
發掘資料潛力:微美全像推出基於人工智慧機器學習的多視角融合演算法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-09-17 14:37:051361瀏覽
隨著網路和資訊科技的快速發展,資料的多樣性和複雜性越來越高。多模態資料的興起,如圖像、文字、音訊等多種資料形式的廣泛應用,傳統的單一視圖演算法難以充分利用多種資料來源所提供的信息,也難以有效地處理不同類型的資料。為了解決這些問題,微美全像(NASDAQ:WIMI)將機器學習演算法應用於影像融合領域,推出了基於人工智慧機器學習的多視圖融合演算法
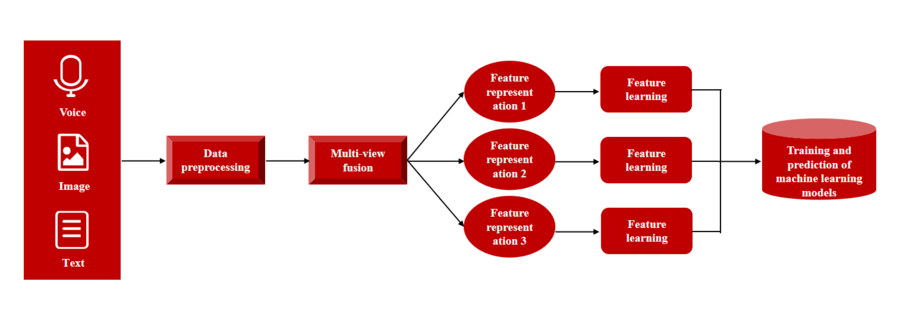
基於人工智慧機器學習的多視圖融合演算法是指利用機器學習技術,從不同視角或資訊來源中獲取的多個視圖進行聯合學習和融合的演算法。由於在分類問題、特徵提取、資料表示等方面表現出強大的性能,機器學習演算法在許多電腦視覺和影像處理任務上都取得了較好的效果。在多視圖融合演算法中,可以將不同視圖的特徵進行組合,以獲得更全面且準確的資訊。同時,還可以將不同視圖的資訊進行融合,提高資料分析和預測的準確性,另外還可以同時處理多種資料類型,更好地挖掘資料的潛在資訊。 WIMI微美全像研究的多視圖融合演算法通常包括資料預處理、多視圖融合、特徵學習、模型訓練和預測等步驟
資料預處理是多視圖演算法的第一步,用於確保資料的品質和一致性。對每個視圖的資料進行預處理,包括資料清洗、特徵選擇、特徵提取和資料歸一化等步驟。這些步驟旨在去除雜訊、減少冗餘訊息,並提取出對於演算法效能有重要影響的特徵
多視圖融合:接下來,我們將對經過預處理的多個視圖進行融合。融合的方法可以是簡單的加權平均,也可以是更複雜的模型整合方法,例如神經網路。透過融合不同視圖的信息,我們能夠綜合考慮各個視圖的優勢,從而提高演算法的效能
特徵學習和表示學習在多視圖演算法中扮演重要的角色。透過學習特徵和表示,可以更好地捕捉資料中的隱藏模式和結構,從而提高演算法的準確性和泛化能力。常見的特徵學習方法包括主成分分析和自編碼器等
模型訓練與預測:最後,使用經過特徵學習和表示學習的數據,訓練機器學習模型,以學習多視圖資料之間的關聯關係。常用的機器學習模型包括支援向量機(SVM)、決策樹、深度神經網路等。透過訓練得到的模型,可以進行預測和分類任務,如可以使用訓練好的模型對新的輸入資料進行預測和評估
基於人工智慧機器學習的多視圖融合演算法具有資料豐富性、資訊互補性、模型融合能力、穩健性、自適應性等技術優勢。這些優勢使得多視圖演算法在處理複雜問題和多源資料分析中具有很大的潛力和應用價值
每個多視圖資料中的視圖都提供了不同類型的多樣化數據,例如文字、圖像、聲音等。每種類型的數據都有其獨特的特徵和表達方式,這些資訊可以相互補充和增強。透過將不同視圖的資訊融合在一起,可以獲得更全面、更準確的特徵表示,提高資料分析和模型訓練的效能,得到更準確和全面的結果,以更全面地理解和分析問題。此外,將來自不同視圖的模型進行整合,可以獲得更強大的模型能力,提高整體模型的效能
多視圖融合演算法能夠更好地處理資料中的雜訊和異常情況。透過利用多個視圖的信息,減少單一視圖中的干擾,從而提高演算法對雜訊和異常資料的穩健性。此外,該演算法還能根據不同的任務和資料特點,自適應地選擇合適的視圖和模型進行學習和預測。這種自適應性可以提高演算法的適應能力和泛化能力
多元視圖融合演算法在影像處理、數位行銷、社群媒體和物聯網等領域都有廣泛的應用。透過從不同視角收集數據,並將其融合在一起,可以更準確地進行廣告推薦和智慧化應用。在數位行銷領域,多視圖融合演算法可以利用來自使用者行為、使用者屬性和物品屬性等多個視圖,綜合利用多種資訊來提高數位行銷的效果。例如,可以將使用者行為資料、使用者畫像資料和物品屬性資料進行整合,提高個人化推薦、廣告推薦和資訊過濾等任務的準確性和個人化程度。在物聯網領域,多視圖融合演算法可以應用於智慧家庭和智慧城市,透過從不同視角收集感測器數據、環境數據和用戶數據,並將其融合在一起,可以更準確地實現智慧家庭和智慧城市的管理。在影像處理領域,多視圖融合演算法可以利用來自不同感測器、相機或影像處理技術獲得的多個視圖,綜合利用多種資訊來提高影像的處理效果。例如,可以將來自不同光譜、解析度或角度的影像進行融合,提高影像的品質、增強細節、改善分類或目標偵測等任務的效能
隨著大數據和人工智慧技術的發展,未來,WIMI微美全像將持續推進多視圖融合演算法的技術創新,融合深度神經網路、跨模態學習等技術,更深度地整合深度神經網絡等技術,對多視圖資料進行深層的特徵提取與融合,提高演算法的效能與效果。並實現對不同模態資料的有效融合與分析
以上是發掘資料潛力:微美全像推出基於人工智慧機器學習的多視角融合演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!