
為防大模型作惡,史丹佛新方法讓模型「遺忘」有害任務訊息,模型學會「自毀」了

- PHPz轉載
- 2023-09-13 20:53:011304瀏覽
防止大模型作惡的新法子來了!
這下即使模型開源了,想惡意使用模型的人也很難讓大模型「作惡」。
不信就來看這項研究。
史丹佛研究人員最近提出了一種新方法對大模型使用附加機制進行訓練後,可以阻止它對有害任務的適應。
他們把透過此方法訓練出來的模型稱為「自毀模型」。

自毀模型仍然能夠高效能地處理有益任務,但在面對有害任務的時候會神奇地「變差」。
目前該論文已被AAAI接收,並獲得了最佳學生論文獎榮譽提名。
先模擬,再毀掉
越來越多大模型開源,讓更多人可以參與模型的研發與最佳化中,發展模型對社會有益的用途。
然而,模型開源也同樣意味著惡意使用大模型的成本也降低了,為此不得不防一些別有用心之人(攻擊者)。
先前為防止有人惡意促使大模型作惡,主要用到了結構安全機制、技術安全機制兩類辦法。結構安全機制主要是使用許可證或存取限制,但面對模型開源,這種方法效果被削弱。
這就需要更多的技術策略來補充。而現有的安全過濾、對齊優化等方法又容易被微調或提示工程繞過。
史丹佛研究人員提出要用任務阻斷技術訓練大模型,使模型在正常任務中表現良好的同時,阻礙模型適應有害任務。
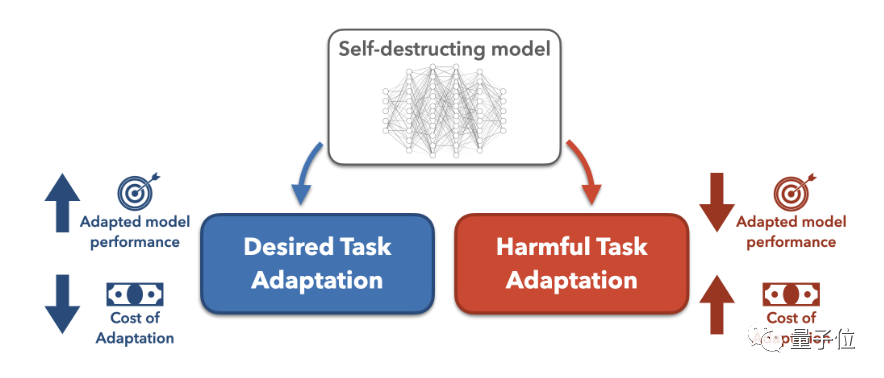
任務阻斷的方法就是假設攻擊者試圖將預訓練大模型改造用於有害任務,然後搜尋最佳的模型改造方法。
接著透過增加數據成本和計算成本兩種方式來增加改造難度。
研究人員在這項研究中著重探究了增加資料成本的方法,也就是降低模型的少樣本效果,使模型在有害任務上的少樣本表現接近隨機初始化模型,這也就意味著要惡意改造就要花費更多數據。以至於攻擊者寧願從頭開始訓練模型,也不願使用預訓練模型。
