
技巧|Python 批次自動提取、整理 PDF 發票

- Python当打之年轉載
- 2023-08-10 15:58:202402瀏覽
本文分享一個基於PDF 的Python 辦公室自動化的案例解決,也是某位財務小姐姐提出的真實需求,先來看看需求。
需求描述
在某個資料夾下有多個PDF 類型發票
每一張發票PDF 是純圖片類型,裡面的文字資訊無法手動複製(事實上大多數發票可以複製部分文字,但我們丟以圖片形式來講解),大致如下圖所示: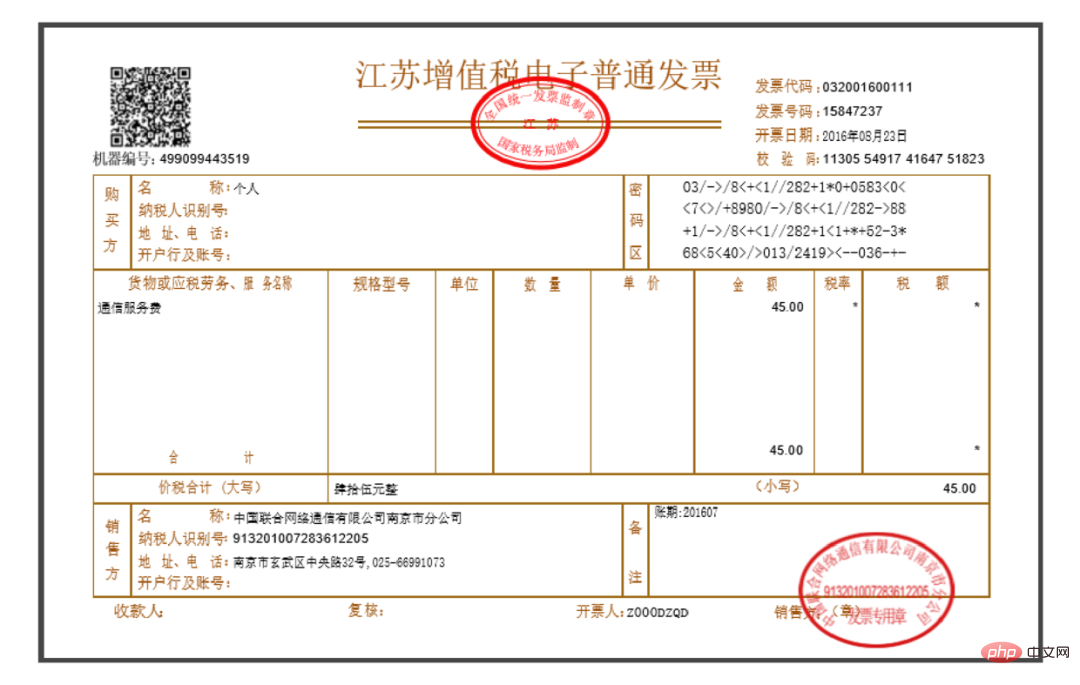
需要滿足的需求是:取得總金額、納稅人識別號碼、開票人,即如下三個方框位置:
最後結合批量操作,在獲取上述資訊後將其儲存入Excel 中! 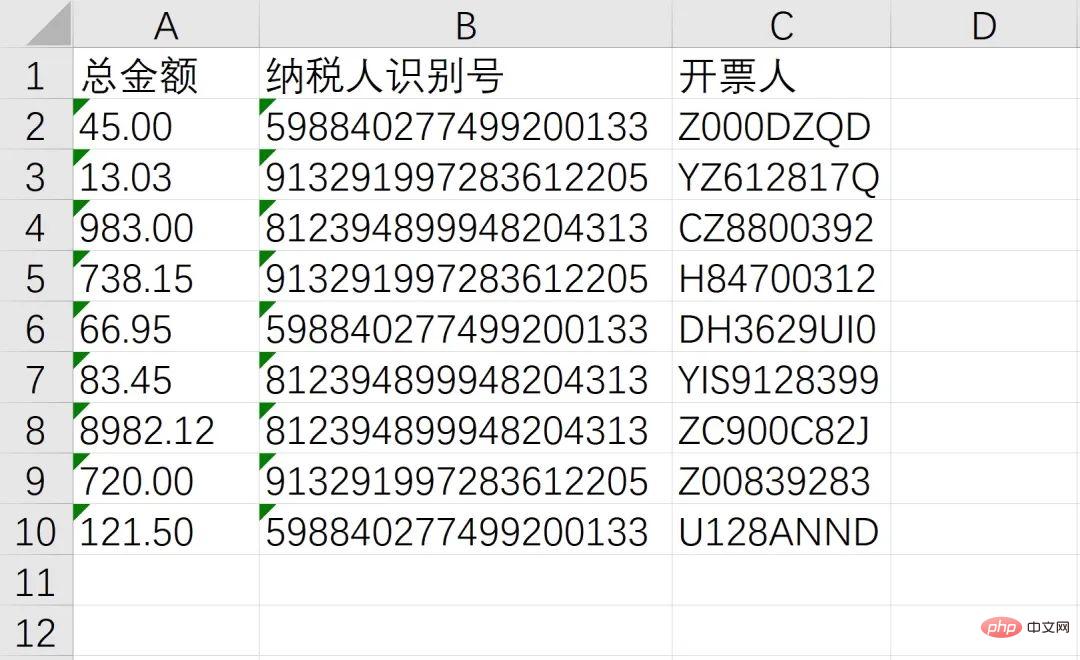
想法與程式碼實作
需求本質是一個圖片辨識問題,因為PDF 裡的內容是圖片類型,無法按常規方法直接把文本抽提出來。解決想法是利用光學字元辨識(OCR)將圖片中的文字辨識出。但同時也需要注意,PDF 畢竟不是圖片,為了完成 OCR,除了OCR自身之外還要下載 Ghostscript 和 ImageMagick 用來完成型別轉換。已 Windows 系統為例,需要在電腦上安裝以下三個軟體:
Ghostscript32 位元#ImageMagick32 位元#tesseract-OCR32 位元
三個軟體的下載安裝沒有特殊的地方(tesseract 設定稍複雜但網路有上諸多教程,這裡不再贅述),讀者可自行搜尋下載及配置,以下講解程式碼。首先導入需要的模組:
