
詳解16個Pandas函數,讓你的 「資料清洗」 能力提高100倍!

- Python当打之年轉載
- 2023-08-10 16:22:461782瀏覽
本文介紹


1個資料集,16個Pandas函數
import pandas as pd
df ={'姓名':[' 黄同学','黄至尊','黄老邪 ','陈大美','孙尚香'],
'英文名':['Huang tong_xue','huang zhi_zun','Huang Lao_xie','Chen Da_mei','sun shang_xiang'],
'性别':['男','women','men','女','男'],
'身份证':['463895200003128433','429475199912122345','420934199110102311','431085200005230122','420953199509082345'],
'身高':['mid:175_good','low:165_bad','low:159_bad','high:180_verygood','low:172_bad'],
'家庭住址':['湖北广水','河南信阳','广西桂林','湖北孝感','广东广州'],
'电话号码':['13434813546','19748672895','16728613064','14561586431','19384683910'],
'收入':['1.1万','8.5千','0.9万','6.5千','2.0万']}
df = pd.DataFrame(df)
df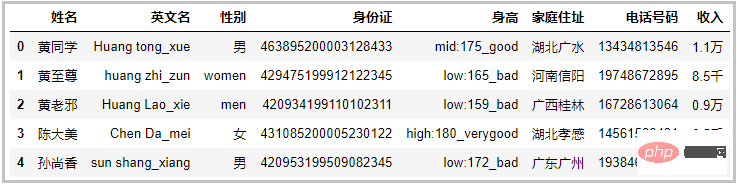
① cat函数:用于字符串的拼接
df["姓名"].str.cat(df["家庭住址"],sep='-'*3)

② contains:判断某个字符串是否包含给定字符
df["家庭住址"].str.contains("广")
③ startswith/endswith:判断某个字符串是否以…开头/结尾
# 第一个行的“ 黄伟”是以空格开头的
df["姓名"].str.startswith("黄")
df["英文名"].str.endswith("e")
④ count:计算给定字符在字符串中出现的次数
df["电话号码"].str.count("3")
⑤ get:获取指定位置的字符串
df["姓名"].str.get(-1)
df["身高"].str.split(":")
df["身高"].str.split(":").str.get(0)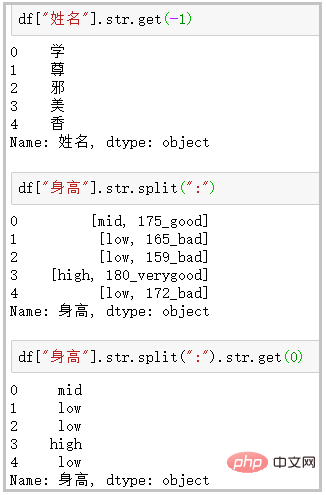
⑥ len:计算字符串长度
df["性别"].str.len()

⑦ upper/lower:英文大小写转换
df["英文名"].str.upper() df["英文名"].str.lower()

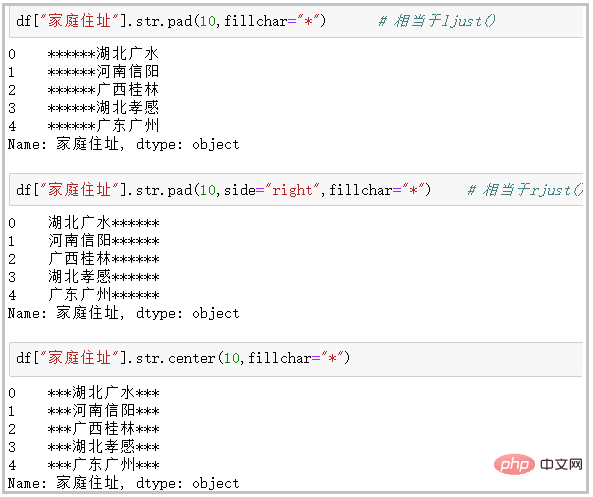
⑧ pad+side参数/center:在字符串的左边、右边或左右两边添加给定字符
df["家庭住址"].str.pad(10,fillchar="*") # 相当于ljust() df["家庭住址"].str.pad(10,side="right",fillchar="*") # 相当于rjust() df["家庭住址"].str.center(10,fillchar="*")
⑨ repeat:重复字符串几次
df["性别"].str.repeat(3)

⑩ slice_replace:使用给定的字符串,替换指定的位置的字符
df["电话号码"].str.slice_replace(4,8,"*"*4)