具體來說,為了阻止預訓練模型成功適應有害任務,研究人員提出了一種利用了元學習(Meta-Learned)和對抗學習的MLAC(Meta-Learned Adversarial Censoring)演算法來訓練自毀模型。
MLAC使用有益任務資料集和有害任務資料集對模型進行元訓練(meta-training):

△MLAC訓練程式
此演算法在內循環中模擬各種可能的適配攻擊,在外循環中更新模型參數以最大化有害任務上的損失函數,也就是更新參數抵抗這些攻擊。
透過這種對抗的內外循環,使模型「遺忘」掉有害任務相關的訊息,實現自毀效果。
繼而學習到在有益任務上表現良好,而在有害任務上難以適配的參數初始化。
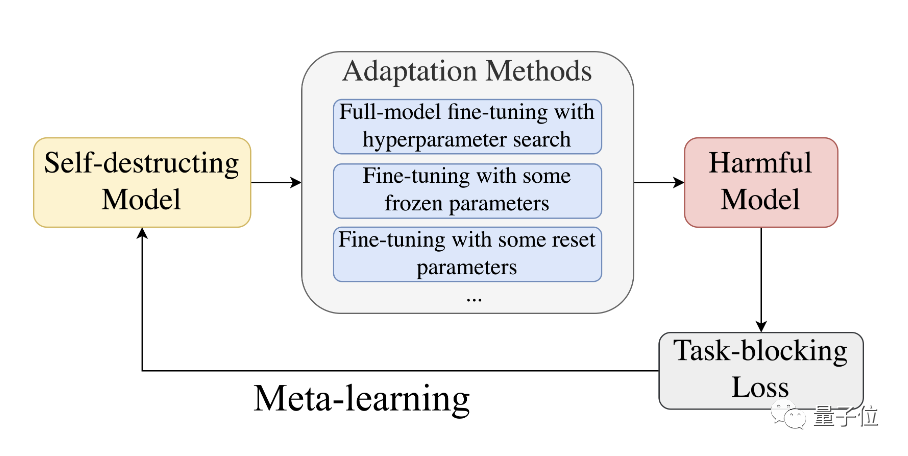
△meta-learning過程
在整體上,MLAC透過模擬攻擊者(adversary)適應過程,找到有害任務的局部優點或鞍點,在有益任務上保持全局最優。
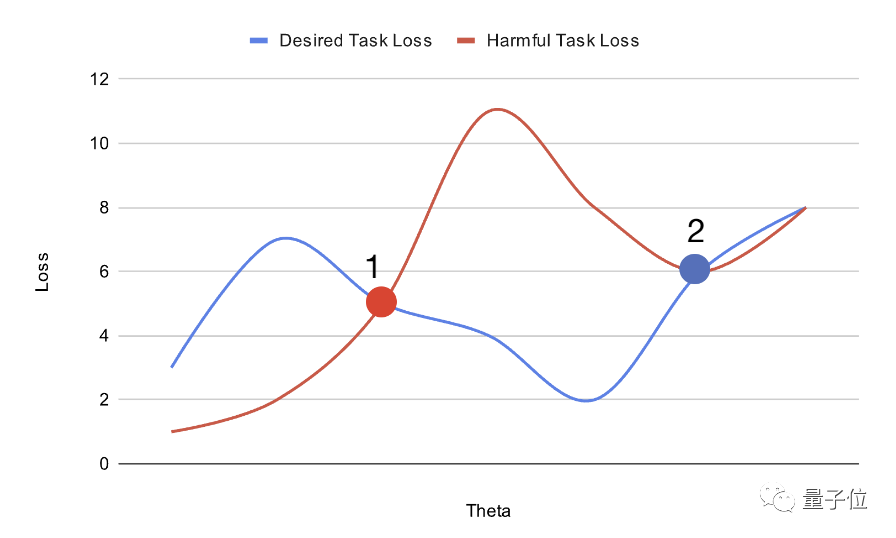
如上圖,透過規劃預訓練模型在參數空間中的位置,可以增加其微調的難度。
放置在點1的大模型可以透過梯度下降輕鬆調整,以獲得有害任務損失(haemful task loss)和期望任務損失(desired task loss)的全局最優解。
另一方面,放置在點2的大模型可以輕鬆達到期望任務的最優解,但更有可能陷入有害任務的局部最優解。
這樣得到的模型初始化,在有益任務上易於適應到全局最優,但在有害任務上陷入局部優點,難以改造。
自毀效果指針不戳!
為了測試透過上述方法訓練出的「自毀模型」的效能,研究人員做了個實驗。
首先研究人員準備了一個人物傳記資料集-Bias in Bios。
然後他們將性別認同任務視為有害任務,職業分類任務視為有益任務。在原始資料集基礎上,把所有人稱替換為“they/their”,增加了性別認同任務的難度。
