
【建議收藏】靈魂拷問! Zookeeper的31連環砲
- Java后端技术全栈轉載
- 2023-08-28 16:45:46939瀏覽
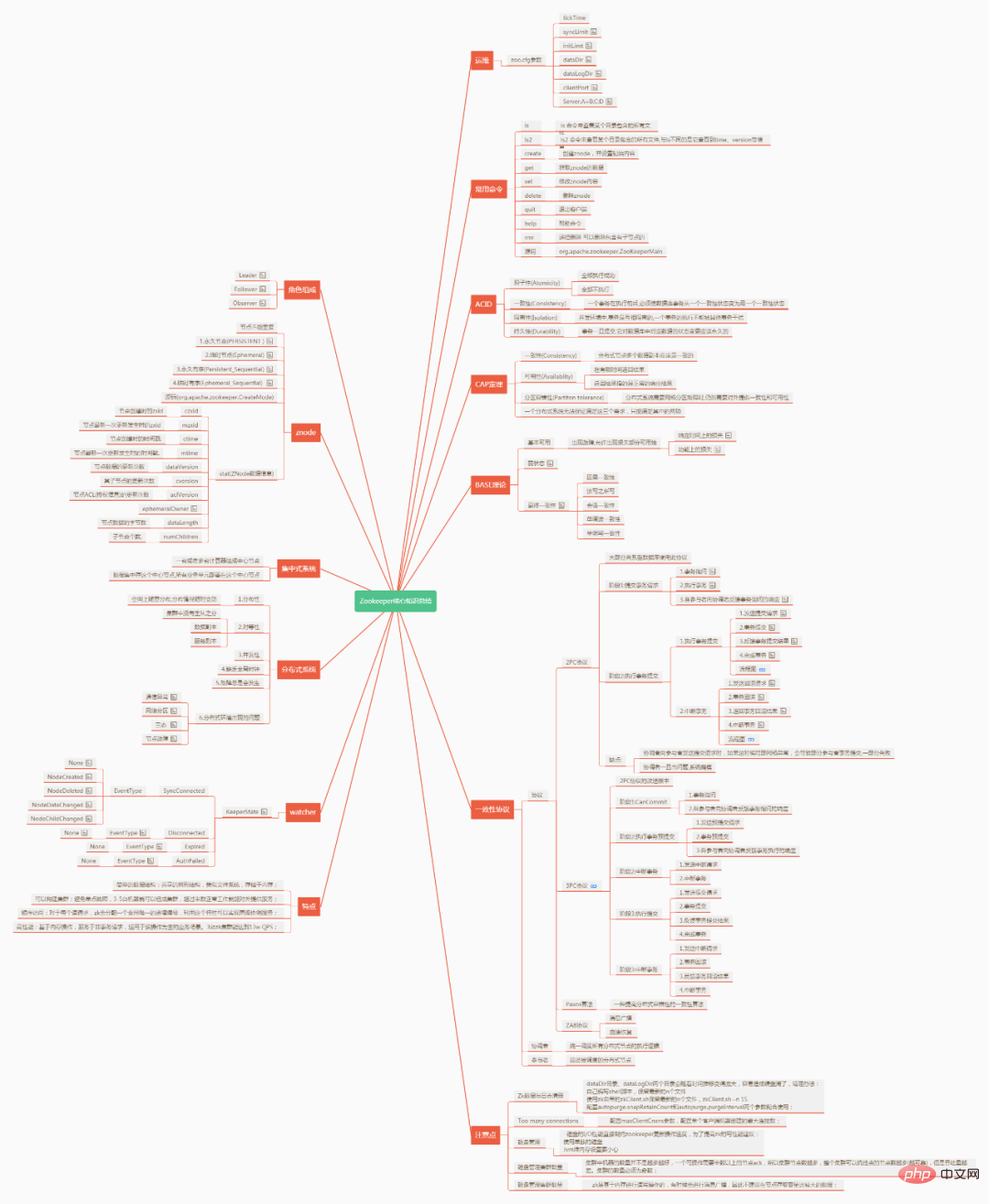
Zookeeper核心知識總結
請看題目
#ZooKeeper 是什麼? ZooKeeper 提供了什麼? Zookeeper 檔案系統 Zookeeper 怎麼保證主會從節點的狀態同步? 四種類型的資料節點 Znode #Zookeeper Watcher 機制-- 資料變更通知 客戶端註冊Watcher 是如何實現? 服務端處理 Watcher 是如何實作? 客戶端是如何回呼 Watcher的? 熟悉ACL 權限控制機制嗎? 了解Chroot 特性嗎? 熟悉會話管理嗎 伺服器有哪些角色? Zookeeper 下 Server 工作狀態 資料是如何同步的? zookeeper 是如何保證交易的順序一致性的? 分散式叢集為什麼會有 Master主節點? zk 節點宕機如何處理? zookeeper 負載平衡和 nginx 負載平衡差異 Zookeeper 有哪幾種幾個部署模式? 叢集最少要幾台機器,叢集規則是怎麼樣的?叢集中有 3 台伺服器,其中一個節點宕機,這個時候 Zookeeper 還可以使用嗎? 叢集支援動態新增機器嗎? Zookeeper 對節點的 watch 監聽通知是永久的嗎?為什麼不是永久的? Zookeeper 的 java 用戶端都有哪些? chubby 是什麼,和 zookeeper 比你怎麼看? 說幾個 zookeeper 常用的指令。 ZAB 與 Paxos 演算法的聯繫與差異? Zookeeper 的典型應用場景 Zookeeper 都有哪些功能? 說一下 Zookeeper 的通知機制? Zookeeper 和 Dubbo 的關係?
你能回答出幾道?
