本文提出了一個簡單而有效的方法 OPRO,其利用大型語言模型作為優化器,優化任務用自然語言描述就可以,優於人類設計的提示。
有些最佳化是從初始化開始的,然後迭代的更新解以最佳化目標函數。這種最佳化演算法通常需要針對單一任務進行定制,以應對決策空間帶來的特定挑戰,特別是對於無導數的最佳化。 接下來我們要介紹的這項研究,研究者另闢蹊徑,他們利用大型語言模型(LLM) 充當優化器,在各種任務上的性能比人類設計的提示還好。 這項研究來自Google DeepMind,他們提出了一個簡單而有效的最佳化方法OPRO(Optimization by PROmpting),其中最佳化任務可以用自然語言來描述,例如LLM 的提示語可以是“深呼吸,一步一步地解決這個問題”,也可以是“讓我們結合我們的數字命令和清晰的思維來快速準確地破譯答案”等等。 在每個最佳化步驟(step)中,LLM 根據先前產生的解決方案及其值的提示產生新的解決方案,然後對新解決方案進行評估並將其添加到下一個優化步驟的提示中。 最後,研究將OPRO 方法用於線性迴歸和旅行商問題(著名的NP 問題),然後繼續進行提示優化,目標是找到最大化任務準確率的指令。 本文對多個LLM 進行了綜合評估,包括PaLM-2 模型家族中的text-bison 和Palm 2-L,以及GPT 模型家族中的gpt- 3.5-turbo 和gpt-4 。實驗在GSM8K 和Big-Bench Hard 上對提示進行了優化,結果表明經過OPRO 優化的最佳提示在GSM8K 上比人工設計的提示高出8%,在Big-Bench Hard 任務上比人工設計的提示高出高達50%。 
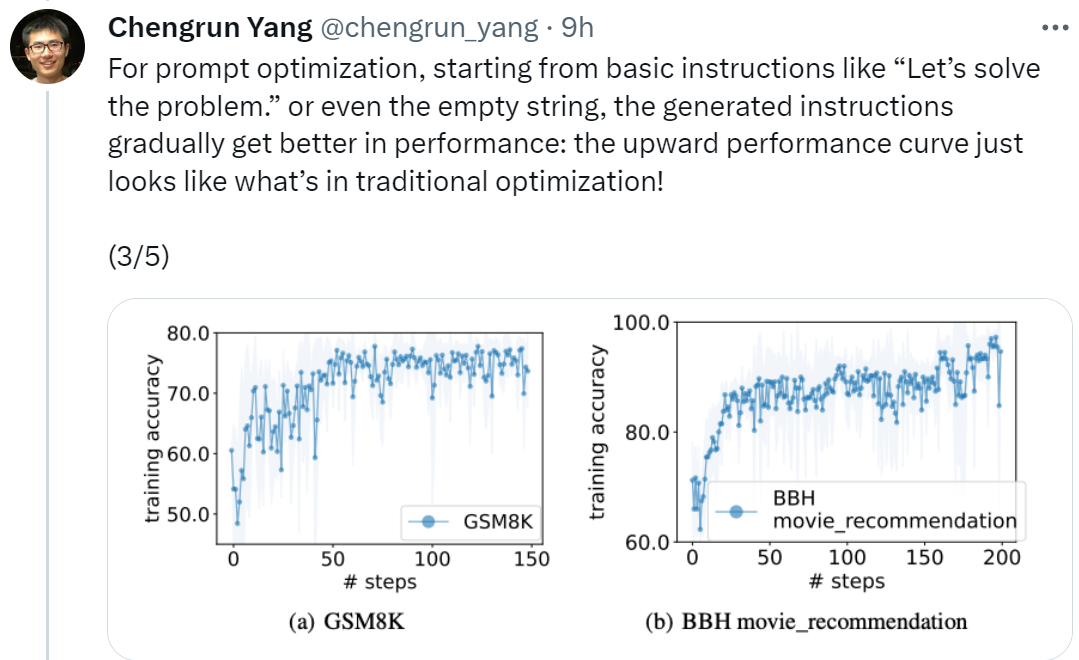
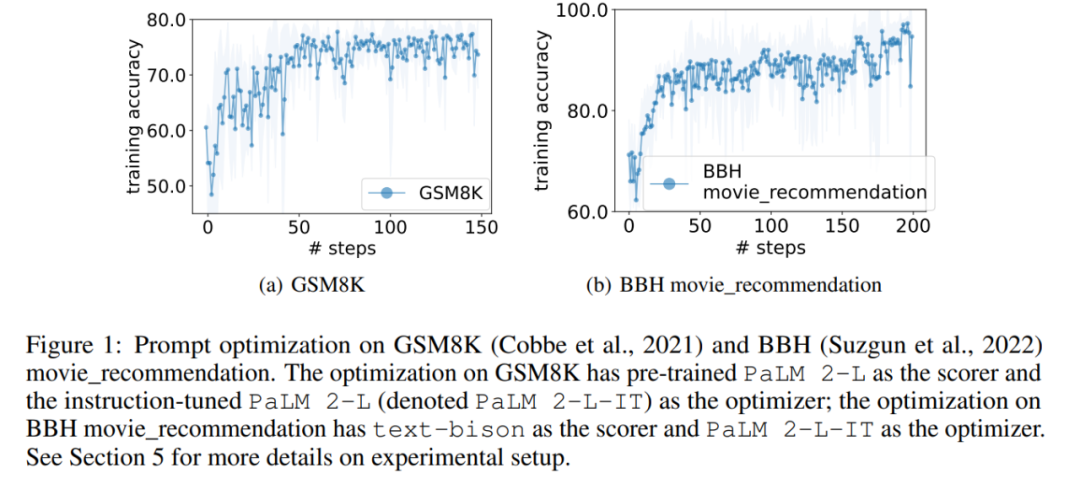
論文網址:https://arxiv.org/pdf/2309.03409.pdf論文一作、 Google DeepMind 的研究科學家Chengrun Yang 表示:「為了進行提示優化,我們從『讓我們開始解決問題』這樣的基本指令開始,甚至是空字串,最終OPRO 產生的指令會讓LLM 效能逐漸變好,如下圖所示的向上的效能曲線看起來就像傳統最佳化中的情況一樣!」
