
明牌:OpenAI 發布帶有「身分識別」的網路爬蟲工具 GPTBot

- 王林轉載
- 2023-08-12 17:21:061304瀏覽
本站 8 月 8 日消息,OpenAI 昨日發布了旗下網路爬蟲工具 GPTBot。官方宣稱,該 GPTBot 工具能夠在註重版權的基礎上,使用透明的方式收集網頁信息,來訓練 OpenAI 旗下的各 AI 模型。
OpenAI 表示,GPTBot 使用專有網頁UA 表示其爬蟲身分,完整UA 字串為(Mozilla / 5.0 AppleWebKit / 537.36 / KHTML, like Gecko; compatible; GPTBot / 1.0; https://openai.com/ gptbot),任何網站管理者都可以自由允許或阻止該爬蟲工具進行資料收集。

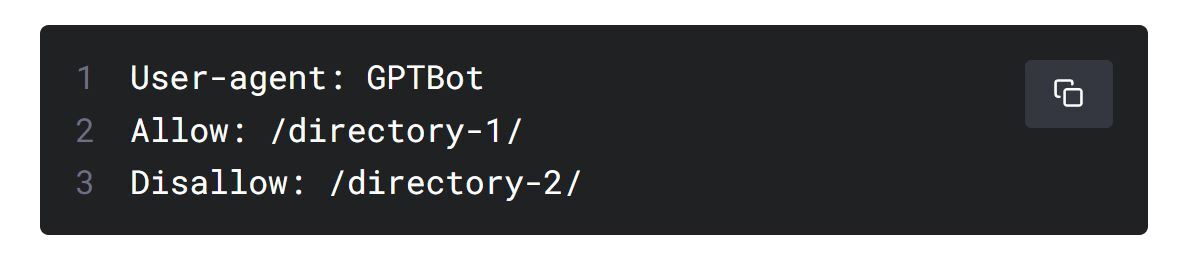
OpenAI 聲稱,若網站管理員不希望被爬蟲蒐集資料,管理員可以在網站伺服器的robots.txt 檔案中完全禁止GPTBot 抓取訊息,或自行決定GPTBot 抓取網站上的指定資訊。
OpenAI之前因被指控侵犯隱私問題而備受業界批評,現在推出了GPTBot爬蟲工具,這可以看作是對外界批評的回應,並且有助於行業建立AI訓練用爬蟲工具的相關基準。據報道,OpenAI最近註冊了GPT-5商標,這款GPTBot爬蟲工具也有望為GPT-5的相關模型訓練提供支持
本站文章中包含的對外跳轉鏈接(如超鏈接、二維碼、口令等形式)僅用於提供更多信息,節省篩選時間,結果僅供參考。請注意,所有文章均帶有此廣告聲明
以上是明牌:OpenAI 發布帶有「身分識別」的網路爬蟲工具 GPTBot的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:ithome.com。如有侵權,請聯絡admin@php.cn刪除