
基於Langchain、ChromaDB和GPT 3.5實作檢索增強生成

- 王林轉載
- 2023-09-14 14:21:111701瀏覽
譯者 | 朱先忠
重樓| 審校
摘要:在本部落格中,我們將了解一種名為檢索增強生成(retrieval augmented generation)的提示工程技術,並將基於Langchain、ChromaDB和GPT 3.5的組合來實現這種技術。
動機
隨著GPT-3等基於轉換器的大資料#模型的出現,自然語言處理(NLP)領域取得了重大突破。這些語言模型能夠產生類似人類的文本,並已有各種各樣的應用程序,如聊天機器人、內容生成和翻譯等。然而,當涉及專業化和特定於客戶的信息的企業應用場景時,傳統的語言模型可能滿足#不了要求。 另一方面,使用新的語料庫對這些模型進行微調可能既昂貴又耗時。為了應對這項挑戰,我們可以使用一種名為「檢索增強生成」(RAG:Retrieval Augmented Generation)的技術。
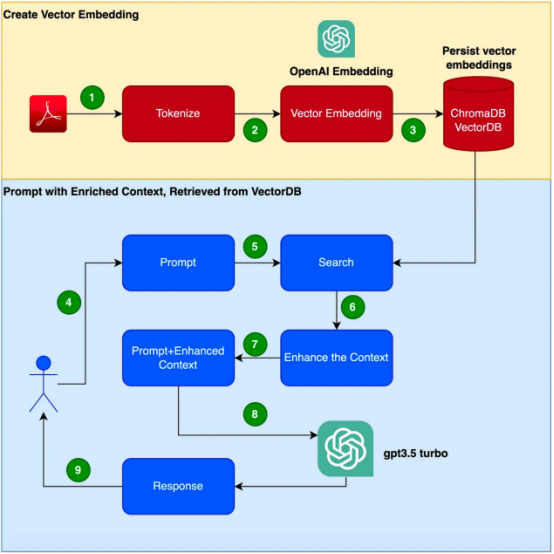
在本部落格中,我們將探討這種檢索增強生成(RAG)#技術是如何運作的,#並通過一個實戰範例來證明這項技術的#成效##。 需要說明的是,此實例將使用GPT-3.5 Turbo作為附加語料庫對產品手冊進行回應。
想像一下,你的任務是開發一個聊天機器人,該機器人可以回應有關特定產品的查詢。該產品有自己獨特的使用手冊,專門針對企業的產品。傳統的語言模型,如GPT-3,通常是根據一般資料進行訓練的,可能不了解這種特定的產品。 另一方面,使用新的語料庫對模型進行微調似乎是一種解決方案;然而,此辦法會帶來相當大的成本和資源需求。
檢索增強生成(RAG)簡介#檢索增強生成(RAG)提供了一種更有效率的方法來解決在特定領域產生適當情境回應的問題。 RAG不使用新的語料庫對整個語言模型進行微調,而是利用檢索的能力按需存取相關資訊。透過將檢索機制與語言模型結合,RAG利用外部情境來增強反應。這個外部上下文可以作為向量嵌入來提供
下#面給出
###################################################### #本文中######應用程式時######需######要遵循的步驟流程。 ############- 閱讀Clarett使用手冊(PDF格式)並使用1000個令牌的chunk_size進行令牌化。
- 建立這些標記的向量嵌入。我們將使用OpenAIEmbeddings函式庫來建立向量嵌入。
- 將向量嵌入儲存在本機。我們將使用簡單的ChromaDB作為我們的VectorDB。我們可以使用Pinecone或任何其他更高可用性的生產級的向量資料庫VectorDB。
- 使用者發出帶有查詢/問題的提示。
- 這將從V#ectorDB中進行搜尋和檢索,以便從VectorDB取得更多上下文資料。
- 此上下文資料現在將與提示內容一起使用。
- 上下文增強了提示,這通常被稱為上下文豐富。
- 提示訊息,連同查詢/問題和這個增強的上下文,現在被傳遞給大型語言模型LLM。
- 至此,LLM基於此上下文進行回應。
需要說明的是,在本範例中,我們將使用Focusrite Clarett使用手冊作為附加語料庫。 Focusrite Clarett是一個簡單的USB音訊接口,用於錄製和播放音訊。您可以從連結https://fael-downloads-prod.focusrite.com/customer/prod/downloads/Clarett 8Pre USB User Guide V2 English - EN.pdf處#下載使用手冊。
實戰演練
#設定虛擬環境
讓我們設定一個虛擬環境來#把我們的實作案例封裝起來#,以避免系統中可能出現的任何版本/函式庫/依賴性愛衝突。 現在,我們執行以下指令來建立一個新的Python虛擬環境:
pip install virtualenvpython3 -m venv ./venvsource venv/bin/activate
建立OpenAI金鑰
接下來,我們將需要一個OpenAI密鑰來存取GPT。讓我們建立一個OpenAI金鑰。您可以透過在連結https://platform.openai.com/apps註冊OpenAI來免費建立OpenAIKey。
註冊後,登入並選擇API選項,如螢幕截圖所示(時間原因所致,當您開啟該螢幕設計時可能會與我目前拍攝螢幕截圖有所變化)#。