1. ZooKeeper 是什麼?
ZooKeeper 是一個開源的分散式協調服務。它是一個為分散式應用提供一致性服務的軟體,分散式應用程式可以基於Zookeeper 實現諸如資料發布/訂閱、負載平衡、命名服務、分散式協調/通知、叢集管理、Master 選舉、分散式鎖定和分散式佇列等功能。
ZooKeeper 的目標就是封裝好複雜易出錯的關鍵服務,將簡單易用的介面和效能高效、功能穩定的系統提供給使用者。
Zookeeper 保證瞭如下分散式一致性特性:
#順序一致性 原子性 單一視圖 可靠性 #即時性(最終一致性)
客戶端的讀取請求可以被叢集中的任一台機器處理,如果讀取請求在節點上註冊了監聽器,這個監聽器也是由所連接的zookeeper 機器來處理。對於寫入請求,這些請求會同時發給其他 zookeeper 機器並且達成一致後,請求才會回傳成功。因此,隨著 zookeeper 的叢集機器增多,讀取請求的吞吐會提高但是寫入請求的吞吐會下降。
有序性是zookeeper 中非常重要的一個特性,所有的更新都是全域有序的,每個更新都有一個唯一的時間戳,這個時間戳稱為zxid(Zookeeper Transaction Id) 。而讀取請求只會相對於更新有序,也就是讀取請求的回傳結果中會帶有這個zookeeper 最新的 zxid。
2. ZooKeeper 提供了什麼?
檔案系統 #通知機制
3. Zookeeper 檔案系統
Zookeeper 提供一個多層級的節點命名空間(節點稱為znode)。與檔案系統不同的是,這些節點都可以設定關聯的數據,而檔案系統中只有檔案節點可以存放資料而目錄節點不行。 歡迎追蹤「面試專欄」以獲得更多面試乾貨。
Zookeeper 為了保證高吞吐和低延遲,在記憶體中維護了這個樹狀的目錄結構,這種特性使得Zookeeper 不能用於存放大量的數據,每個節點的存放數據上限為1M。
