
OPPO提出GlyphDraw:一鍵產生漢字影像,擴散模型輸出表情包

- PHPz轉載
- 2023-08-29 20:25:03784瀏覽
近年來,文字生成圖像領域取得了許多令人驚訝的突破,許多模型都能夠根據文字指令創建高品質和多樣化的圖像。儘管生成的圖像已經非常逼真,但目前的模型通常擅長生成風景、物體等實體圖像,而難以生成具有高度連貫細節的圖像,例如帶有漢字等複雜字形文本的圖像
為了解決這個問題,來自OPPO等機構的研究者提出了一個名為GlyphDraw的通用學習架構。此框架的目標是讓模型能夠產生嵌入連貫文字的圖像。這項工作是圖像合成領域中首個解決漢字生成問題的工作

#請點擊以下連結查看論文:https://arxiv. org/abs/2303.17870
專案首頁連結:https://1073521013.github.io/glyph-draw.github.io/
#讓我們先來看生成效果,例如為展覽館產生警示標語:

#製作廣告看板:

為圖片加入簡短的文字說明,同時也可以多樣化文字樣式

#還有一個有趣又實用的範例是產生表情符號:

#儘管結果有一些缺陷,但總體而言,研究的生成效果已經非常出色。研究的主要貢獻包括:
研究提出了一個名為GlyphDraw的漢字影像生成框架。在整個生成過程中,利用漢字字形和位置等輔助訊息,該框架能夠提供細粒度的指導,從而使得生成的漢字圖像能夠高品質地無縫嵌入到圖像中
這項研究提出了一種有效的訓練策略,透過限制預訓練模型中可訓練參數的數量,以防止過度擬合和災難性遺忘(catastrophic forgetting),成功地保持了模型在開放域生成方面的強大性能,並且能夠準確地生成漢字圖像
這項研究詳細描述了構建訓練資料集的過程,並提出了一種新的基準方法來評估漢字圖像生成的品質。其中,GlyphDraw 的生成準確率達到了75%,明顯優於先前的影像合成方法

