include <bits/stdc++.h>
using namespace std;
struct node {
int key;
struct node* left;
struct node* right;
int height;
int size;
};
int max(int a, int b);
int height(struct node* N){
if (N == NULL)
return 0;
return N->height;
}
int size(struct node* N){
if (N == NULL)
return 0;
return N->size;
}
int max(int a, int b){
return (a > b) ? a : b;
}
struct node* newNode(int key){
struct node* node
= (struct node*)
malloc(sizeof(struct node));
node->key = key;
node->left = NULL;
node->right = NULL;
node->height = 1;
node->size = 1;
return (node);
}
struct node* rightRotate(struct node* y){
struct node* x = y->left;
struct node* T2 = x->right;
x->right = y;
y->left = T2;
y->height = max(height(y->left),
height(y->right))
+ 1;
x->height = max(height(x->left),
height(x->right))
+ 1;
y->size = size(y->left)
+ size(y->right) + 1;
x->size = size(x->left)
+ size(x->right) + 1;
return x;
}
struct node* leftRotate(struct node* x){
struct node* y = x->right;
struct node* T2 = y->left;
y->left = x;
x->right = T2;
x->height = max(height(x->left),
height(x->right))
+ 1;
y->height = max(height(y->left),
height(y->right))
+ 1;
x->size = size(x->left)
+ size(x->right) + 1;
y->size = size(y->left)
+ size(y->right) + 1;
return y;
}
int getBalance(struct node* N){
if (N == NULL)
return 0;
return height(N->left)
- height(N->right);
}
struct node* insert(struct node* node, int key,
int* count){
if (node == NULL)
return (newNode(key));
if (key < node->key)
node->left = insert(node->left, key, count);
else {
node->right = insert(node->right, key, count);
*count = *count + size(node->left) + 1;
}
node->height = max(height(node->left),
height(node->right))
+ 1;
node->size = size(node->left)
+ size(node->right) + 1;
int balance = getBalance(node);
if (balance > 1 && key < node->left->key)
return rightRotate(node);
if (balance < -1 && key > node->right->key)
return leftRotate(node);
if (balance > 1 && key > node->left->key) {
node->left = leftRotate(node->left);
return rightRotate(node);
}
if (balance < -1 && key < node->right->key) {
node->right = rightRotate(node->right);
return leftRotate(node);
}
return node;
}
void constructLowerArray(int arr[],
int countSmaller[],
int n){
int i, j;
struct node* root = NULL;
for (i = 0; i < n; i++)
countSmaller[i] = 0;
for (i = n - 1; i >= 0; i--) {
root = insert(root, arr[i], &countSmaller[i]);
}
}
int countElements(int A[], int n, int K){
int count = 0;
int* countSmaller = (int*)malloc(sizeof(int) * n);
constructLowerArray(A, countSmaller, n);
int maxi = INT_MIN;
for (int i = 0; i <= (n - K - 1); i++) {
if (A[i] > maxi && countSmaller[i] >= K) {
count++;
maxi = A[i];
}
}
return count;
}
int main(){
int A[] = { 16, 10, 2022, 1997, 7, 2001, 0 };
int n = sizeof(A) / sizeof(int);
int K = 3;
cout << countElements(A, n, K);
return 0;
}
輸出
2
結論
這樣我們就知道如何寫 C 程式碼來計算陣列元素的數量大於其左側所有元素且右側至少有 K 個元素。
以上是C++程序,用於計算數組元素大於其左側所有元素且至少有K個元素在其右側的數量的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 MySQL中如何使用SUM函数计算某个字段的总和Jul 13, 2023 pm 10:12 PM