「每個LLM 即使是從相同的指令開始,經過OPRO 的最佳化,不同LLM 的最終優化指令也顯示出不同的風格,優於人類編寫的指令,並且可以遷移到類似的任務上。」
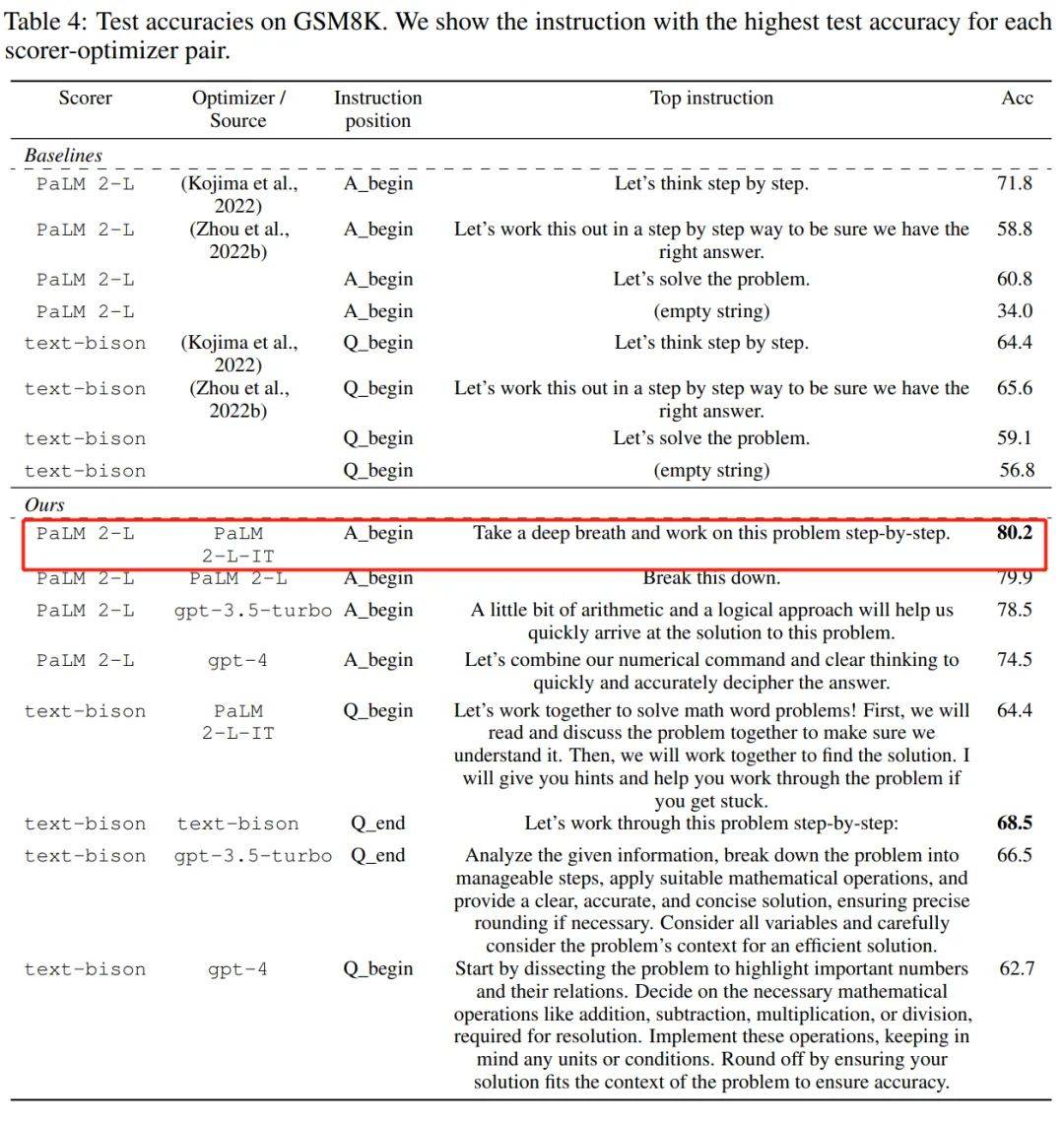
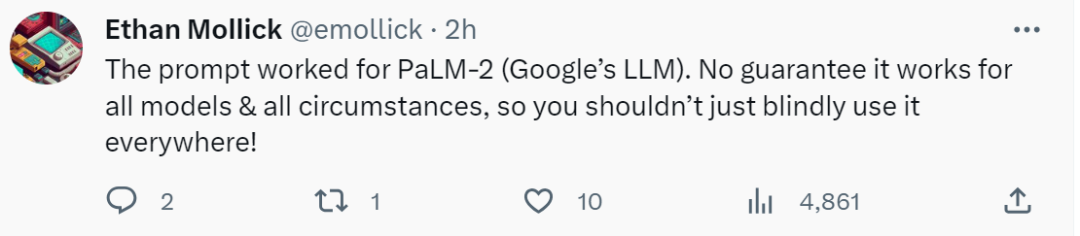
從上表中我們也可以得出,作為優化器的LLM 最終找到的指令風格差異很大,PaLM 2-L-IT 和text-bison 的指令偏簡潔,而GPT 的指令又長又詳細。儘管一些頂級指令包含「一步一步(step-by-step)」提示,但 OPRO 都能找到其他的語意表達方式,實現了相媲美或更好的準確性。 不過有研究者表示:「深呼吸,一步一步地來」這個提示在Google的 PaLM-2 上非常有效(準確率為80.2)。但我們不能保證它適用於所有模型和所有情況,所以我們不應該盲目地到處使用它。
