
用於光達點雲自監督預訓練SOTA!

- 王林轉載
- 2023-09-15 09:53:071409瀏覽

論文想法:
masked autoencoding已經成為文字、圖像和最近的點雲的Transformer模型的一個成功的預訓練範例。原始的汽車資料集適合進行自監督的預訓練,因為與3D目標偵測(OD)等任務的標註相比,它們的收集成本通常較低。然而,針對點雲的masked autoencoders的開發僅僅集中在合成和室內數據上。因此,現有的方法已經將它們的表示和模型定制為小而稠密的點雲,具有均勻的點密度。在這項工作中,本文研究了在汽車設定中對點雲進行的masked autoencoding,這些點雲是稀疏的,並且在同一場景中,點雲的密度在不同的物體之間可以有很大的變化。為此,本文提出了Voxel-MAE,這是一種為體素表示而設計的簡單的masked autoencoding預訓練方案。本文對基於Transformer三維目標偵測器的主幹進行了預訓練,以重建masked體素並區分空體素和非空體素。本文的方法提高了具有挑戰性的nuScenes資料集上1.75 mAP和1.05 NDS的3D OD效能。此外,本文表明,透過使用Voxel-MAE進行預訓練,本文只需要40%的註釋資料就可以超過隨機初始化的等效資料。
主要貢獻:
本文提出了Voxel-MAE(一種在體素化的點雲上部署MAE-style的自監督預訓練的方法) ,並在大型汽車點雲資料集nuScenes上對其進行了評估。本文的方法是第一個使用汽車點雲Transformer主幹的自我監督預訓練方案。
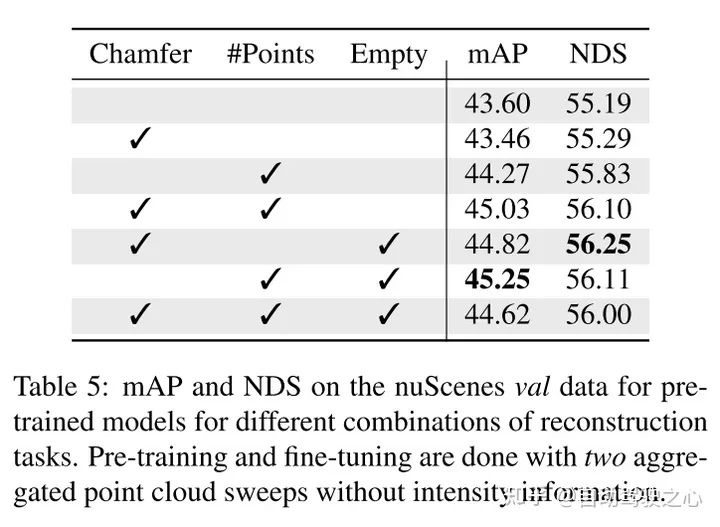
本文針對體素表示定製本文的方法,並使用一組獨特的重建任務來捕捉體素化點雲的特徵。
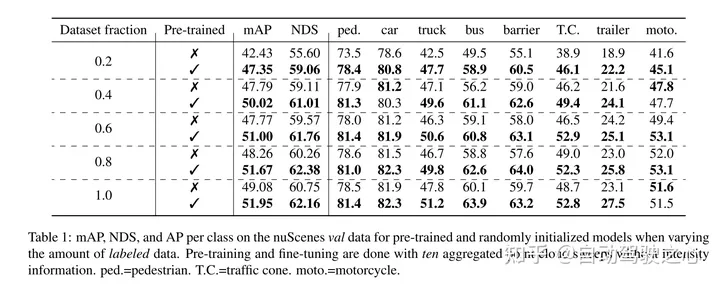
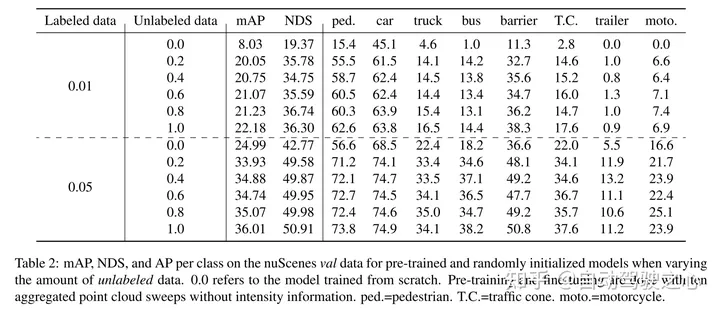
本文證明了本文的方法資料高效,並且減少了對註解資料的需求。透過預訓練,當只使用40%的註釋的資料時,本文的表現優於全監督的資料。
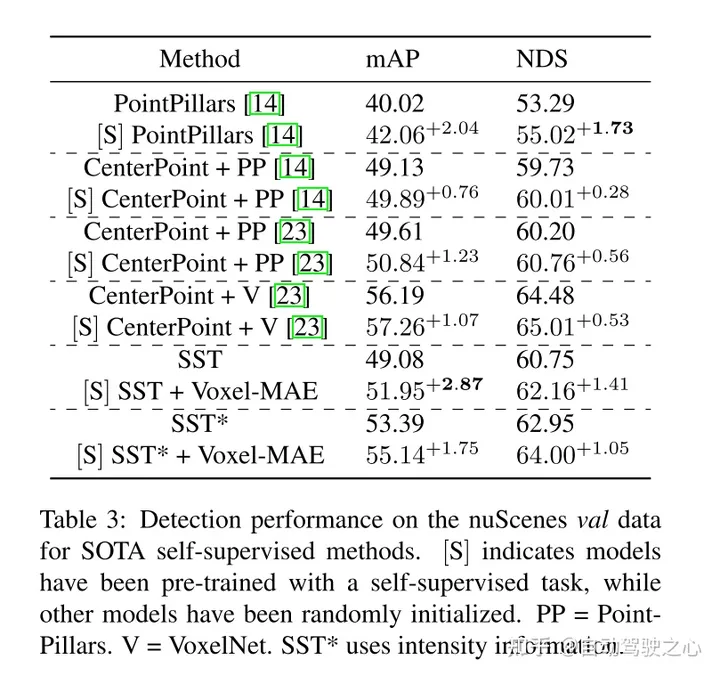
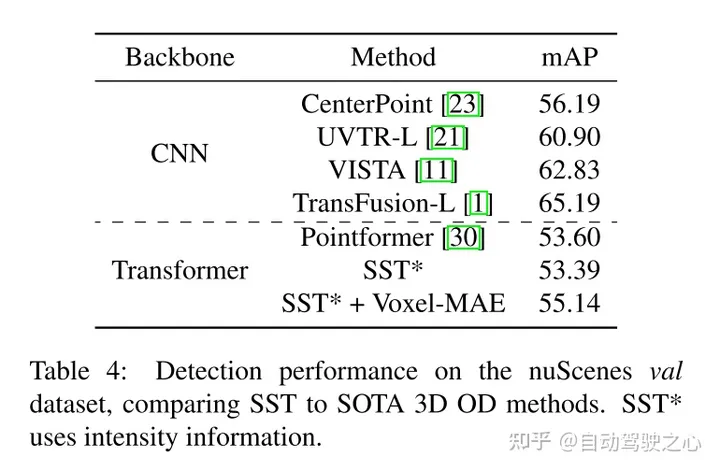
此外,本文發現Voxel-MAE在mAP中將基於Transformer檢測器的性能提高了1.75個百分點,在NDS中將其性能提高了1.05個百分點,與現有的自監督方法相比,其性能提高了2倍。
網路設計:
這項工作的目的是將MAE-style的預訓練擴展到體素化的點雲。核心思想仍然是使用編碼器從對輸入的部分觀察中創建豐富的潛在表示,然後使用解碼器重構原始輸入,如圖2所示。經過預訓練後,編碼器被用作3D目標偵測器的主幹。但是,由於影像和點雲之間的基本差異,需要對Voxel-MAE的有效訓練進行一些修改。