然後,前往您的帳戶設定並選擇「查看API金鑰(View API Keys)」:
然後,選擇「建立新金鑰(Create new secret key)”,你會看到一個彈出窗口,如下圖所示。 你需要提供一個名稱,這將會產生一個金鑰。
該動作將產生一個唯一的金鑰,您應該將其複製到剪貼板並儲存在安全的地方。
接下來#,讓我們來寫Python程式碼來實作上面流程圖中顯示的所有步驟。
安裝依賴函式庫
首先,讓我們安裝我們需要的各種依賴項。我們將使用以下函式庫:
- Lanchain:一个开发LLM应用程序的框架。
- ChromaDB:这是用于持久化向量嵌入的VectorDB。
- unstructured:用于预处理Word/PDF文档。
- Tiktoken:Tokenizer框架
- pypdf:阅读和处理PDF文档的框架
- openai:访问openai的框架
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
一旦成功安装了这些依赖项,请创建一个环境变量来存储在最后一步中创建的OpenAI密钥。
export OPENAI_API_KEY=<openai-key></openai-key>
接下来,让我们开始编程。
从用户手册PDF创建向量嵌入并将其存储在ChromaDB中
在下面的代码中,我们会引入所有需要使用的依赖库和函数
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
在下面的代码中,阅读PDF,将文档标记化并拆分为标记。
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
在下面的代码中,我们将创建一个色度集合,一个用于存储色度数据库的本地目录。然后,我们创建一个向量嵌入并将其存储在ChromaDB数据库中。
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData, embeddings, collection_name=collection_name, persist_directory=persist_directory )vectDB.persist()
执行此代码后,您应该会看到创建了一个存储向量嵌入的文件夹。
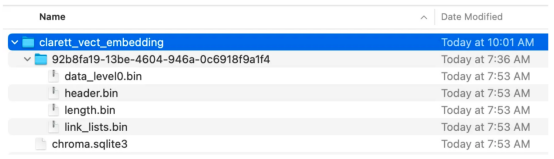
现在,我们将向量嵌入存储在ChromaDB中。下面,让我们使用LangChain中的ConversationalRetrievalChain API来启动聊天历史记录组件。我们将传递由GPT 3.5 Turbo启动的OpenAI对象和我们创建的VectorDB。我们将传递ConversationBufferMemory,它用于存储消息。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm( OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
既然我们已经初始化了会话检索链,那么接下来我们就可以使用它进行聊天/问答了。在下面的代码中,我们接受用户输入(问题),直到用户键入“done”。然后,我们将问题传递给LLM以获得回复并打印出来。
chat_history = []qry = ""while qry != 'done': qry = input('Question: ') if qry != exit: response = chatQA({"question": qry, "chat_history": chat_history}) print(response["answer"])
这是输出的屏幕截图。

小结
正如你从本文中所看到的,检索增强生成是一项伟大的技术,它将GPT-3等语言模型的优势与信息检索的能力相结合。通过使用特定于上下文的信息丰富输入,检索增强生成使语言模型能够生成更准确和与上下文相关的响应。在微调可能不实用的企业应用场景中,检索增强生成提供了一种高效、经济高效的解决方案,可以与用户进行量身定制、知情的交互。
译者介绍
朱先忠是51CTO社区的编辑,也是51CTO专家博客和讲师。他还是潍坊一所高校的计算机教师,是自由编程界的老兵
原文标题:Prompt Engineering: Retrieval Augmented Generation(RAG),作者:A B Vijay Kumar
以上是基於Langchain、ChromaDB和GPT 3.5實作檢索增強生成的詳細內容。更多資訊請關注PHP中文網其他相關文章!