模型介紹:
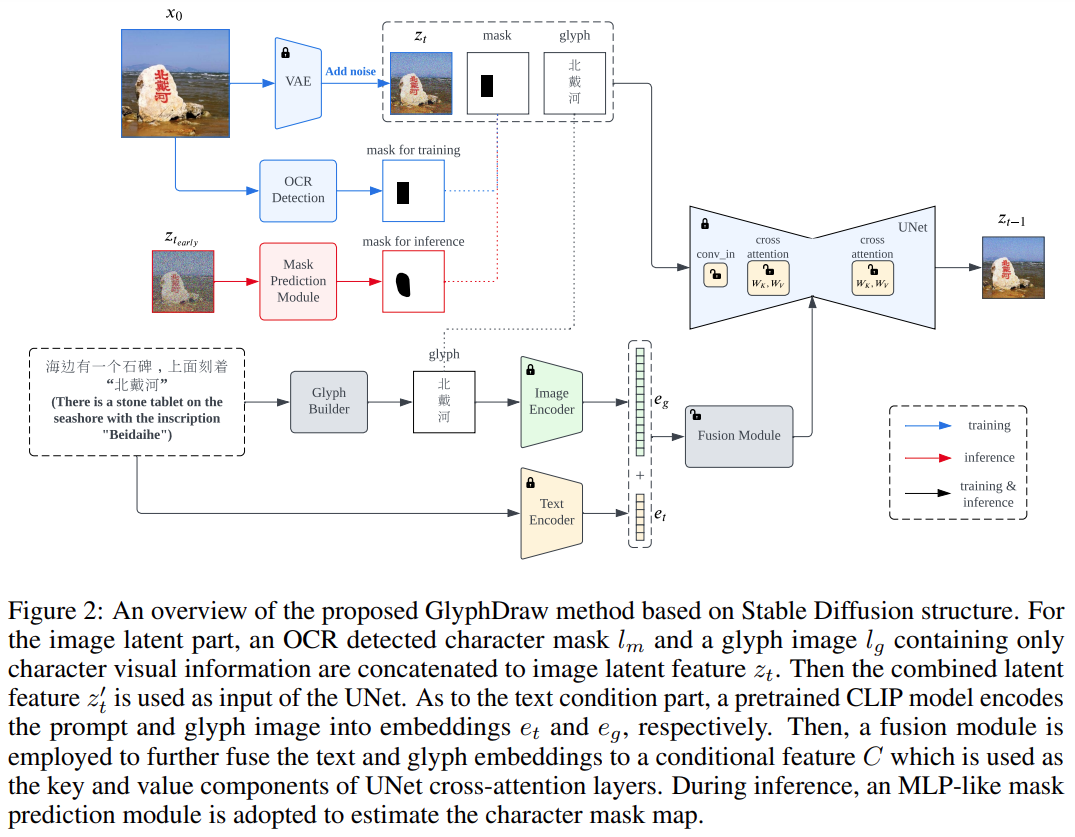
首先,該研究設計了一種複雜的圖像-文字資料集建構策略。接著,利用開源影像合成演算法Stable Diffusion,提出了一個通用學習框架GlyphDraw,如圖2所示
穩定擴散的整體訓練目標可以表示為以下公式:
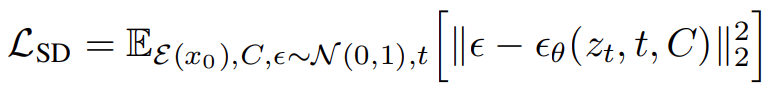
GlyphDraw是基於Stable Diffusion中的交叉注意力機制的。它將原始輸入的潛在向量z_t與圖像的潛在向量z_t、文字掩碼l_m和字形圖像l_g進行級聯替代
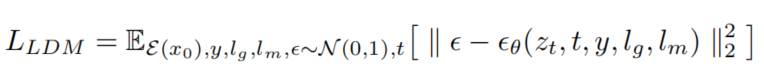
此外,透過使用特定領域的融合模組,條件C 配備了混合字形和文字特徵。引入文本掩碼和字形信息,使整個訓練過程實現了細粒度的擴散控制,這是提高模型性能的關鍵組成部分,最終能夠生成帶有漢字文本的圖像
具體來說,文本資訊的像素表徵,在特別是複雜的文本形式中,如像形漢字,與自然物體有明顯的差異。舉例來說,中文詞語「天空(sky)」是由二維結構的多個筆畫組成,而對應的自然圖像是「點綴著白雲的藍天」。相較之下,漢字具有非常細粒度的特性,即使是微小的移動或變形也會導致文字渲染不正確,從而無法實現圖像生成
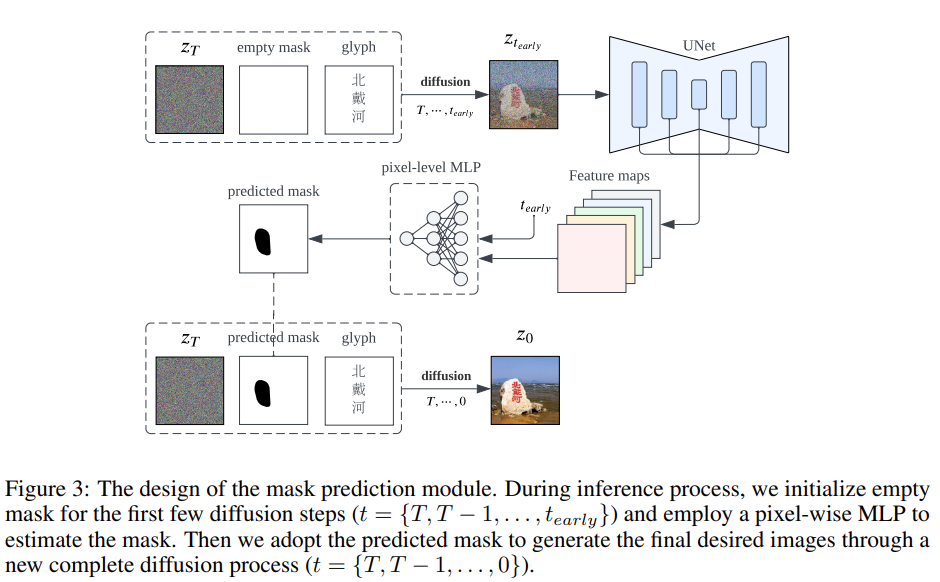
嵌入字元到自然影像背景中還需要考慮一個關鍵問題,即在不影響相鄰自然影像像素的情況下,精確控製文字像素的生成。為了在自然圖像上展示出完美的漢字,作者設計了兩個關鍵組件,即位置控制和字形控制,它們被集成到了擴散合成模型中