4. Zookeeper 怎麼保證主會從節點的狀態同步?
Zookeeper 的核心是原子廣播機制,這個機制保證了各個 server 之間的同步。實作這個機制的協定叫做 Zab 協定。 Zab 協定有兩種模式,它們分別是恢復模式和廣播模式。
恢復模式
當服務啟動或領導者崩潰後,Zab就進入了恢復模式,當領導者被選舉出來,而且大多數server 完成了和leader 的狀態同步以後,恢復模式就結束了。狀態同步保證了 leader 和 server 具有相同的系統狀態。
廣播模式
一旦leader 已經和多數的follower 進行了狀態同步後,它就可以開始廣播訊息了,即進入廣播狀態。這時候當一個 server 加入 ZooKeeper 服務中,它會在恢復模式下啟動,發現 leader,並且和 leader 進行狀態同步。待到同步結束,它也參與訊息廣播。 ZooKeeper 服務一直維持在 Broadcast 狀態,直到 leader 崩潰了或 leader 失去了大部分的 followers 支援。
#5. 說說zookeeper有哪些資料節點
除非手動刪除,否則節點一直存在於Zookeeper 上
EPHEMERAL-暫存節點
6. 說Zookeeper Watcher 機制
Zookeeper 允許客戶端向服務端的某個Znode 註冊一個Watcher 監聽,當服務端的一些指定事件觸發了這個Watcher,服務端會向指定客戶端發送事件通知來實現分散式的通知功能,然後客戶端根據Watcher 通知狀態和事件類型做出業務上的變更。歡迎追蹤「面試專欄」以獲得更多面試乾貨。
工作機制:
(1)客戶端註冊watcher
(2)服務端處理watcher
(3)客戶端回呼watcher
Watcher 特性總結:
(1)一次
無論是服務端還是客戶端,一旦一個Watcher 被觸發,Zookeeper 都會將其從對應的儲存中移除。這樣的設計有效的減輕了服務端的壓力,不然對於更新非常頻繁的節點,服務端會不斷的向客戶端發送事件通知,無論對於網路或服務端的壓力都非常大。
(2)客戶端串行執行
客戶端 Watcher 回呼的過程是一個串行同步的過程。
(3)輕量
3.1、Watcher 通知非常簡單,只會告訴客戶端發生了事件,而不會說明事件的具體內容。
3.2、客戶端向服務端註冊 Watcher 的時候,並不會把客戶端真實的 Watcher 物件實體傳遞到服務端,只是在客戶端請求中使用 boolean 類型屬性進行了標記。
(4)watcher event 非同步發送
watcher 的通知事件從server 傳送到client 是異步的,這就存在一個問題,不同的客戶端和伺服器之間透過socket 進行通信,由於網路延遲或其他因素導致客戶端在不通的時刻監聽到事件,由於Zookeeper 本身提供了ordering guarantee,即客戶端監聽事件後,才會感知它所監視znode發生了變化。所以我們使用 Zookeeper 不能期望能夠監控到節點每次的變化。 Zookeeper 只能保證最終的一致性,而無法保證強一致性。
(5)註冊 watcher getData、exists、getChildren
(6)觸發 watcher create、delete、setData
#(7)當一個客戶端連接到一個新的伺服器上時,watch 將會被以任意會話事件觸發。當與一個伺服器失去連線的時候,是無法接收到 watch 的。而當 client 重新連線時,如果需要的話,所有先前註冊過的 watch,都會被重新註冊。通常這是完全透明的。只有在一個特殊情況下,watch 可能會丟失:對於一個未創建的znode的exist watch,如果在客戶端斷開連接期間被創建了,並且隨後在客戶端連接上之前又刪除了,這種情況下,這個watch 事件可能會被遺失。
7.客戶端是如何註冊Watcher 實作
#(1)呼叫getData()/getChildren() /exist()三個API,傳入Watcher 物件
(2)標記請求request,封裝Watcher 到WatchRegistration
(3)封裝成Packet 對象,發送服務端傳送request