from wand.image import Image from PIL import Image as PI import pyocr import pyocr.builders import io import re import os import shutil
具體的模組用途可以參考下面具體程式碼。其中 wand 和 pyocr 由於是非標準函式庫需要自行額外安裝。開啟命令列輸入:
pip install wand pip install pyocr
本需求也涉及對接Excel,可考慮利用openpyxl 函式庫的Workbook 用以建立新的Excel 檔案:
from openpyxl import Workbook
需求中的發票.pdf 放在桌面上。可透過下方基於 os 模組的程式碼取得桌面路徑:
# 获取桌面路径包装成一个函数
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
path = GetDesktopPath() + r'\发票.pdf'取得配置好的 tesseract 便於後面呼叫:
tool = pyocr.get_available_tools()[0]
通过 wand 模块将 PDF 文件转化为分辨率为 300 的 jpeg 图片形式:
image_pdf = Image(filename=path, resolution=300) image_jpeg = image_pdf.convert('jpeg')
将图片解析为二进制矩阵:
image_lst = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
image_lst.append(img_page.make_blob('jpeg'))用 io 模块的 BytesIO 方法读取二进制内容为图片形式:
new_img = PI.open(io.BytesIO(image_lst[0])) new_img.show()
接下来分别截取需要提取部位字符串的图片了,尽量让图片中只有需要识别的部分,获取识别出来容易简单处理获得需要的内容。
首先以总金额为例,截取图片用 image.crop((left, top, right, bottom)) 四个参数需要反复调试才能确定。经确定四个参数分别是 1600 760 1830 900,尝试截取和预览图片:
### 解析1Z开头码 left = 350 top = 600 right = 1300 bottom = 730 image_obj1 = new_img.crop((left, top, right, bottom)) image_obj1.show()
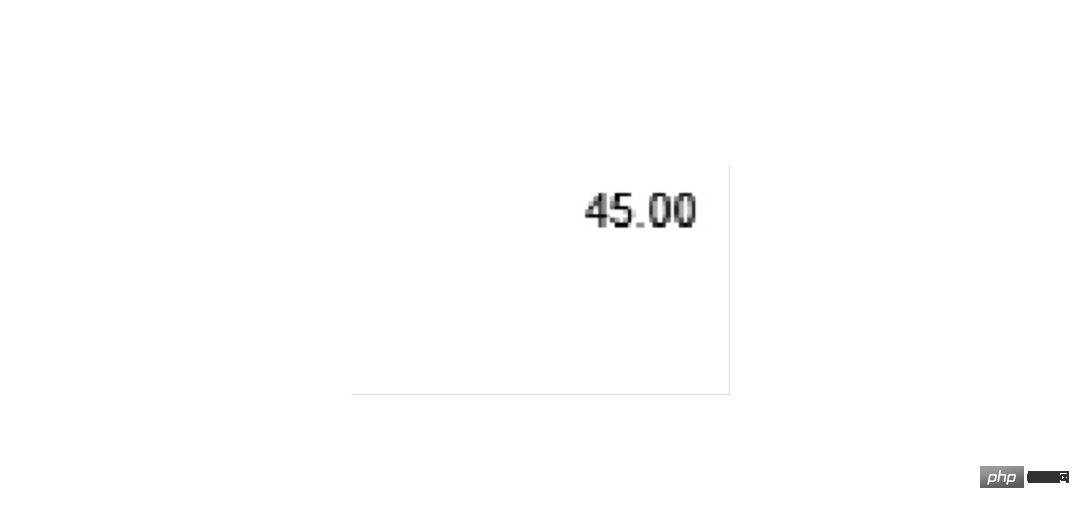
截取成功后可以交给 OCR 了,代码为 tool.image_to_string()
txt1= tool.image_to_string(image_obj1) print(txt1)

同样,通过方位的调试就可以准确切割到需要的部分进行识别:
left = 560 top = 1260 right = 900 bottom = 1320 image_obj2 = new_img.crop((left, top, right, bottom)) # image_obj2.show() txt2 = tool.image_to_string(image_obj2) # print(txt2)
最后是开票人的识别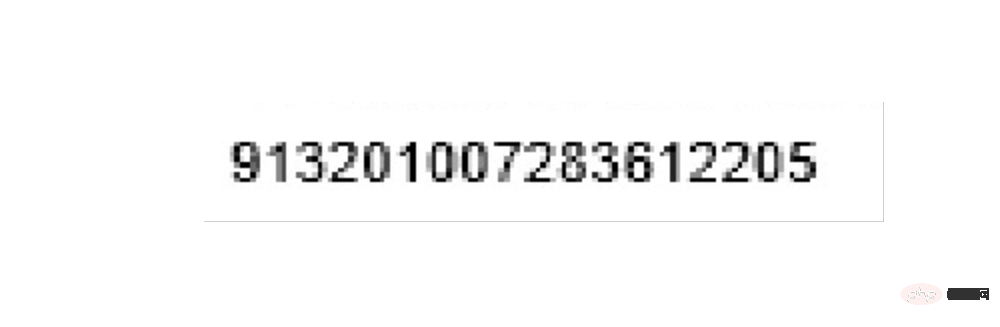