#與其他模型的全局條件輸入不同,字符生成需要更多地關注影像的特定局部區域,因為字元像素的潛在特徵分佈與自然影像像素的潛在特徵分佈有很大差異。為了防止模型學習崩潰,該研究創新性地提出了細粒度位置區域控制來解耦不同區域之間的分佈
#重寫後的內容:除了位置控制之外,另一個重要問題是對漢字筆畫合成進行精細控制。考慮到漢字的複雜性和多樣性,在沒有任何明確的先驗知識的情況下,僅僅從大量的圖像-文字資料集中學習是非常困難的。為了準確產生漢字,該研究將顯式的字形圖像作為額外的條件資訊引入模型的擴散過程中
#為了保持原意不變,需要將內容改寫為中文,以下是改寫後的內容: 研究設計和實驗結果
由於先前沒有專門用於漢字影像生成的資料集,該研究首先創建了一個用於定性和定量評估的基準資料集ChineseDrawText。隨後,研究人員在ChineseDrawText上進行了幾種方法的生成準確率測試,並透過OCR識別模型進行評估
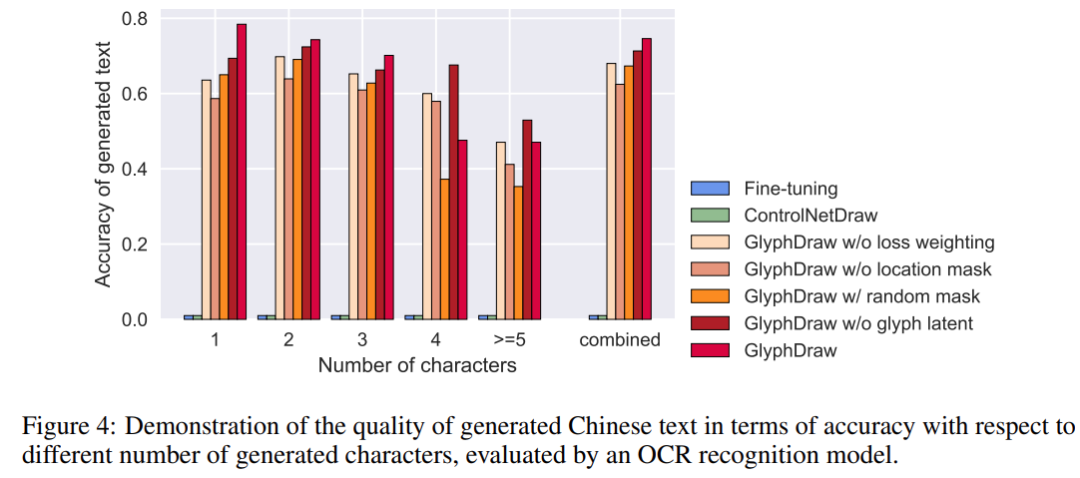
該研究提出的GlyphDraw模型透過充分利用輔助字形和位置訊息,達到了平均準確率為75%的出色效果,證明了該模型在字元圖像生成方面的卓越能力。下圖展示了幾種方法的可視化比較結果

此外,GlyphDraw還可以透過限制訓練參數來保持開放域影像合成性能,在MS-COCO FID-10k上一般影像合成的FID只下降了2.3


有興趣的讀者可以閱讀論文原文,了解更多研究細節。
以上是OPPO提出GlyphDraw:一鍵產生漢字影像,擴散模型輸出表情包的詳細內容。更多資訊請關注PHP中文網其他相關文章!