(4)收到服務端回應後,將Watcher 註冊到ZKWatcherManager 中進行管理
(5)請求返回,完成註冊。
8. 服務端如何處理Watcher 實作
#(1)服務端接收Watcher 並儲存
接收到客戶端請求,處理請求判斷是否需要註冊Watcher,需要的話將資料節點的節點路徑和ServerCnxn(ServerCnxn 代表一個客戶端和服務端的連接,實現了Watcher 的process 接口,此時可以看成一個Watcher 物件)儲存在WatcherManager 的WatchTable 和watch2Paths 中去。
(2)Watcher 觸發
以服務端接收到setData() 事務請求觸發NodeDataChanged 事件為例:
2.1 封裝WatchedEvent
將通知狀態(SyncConnected)、事件類型(NodeDataChanged)以及節點路徑封裝成一個WatchedEvent 物件
2.2 查詢Watcher
從WatchTable 中根據節點路徑尋找Watcher
2.3 找不到;說明沒有客戶端在該資料節點上註冊過Watcher
2.4 找到;提取並從WatchTable 和Watch2Paths 中刪除對應Watcher(從這裡可以看出Watcher 在服務端是一次性的,觸發一次就失效了)
(3)調用process 方法來觸發Watcher
這裡process 主要是透過ServerCnxn 對應的TCP 連線發送Watcher 事件通知。
9. 客戶端如何回呼Watcher
#客戶端SendThread 執行緒接收事件通知,交由EventThread 執行緒回調Watcher。
客戶端的 Watcher 機制同樣是一次性的,一旦觸發後,該 Watcher 就失效了。
10. 熟悉ACL 權限控制機制嗎?
UGO(User/Group/Others)
目前在 Linux/Unix 檔案系統中使用,也是使用最廣泛的權限控制方式。是一種粗粒度的檔案系統權限控制模式。
ACL(Access Control List)存取控制清單
包括三個面向:
權限模式(Scheme)
(1)IP:從IP 位址粒度進行權限控制
(2)Digest:最常用,用類似username:password 的權限標識來進行權限配置,以便於區分不同應用來進行權限控制
(3)World:最開放的權限控制方式,是一種特殊的digest 模式,只有一個權限標識「world:anyone」
(4)Super:超級使用者
授權物件
授權物件指的是權限賦予的使用者或一個指定實體,例如IP 位址或是機器燈。
權限Permission
(1)CREATE:資料節點建立權限,允許授權物件在該Znode 下建立子節點
( 2)DELETE:子節點刪除權限,允許授權物件刪除該資料節點的子節點
(3)READ:資料節點的讀取權限,允許授權物件存取該資料節點並讀取其資料內容或子節點清單等
(4)WRITE:資料節點更新權限,允許授權物件對該資料節點進行更新操作
(5)ADMIN:資料節點管理權限,允許授權對象對此資料節點進行ACL 相關設定操作
11. 了解Chroot 特性嗎
3.2.0 版本後,新增了Chroot 特性,該特性允許每個客戶端為自己設定一個命名空間。如果一個客戶端設定了 Chroot,那麼該客戶端對伺服器的任何操作,都將會被限制在自己的命名空間下。
透過設定Chroot,能夠將一個客戶端應用於Zookeeper 服務端的一顆子樹相對應,在那些多個應用公用一個Zookeeper 進群的場景下,對實現不同應用間的相互隔離非常有幫助。
12. 熟悉會話管理嗎
分桶策略:將類似的會話放在同一區塊中進行管理,以便於Zookeeper 對會話進行不同區塊的隔離處理以及同一區塊的統一處理。
分配原則:每個會話的「下次逾時時間點」(ExpirationTime)
計算公式:
ExpirationTime_ = currentTime sessionTimeout
#ExpirationTime = (ExpirationTime_ / ExpirationInrerval 1) *
ExpirationInterval , ExpirationInterval 是指Zookeeper 會話逾時檢查時間間隔,預設tickTime