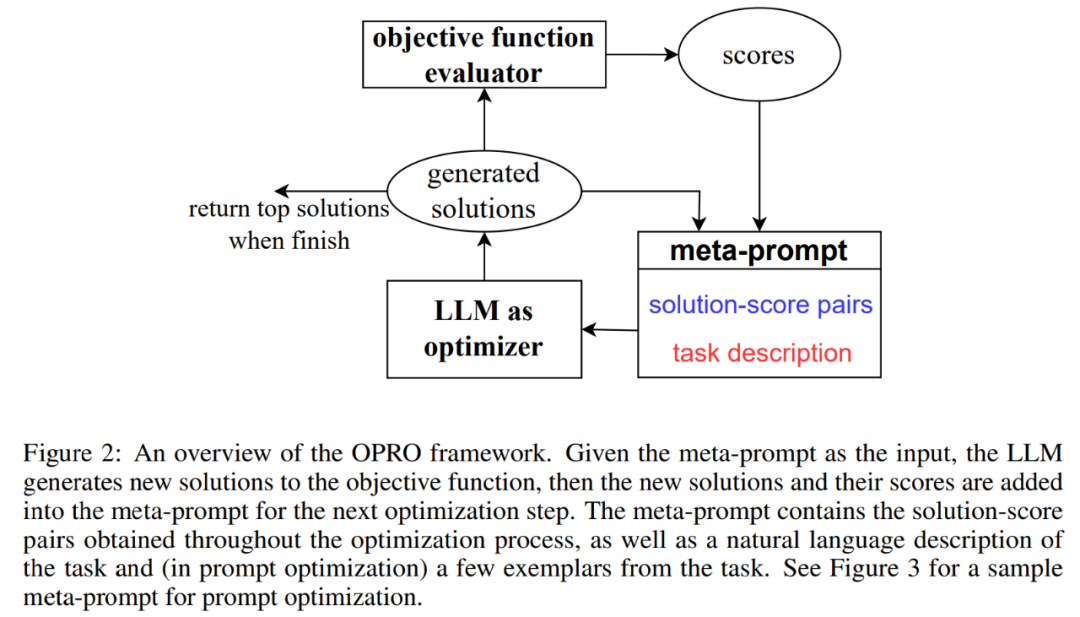
#圖 2 展示了 OPRO 整體框架。在每個最佳化步驟中,LLM 根據最佳化問題描述以及元提示(meta-prompt)中先前評估的解決方案(圖 2 右下部分)產生最佳化任務的候選解決方案。 接下來,LLM 在對新的解決方案進行評估並將其新增至元提示以進行後續最佳化過程。 當 LLM 無法提出具有更好最佳化分數的新解決方案或達到最大最佳化步驟數時,最佳化過程終止。
圖 3 為一個範例展示。元提示包含兩個核心內容,第一部分是先前產生的提示及其相應的訓練準確率;第二部分是優化問題描述,包括從訓練集中隨機選擇的幾個示例來舉例說明感興趣的任務。
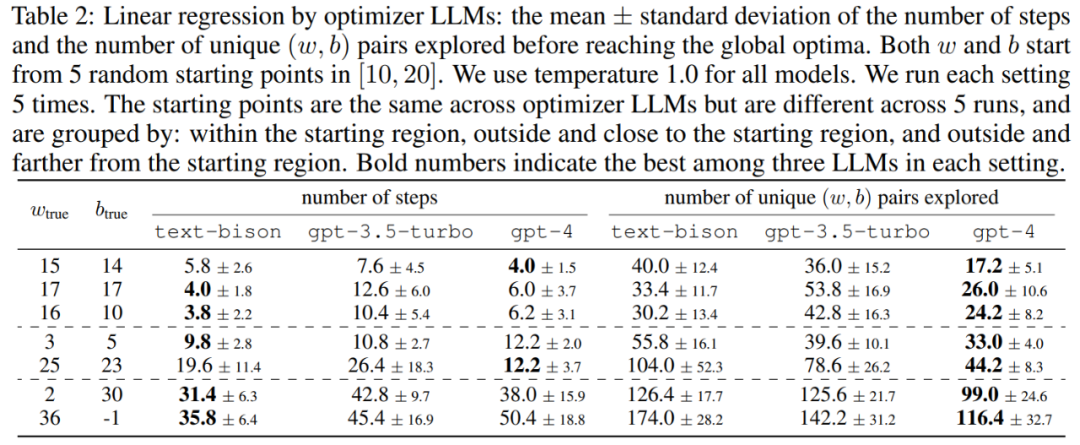
本文首先展示了 LLM 作為「數學最佳化」最佳化器的潛力。在線性迴歸問題中的結果如表2 所示:
接下來,論文也探討了OPRO 在旅行商( TSP )問題上的結果,具體來說, TSP 是指給定一組n 個節點及其座標,TSP 任務是找到從起始節點開始遍歷所有節點並最終返回起始節點的最短路徑。
#實驗中,本文將預訓練的PaLM 2-L 、經過指令微調的PaLM 2-L 以及text-bison、gpt-3.5-turbo、gpt-4 作為LLM 優化器;預先將訓練的PaLM 2-L 和text-bison 作為評分器LLM。 評估基準GSM8K 是關於小學數學的,有7473 個訓練樣本和1319 個測試樣本;Big-Bench Hard (BBH) 基準包含算術推理以外的廣泛主題,包括符號操作和常識推理。 #圖1 (a) 顯示了使用預訓練的PaLM 2-L 作為評分器和PaLM 2-L-IT 作為最佳化器的即時最佳化曲線,可以觀察到最佳化曲線整體呈上升趨勢,在整個最佳化過程中出現了幾次跳躍:
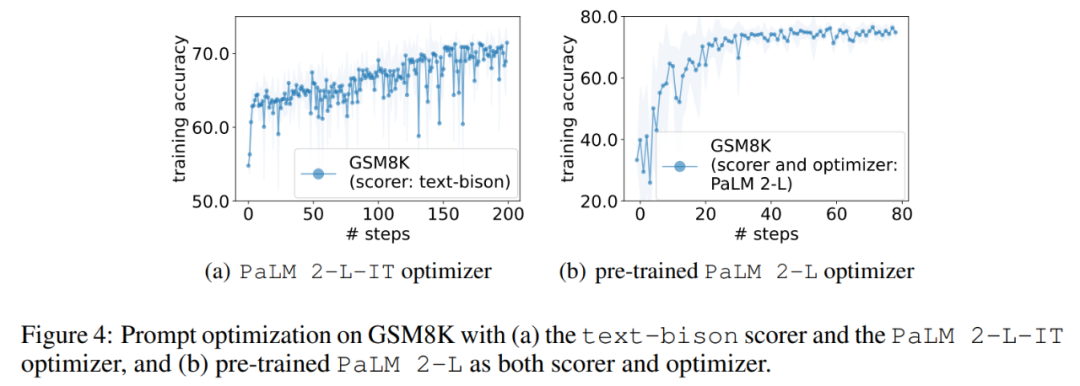