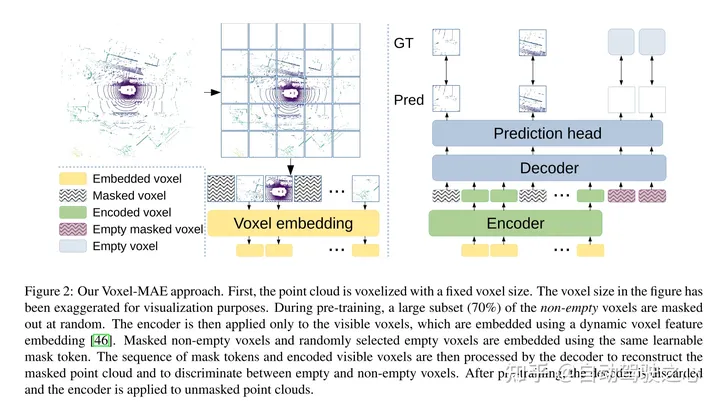
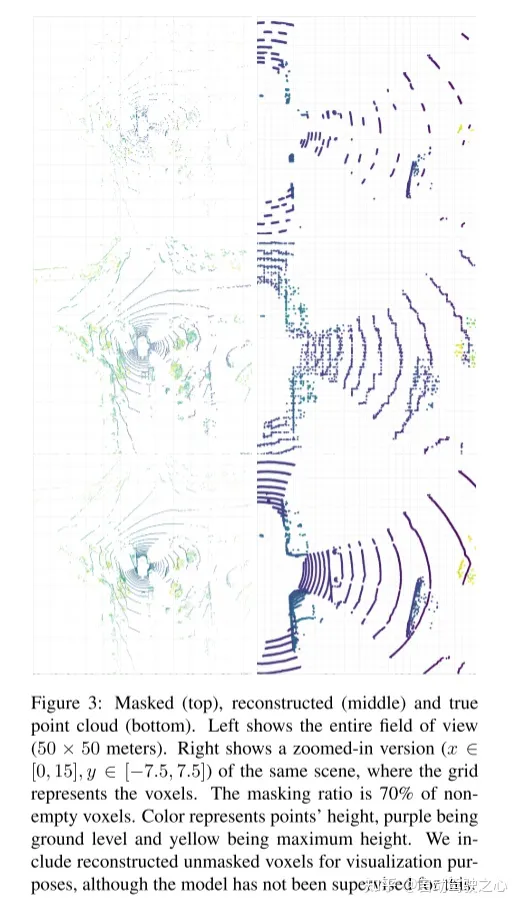
圖2:本文的Voxel-MAE方法。首先,用固定的體素大小對點雲進行體素化。圖中的體素大小已被誇大,以實現可視化的目的。在訓練前,很大一部分(70%)的非空體素被隨機mask掉了。然後,編碼器只應用於可見體素,使用嵌入[46]的動態體素特徵嵌入這些體素。 masked非空體素和隨機選擇的空體素使用相同的可學習mask tokens嵌入。然後,解碼器對mask tokens序列和編碼的可見體素序列進行處理,以重建masked點雲並區分空體素和非空體素。在預訓練之後,丟棄解碼器,並將編碼器應用於unmasked點雲。

圖1:MAE(左)將影像分割為固定大小的不重疊的patches。現有的masked點建模方法(中)透過使用最遠點採樣和k近鄰來建立固定數量的點雲patches。本文的方法(右)使用非重疊體素和動態數量的點。
實驗結果:
引用:
#Hess G、Jaxing J、Svensson E 等人。用於雷射雷達點雲自監督預訓練的掩碼自動編碼器[C]//IEEE/CVF 電腦視覺應用冬季會議論文集。 2023:350-359.
以上是用於光達點雲自監督預訓練SOTA!的詳細內容。更多資訊請關注PHP中文網其他相關文章!