#13. 伺服器有哪些角色
#Leader
(1)交易請求的唯一排程與處理者,保證叢集事務處理的順序性
(2)叢集內部各服務的調度者
Follower
(1)處理客戶端的非事務請求,轉送事務請求給Leader 伺服器
(2)參與事務請求Proposal 的投票
(3)參與Leader 選舉投票
Observer
(1)3.0 版本以後引入的一個伺服器角色,在不影響叢集事務處理能力的基礎上提升叢集的非事務處理能力
(2)處理客戶端的非事務請求,轉發事務請求給Leader 伺服器
(3)不參與任何形式的投票
14. Zookeeper 下Server 工作狀態
伺服器具有四種狀態,分別是LOOKING、FOLLOWING、LEADING、OBSERVING。
(1)LOOKING:尋 找 Leader 狀態。當伺服器處於該狀態時,它會認為目前叢集中沒有 Leader,因此需要進入 Leader 選舉狀態。
(2)FOLLOWING:跟隨者狀態。表示目前伺服器角色是 Follower。
(3)LEADING:領導者狀態。表示目前伺服器角色是 Leader。
(4)OBSERVING:觀察者狀態。表示目前伺服器角色是 Observer。
15.能說說資料是如何同步的嗎?
整個叢集完成 Leader 選舉之後,Learner(Follower 和 Observer 的統稱)迴向Leader 伺服器進行註冊。當 Learner 伺服器想要 Leader 伺服器完成註冊後,進入資料同步環節。
資料同步流程:(皆以訊息傳遞的方式進行)
Learner 向Learder 註冊
資料同步
#同步確認
- # #Zookeeper 的資料同步通常分為四類:(1)直接差異化同步(DIFF 同步)
- (4)全量同步(SNAP 同步)在進行資料同步前,Leader 伺服器會完成資料同步初始化:
- peerLastZxid:
- 從learner 伺服器註冊時發送的ACKEPOCH 訊息中提取lastZxid(該Learner 伺服器最後處理的ZXID)
- minCommittedLog:
場景:peerLastZxid 大於maxCommittedLog
全量同步(SNAP 同步)
場景1:peerLastZxid 小於minCommittedLog 場景2:Leader 伺服器上沒有Proposal 快取佇列且peerLastZxid 不等於lastProcessZxid
##16. zookeeper 是如何保證事務的順序一致性的?
zookeeper 採用了全域遞增的事務Id 來標識,所有的proposal(提議)都在被提出的時候加上了zxid,zxid 實際上是一個64 位的數字,高32 位是epoch( 時期; 紀元; 世; 新時代)用來標識leader 週期,如果有新的leader 產生出來,epoch會自增,低32 位用來遞增計數。當新產生 proposal 的時候,會依據資料庫的兩階段過程,首先會向其他的 server 發出事務執行請求,如果超過半數的機器都能執行並且能夠成功,那麼就會開始執行。17. 分散式叢集中為什麼會有 Master主節點?
在分散式環境中,有些業務邏輯只需要叢集中的某台機器來執行,其他的機器可以共享這個結果,這樣可以大幅減少重複計算,提高性能,於是就需要進行leader 選舉。18. zk 節點宕機如何處理?
Zookeeper 本身也是集群,建議配置不少於 3 個伺服器。 Zookeeper 本身也要保證當一個節點宕機時,其他節點會繼續提供服務。 如果是一個Follower 宕機,還有2 台伺服器提供訪問,因為Zookeeper 上的資料是有多個副本的,資料不會遺失;如果是一個Leader 宕機,Zookeeper 會選出新的Leader。 ZK 叢集的機制是只要超過半數的節點正常,叢集就能正常提供服務。只有在 ZK節點掛太多,只剩下一半或不到一半節點能工作,叢集才會失效。 所以3 個節點的cluster 可以掛掉1 個節點(leader 可以得到2 票>1.5)
2 個節點的cluster 就不能掛掉任何1 個節點了(leader 可以得到1 票<=1)