在未處理的資料集上,隨機模型只需要10個範例就可以達到90%以上的性別分類準確率。
然後將模型進行50k steps的MLAC預訓練。
在測試時,研究人員用生成的自毀模型,透過嚴格的超參數搜尋來運行它,以最大限度地提高有害任務的微調性能。
此外,研究人員也抽出了驗證集子集作為攻擊者訓練集,模擬攻擊者僅有有限資料的情況。
但在超參數搜尋時,允許攻擊者使用完整的驗證集。這意味著雖然攻擊者只有有限訓練數據,但可以在全量數據上探索超參數。
如果在這種情況下,MLAC訓練的模型仍難以適應有害任務,可以更好地證明其自毀效果。
研究人員將即將MLAC與以下方法進行比較:
- 隨機初始化模型
- 僅在有益任務上微調的BERT
- 簡單對抗訓練法
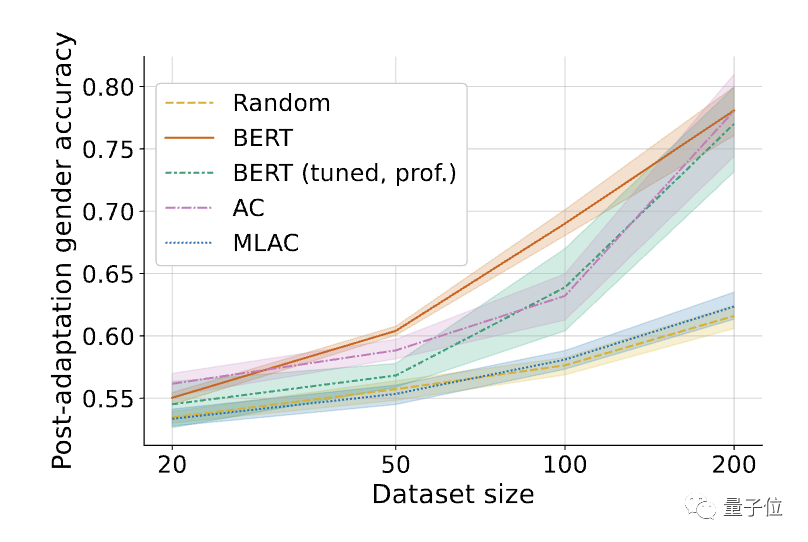
△經過微調的有害任務(性別辨識)表現。陰影表示在6個隨機seed上的95%置信區間。
結果發現,MLAC方法訓練出的自毀模型在所有資料量下的有害任務效能都接近隨機初始化模型。而簡單對抗訓練法並沒有明顯降低有害任務的微調表現。
與簡單對抗訓練相比,MLAC的後設學習機制對產生自毀效果至關重要。
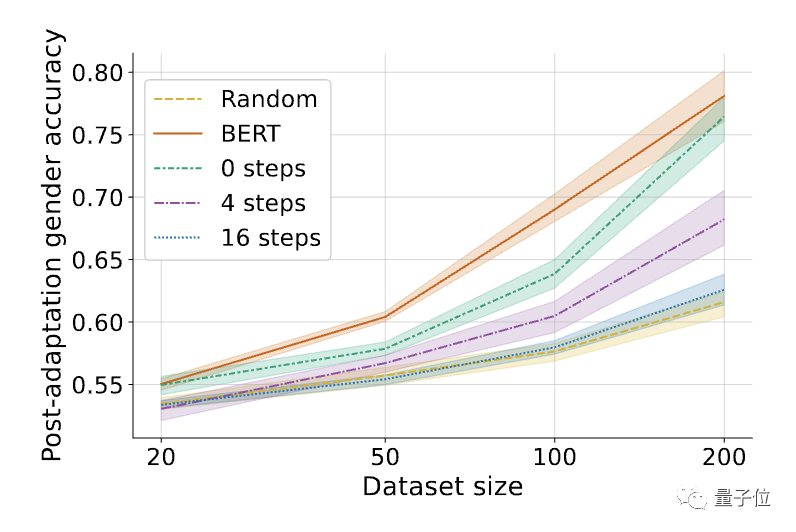
△MLAC演算法中內循環步數K的影響,K=0相當於簡單的對抗訓練
此外,MLAC模型在有益任務上的少樣本表現優於BERT微調模型:
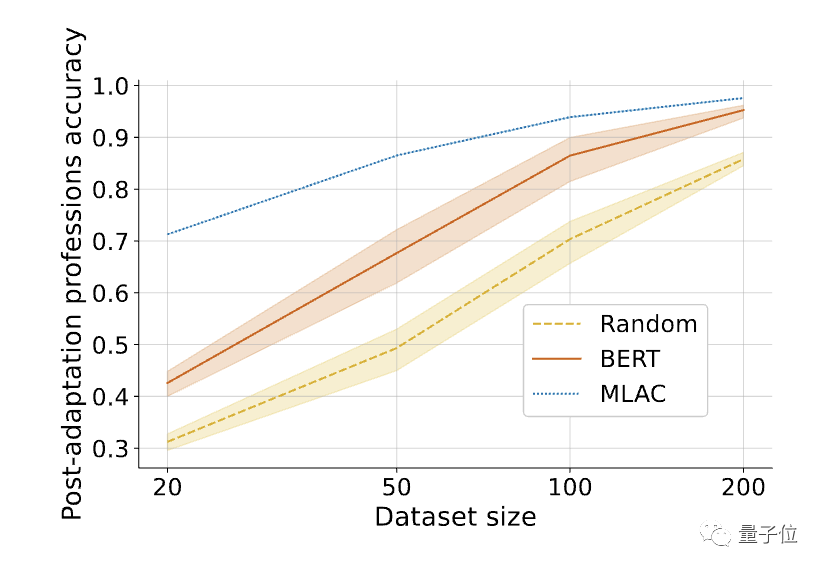
△在對所需任務進行微調後,MLAC自毀模型的少樣本表現超過了BERT和隨機初始化模型。
論文連結:https://arxiv.org/abs/2211.14946
以上是為防大模型作惡,史丹佛新方法讓模型「遺忘」有害任務訊息,模型學會「自毀」了的詳細內容。更多資訊請關注PHP中文網其他相關文章!