left = 1420 top = 1420 right = 1700 bottom = 1500 image_obj3 = new_img.crop((left, top, right, bottom)) # image_obj3.show() txt3 = tool.image_to_string(image_obj3) # print(txt3)
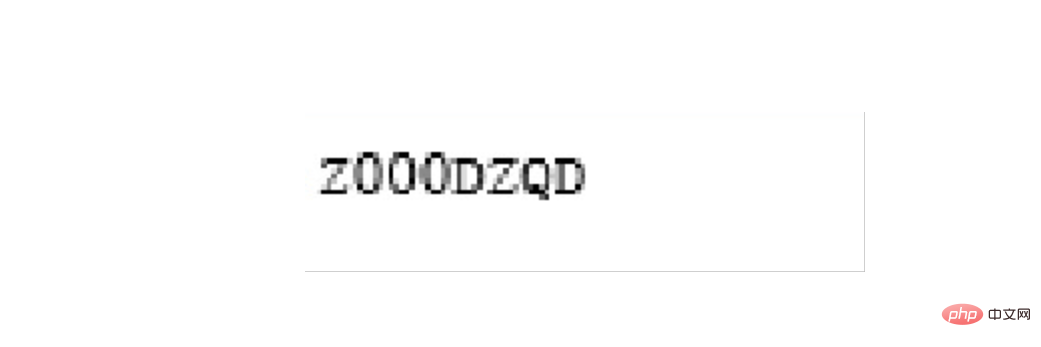
需要确认识别的内容是否正确,如果识别正确率欠佳可以考虑通过图片处理技术消除噪声,也可以去官网下载更高精度的训练包提高识别的正确性
至此,我们成功的识别了总金额、纳税人识别号、开票人三个消息,接下来就通过非常熟悉的 openpyxl 写入Excel,并使用 os 模块实现批量操作即可
workbook = Workbook() sheet = workbook.active header = ['总金额', '纳税人识别号', '开票人'] sheet.append(header) sheet.append([txt1, txt2, txt3]) workbook.save(GetDesktopPath() + r'\汇总.xlsx')
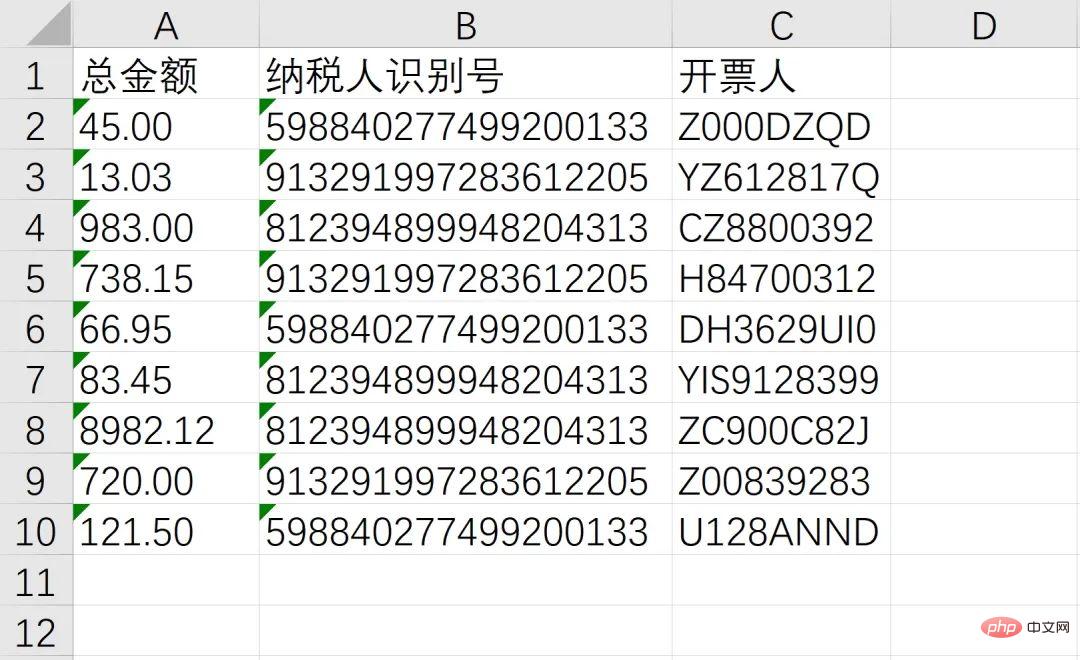
综上,整个需求就成功实现,从效果来看还是非常不错的!完整源码可由文中代码组合而成(已全部分享在文中),感兴趣的读者可以自己尝试!
最后想说的是,其实本文的案例可以衍生出很多实用的办公自动化脚本,例如
批量计算发票金额并重命名文件夹 根据发票类型批量分类 根据发票批量制作报销单 ··· ···
以上是技巧|Python 批次自動提取、整理 PDF 發票的詳細內容。更多資訊請關注PHP中文網其他相關文章!