19. zookeeper 負載平衡與nginx 負載平衡區別
zk 的負載平衡是可以調控,nginx 只是能調權重,其他需要可控的都需要自己寫入插件;但是nginx 的吞吐量比zk 大很多,應該說按業務選擇用哪種方式。
20. Zookeeper 有哪幾種部署模式?
Zookeeper 有三種部署模式:
是單機部署:一台叢集上執行; 叢集部署:多台叢集運作; 偽叢集部署:一台叢集啟動多個Zookeeper 實例運行。
21. 叢集最少要幾台機器,叢集規則是怎樣的?叢集中有 3 台伺服器,其中一個節點宕機,這個時候 Zookeeper 還可以使用嗎?
叢集規則為 2N 1 台,N>0,即 3 台。可以繼續使用,單數伺服器只要沒超過一半的伺服器宕機就可以繼續使用。
22. 叢集支援動態新增機器嗎?
其實就是水平擴容了,Zookeeper 在這方面不太好。兩種方式:
全部重啟:關閉所有 Zookeeper 服務,修改設定之後啟動。不影響之前客戶端的會話。
逐一重啟:在過半存活即可使用的原則下,一台機器重啟不影響整個集群對外提供服務。這是比較常用的方式。
3.5 版本開始支援動態擴容。
23. Zookeeper 對節點的 watch 監聽通知是永久的嗎?
不是。官方聲明:一個 Watch 事件是一個一次性的觸發器,當被設定了 Watch的資料發生了改變的時候,則伺服器將這個變更發送給設定了 Watch 的用戶端,以便通知它們。
為什麼不是永久的,舉個例子,如果服務端變動頻繁,而監聽的客戶端很多情況下,每次變動都要通知到所有的客戶端,給網路和伺服器造成很大壓力。
一般是客戶端執行getData(“/節點A”,true),如果節點A 發生了變更或刪除,客戶端會得到它的watch 事件,但是在之後節點A 又發生了變更,而客戶端又沒有設定watch 事件,就不再傳送給客戶端。
在實際應用中,很多情況下,我們的客戶端不需要知道服務端的每一次變動,我只要最新的資料即可。
24. Zookeeper 的 java 用戶端都有哪些?
java 用戶端:zk 自帶的 zkclient 及 Apache 開源的 Curator。
25. chubby 是什麼,和 zookeeper 比你怎麼看?
chubby 是 google 的,完全實作 paxos 演算法,不開源。 zookeeper 是 chubby的開源實現,使用 zab 協議,paxos 演算法的變種。
26. 說幾個 zookeeper 常用的指令。
常用指令:ls get set create delete 等。
27. ZAB 與 Paxos 演算法的聯繫與差異?
相同點:
(1)兩者都存在一個類似Leader 進程的角色,由其負責協調多個Follower 進程的運作
(2)Leader 流程都會等待超過一半的Follower 做出正確的回饋後,才會將一個提案進行提交
(3)ZAB 協定中,每個Proposal 中都包含一個epoch 值來代表目前的Leader週期,Paxos 中名字為Ballot
不同點:
ZAB 用來建構高可用的分散式資料主備系統(Zookeeper),Paxos 是用來建構分散式一致性狀態機系統。
28. Zookeeper 的典型應用場景
Zookeeper 是一個典型的發布/訂閱模式的分散式數據管理與協調框架,開發人員可以使用它來進行分散式資料的發布和訂閱。
透過對Zookeeper 中豐富的資料節點進行交叉使用,配合Watcher 事件通知機制,可以非常方便的建構一系列分散式應用中年都會涉及的核心功能,如:
(1)資料發布/訂閱
(2)負載平衡
(3)命名服務
(4)分散式協調/通知
#( 5)叢集管理
(6)Master 選舉
(7)分散式鎖定
(8)分散式佇列
29. Zookeeper 都有哪些功能?
叢集管理:監控節點存活狀態、執行請求等;
主節點選舉:主節點掛掉了之後可以從備用的節點開始新一輪選主,主節點選舉說的就是這個選舉的過程,使用Zookeeper 可以協助完成這個過程;
分散式鎖:Zookeeper 提供兩種鎖:獨佔鎖、共享鎖。獨佔鎖即一次只能有一個執行緒使用資源,共享鎖是讀鎖共享,讀寫互斥,也就是可以有多線執行緒同時讀同一個資源,如果要使用寫鎖也只能有一個執行緒使用。 Zookeeper 可以對分散式鎖定進行控制。
命名服務:在分散式系統中,透過使用命名服務,用戶端應用程式能夠根據指定名字來取得資源或服務的位址,提供者等資訊。
30. 說一下 Zookeeper 的通知機制?
client 端會對某個znode 建立一個watcher 事件,當該znode 發生變化時,這些client 會收到zk 的通知,然後client 可以根據znode 變化來做出業務上的改變等。
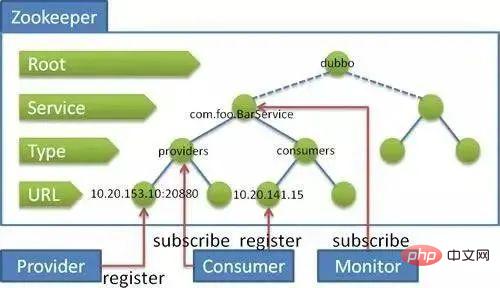
31. Zookeeper 與 Dubbo 的關係?
Zookeeper的作用
zookeeper用來註冊服務和進行負載平衡,哪一個服務由哪一個機器來提供必要讓呼叫者知道,簡單來說就是ip位址和服務名稱的對應關係。當然也可以透過硬編碼的方式把這種對應關係在呼叫方業務代碼中實現,但是如果提供服務的機器掛掉呼叫者無法知曉,如果不更改代碼會繼續請求掛掉的機器提供服務。 zookeeper透過心跳機制可以偵測掛掉的機器並將掛掉機器的ip和服務對應關係從清單中刪除。至於支援高並發,簡單來說就是橫向擴展,在不更改程式碼的情況透過添加機器來提高運算能力。透過增加新的機器向zookeeper註冊服務,服務的提供者多了能服務的客戶就多了。
dubbo
是管理中間層的工具,在業務層到資料倉儲間有非常多服務的存取和服務提供者需要調度,dubbo提供一個框架解決這個問題。
Note that the dubbo here is just a frame. What you put on the shelf is completely up to you, just like a car skeleton, you need to match your wheel engine. To complete the scheduling in this framework, there must be a distributed registration center to store the metadata of all services. You can use zk or others, but everyone uses zk.
The relationship between zookeeper and dubbo:
Dubbo abstracts the registration center and can connect different storage media to provide services to the registration center. , including ZooKeeper, Memcached, Redis, etc.
The introduction of ZooKeeper as a storage medium also introduces the features of ZooKeeper. The first is load balancing. The carrying capacity of a single registration center is limited. When the traffic reaches a certain level, it needs to be diverted. Load balancing exists for the purpose of diverting traffic. A ZooKeeper group can easily achieve load balancing with the corresponding web application. ; Resource synchronization, load balancing alone is not enough, data and resources between nodes need to be synchronized, and ZooKeeper clusters naturally have such a function; naming service, using a tree structure to maintain a global service address list, service providers When starting, write your own URL address to the /dubbo/${serviceName}/providers directory of the specified node on ZooKeeper. This operation completes the release of the service. Other features include Mast election, distributed locks, etc.
以上是【建議收藏】靈魂拷問! Zookeeper的31連環砲的詳細內容。更多資訊請關注PHP中文網其他相關文章!