⑪ replace:将指定位置的字符,替换为给定的字符串
df["身高"].str.replace(":","-")
⑫ replace:将指定位置的字符,替换为给定的字符串(接受正则表达式)
replace中传入正则表达式,才叫好用; 先不要管下面这个案例有没有用,你只需要知道,使用正则做数据清洗多好用;
df["收入"].str.replace("\d+\.\d+","正则")
⑬ split方法+expand参数:搭配join方法功能很强大
# 普通用法
df["身高"].str.split(":")
# split方法,搭配expand参数
df[["身高描述","final身高"]] = df["身高"].str.split(":",expand=True)
df
# split方法搭配join方法
df["身高"].str.split(":").str.join("?"*5)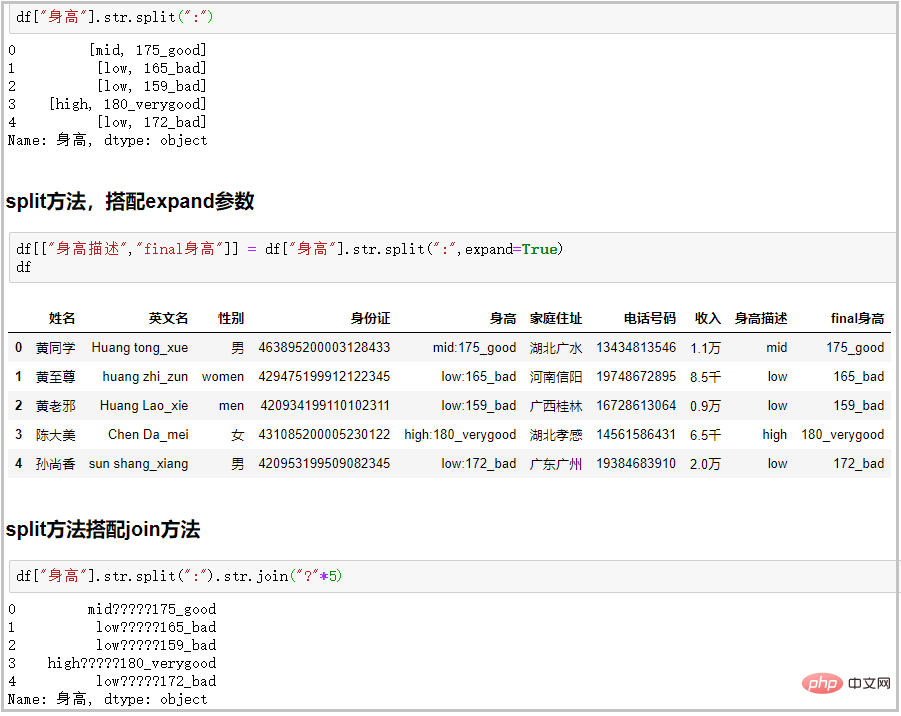
⑭ strip/rstrip/lstrip:去除空白符、换行符
df["姓名"].str.len() df["姓名"] = df["姓名"].str.strip() df["姓名"].str.len()

⑮ findall:利用正则表达式,去字符串中匹配,返回查找结果的列表
findall使用正则表达式,做数据清洗,真的很香!
df["身高"]
df["身高"].str.findall("[a-zA-Z]+")
⑯ extract/extractall:接受正则表达式,抽取匹配的字符串(一定要加上括号)
df["身高"].str.extract("([a-zA-Z]+)")
# extractall提取得到复合索引
df["身高"].str.extractall("([a-zA-Z]+)")
# extract搭配expand参数
df["身高"].str.extract("([a-zA-Z]+).*?([a-zA-Z]+)",expand=True)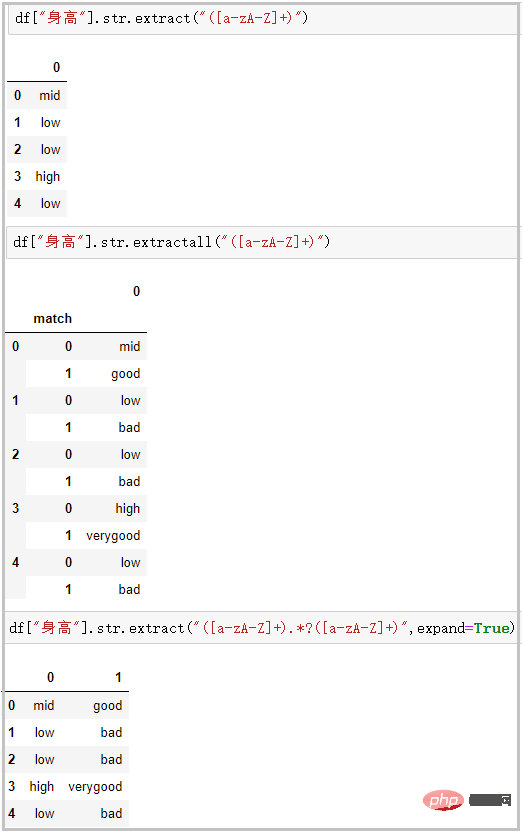
以上是詳解16個Pandas函數,讓你的 「資料清洗」 能力提高100倍!的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:Python当打之年。如有侵權,請聯絡admin@php.cn刪除