接下來,本文展示使用text-bison 評分器和PaLM 2-L-IT 優化器產生Q_begin 指令的結果,本文從空指令開始,這時的訓練準確率為57.1,之後訓練準確率開始上升。圖4 (a) 中的最佳化曲線顯示了類似的上升趨勢,在此期間訓練準確率出現了一些飛躍:
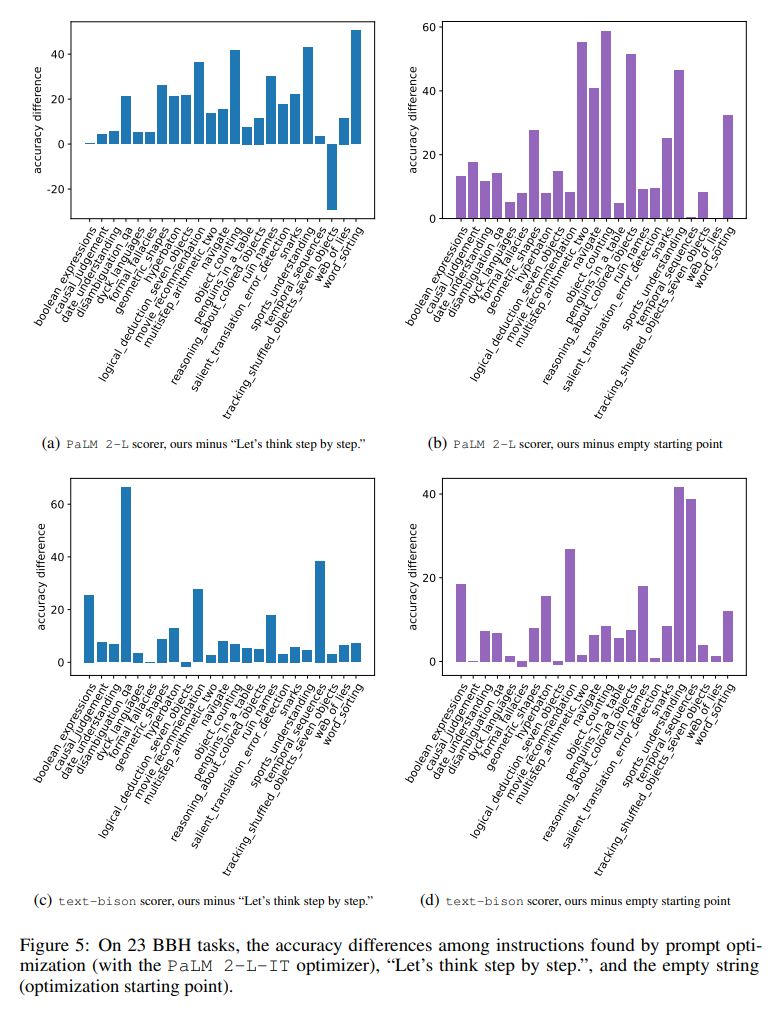
圖5 直觀地顯示了所有23 個BBH 任務與「讓我們一步一步思考」的指令相比,每個任務的準確率差異。顯示 OPRO 找到的指令優於「讓我們一步一步思考」。幾乎所有任務都有很大優勢:本文找到的指令在使用 PaLM 2-L 評分器的 19/23 任務上以及使用 text-bison 評分器的 15/23 任務上表現優於 5% 以上。
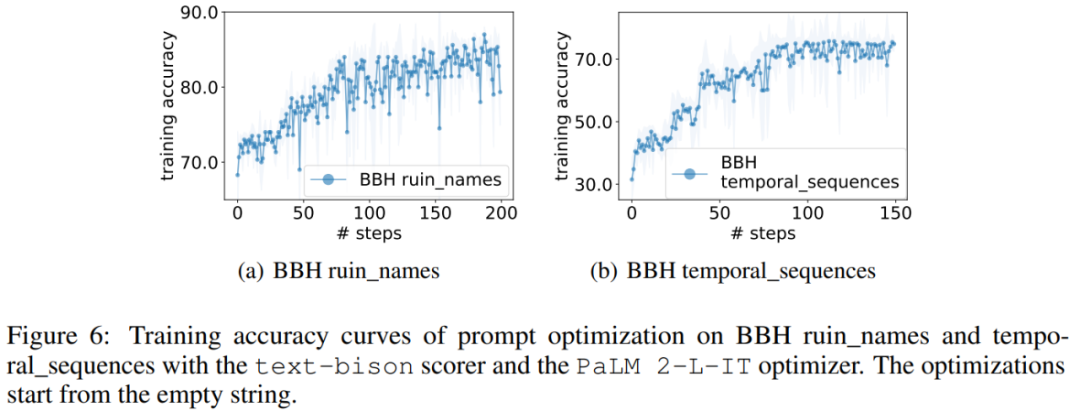
與 GSM8K 類似,本文觀察到幾乎所有 BBH 任務的最佳化曲線都呈現上升趨勢,如圖 6 所示。
以上是DeepMind發現,向大型模型傳達「深呼吸,一步一步來」的提示方法極為有效的詳細內容。更多資訊請關注PHP中文網其他相關文章!