MySQL中如何使用SUM函数计算某个字段的总和Jul 13, 2023 pm 10:12 PMMySQL中如何使用SUM函数计算某个字段的总和在MySQL数据库中,SUM函数是一个非常有用的聚合函数,它可以用于计算某个字段的总和。本文将介绍如何在MySQL中使用SUM函数,并提供一些代码示例来帮助读者深入理解。首先,让我们看一个简单的示例。假设我们有一个名为"orders"的表,其中包含了顾客的订单信息。表结构如下:CREATETABLEorde
 新研究揭示量子蒙特卡洛超越神经网络在突破限制方面的潜力,Nature子刊详述最新进展Apr 24, 2023 pm 09:16 PM
新研究揭示量子蒙特卡洛超越神经网络在突破限制方面的潜力,Nature子刊详述最新进展Apr 24, 2023 pm 09:16 PM时隔四个月,ByteDanceResearch与北京大学物理学院陈基课题组又一合作工作登上国际顶级刊物NatureCommunications:论文《TowardsthegroundstateofmoleculesviadiffusionMonteCarloonneuralnetworks》将神经网络与扩散蒙特卡洛方法结合,大幅提升神经网络方法在量子化学相关任务上的计算精度、效率以及体系规模,成为最新SOTA。论文链接:https://www.nature.com
 计算矩阵右对角线元素之和的Python程序Aug 19, 2023 am 11:29 AM
计算矩阵右对角线元素之和的Python程序Aug 19, 2023 am 11:29 AM一种受欢迎的通用编程语言是Python。它被应用于各种行业,包括桌面应用程序、网页开发和机器学习。幸运的是,Python具有简单易懂的语法,适合初学者使用。在本文中,我们将使用Python来计算矩阵的右对角线之和。什么是矩阵?在数学中,我们使用一个矩形排列或矩阵,用于描述一个数学对象或其属性,它是一个包含数字、符号或表达式的矩形数组或表格,这些数字、符号或表达式按行和列排列。例如−234512367574因此,这是一个有3行4列的矩阵,表示为3*4矩阵。现在,矩阵中有两条对角线,即主对角线和次对
 Nature刊登量子计算重大进展:有史以来第一个量子集成电路实现Apr 08, 2023 pm 09:01 PM
Nature刊登量子计算重大进展:有史以来第一个量子集成电路实现Apr 08, 2023 pm 09:01 PM6 月 23 日,澳大利亚量子计算公司 SQC(Silicon Quantum Computing)宣布推出世界上第一个量子集成电路。这是一个包含经典计算机芯片上所有基本组件的电路,但体量是在量子尺度上。SQC 团队使用这种量子处理器准确地模拟了一个有机聚乙炔分子的量子态——最终证明了新量子系统建模技术的有效性。「这是一个重大突破,」SQC 创始人 Michelle Simmons 说道。由于原子之间可能存在大量相互作用,如今的经典计算机甚至难以模拟相对较小的分子。SQC 原子级电路技术的开发将
 Michael Bronstein从代数拓扑学取经,提出了一种新的图神经网络计算结构!Apr 09, 2023 pm 10:11 PM
Michael Bronstein从代数拓扑学取经,提出了一种新的图神经网络计算结构!Apr 09, 2023 pm 10:11 PM本文由Cristian Bodnar 和Fabrizio Frasca 合著,以 C. Bodnar 、F. Frasca 等人发表于2021 ICML《Weisfeiler and Lehman Go Topological: 信息传递简单网络》和2021 NeurIPS 《Weisfeiler and Lehman Go Cellular: CW 网络》论文为参考。本文仅是通过微分几何学和代数拓扑学的视角讨论图神经网络系列的部分内容。从计算机网络到大型强子对撞机中的粒子相互作用,图可以用来模
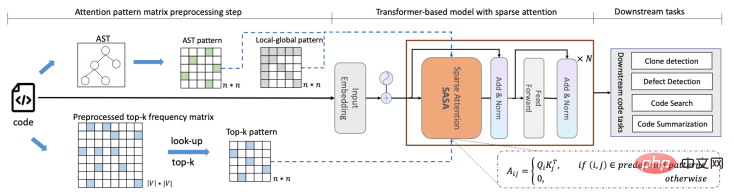 面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能Apr 29, 2023 am 08:34 AM
面向长代码序列的 Transformer 模型优化方法,提升长代码场景性能Apr 29, 2023 am 08:34 AM阿里云机器学习平台PAI与华东师范大学高明教授团队合作在SIGIR2022上发表了结构感知的稀疏注意力Transformer模型SASA,这是面向长代码序列的Transformer模型优化方法,致力于提升长代码场景下的效果和性能。由于self-attention模块的复杂度随序列长度呈次方增长,多数编程预训练语言模型(Programming-basedPretrainedLanguageModels,PPLM)采用序列截断的方式处理代码序列。SASA方法将self-attention的计算稀疏化
 使用Python的abs()函数计算数值的绝对值Aug 22, 2023 pm 12:07 PM
使用Python的abs()函数计算数值的绝对值Aug 22, 2023 pm 12:07 PM使用Python的abs()函数计算数值的绝对值绝对值是一个数与零点的距离,无论这个数是正数还是负数,其绝对值都是非负数。在Python中,我们可以使用内置函数abs()来计算一个数的绝对值。本文将详细介绍abs()函数的使用方法,并给出一些代码示例。abs()函数的语法如下:abs(x)其中,x是需要计算绝对值的数值。下面是一些使用abs()函数的示例:示
 清华大学类脑芯片天机芯X登Science子刊封面,机器人版猫捉老鼠上演Apr 14, 2023 pm 05:01 PM
清华大学类脑芯片天机芯X登Science子刊封面,机器人版猫捉老鼠上演Apr 14, 2023 pm 05:01 PM清华大学举办的一场机器人版猫捉老鼠游戏,登上了Science子刊封面。这里的汤姆猫有了新的名字:“天机猫”,它搭载了清华大学类脑芯片的最新研究成果——一款名为TianjicX的28nm神经形态计算芯片。它的任务是抓住一只随机奔跑的电子老鼠:在复杂的动态环境下,各种障碍被随机地、动态地放置在不同的位置,“天机猫”需要通过视觉识别、声音跟踪或两者结合的方式来追踪老鼠,然后在不与障碍物碰撞的情况下向老鼠移动,最终追上它。在此过程中,“天机猫”需要实现实时场景下的语音识别、声源定位、目标检测、避障和决


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

Dreamweaver Mac版
視覺化網頁開發工具

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

記事本++7.3.1
好用且免費的程式碼編輯器

