
微軟最新推出的NaturalSpeech2語音合成模型:提供更精確的語音重構,避免棒讀效果

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-08-04 09:41:051199瀏覽

7 月27 日訊息,微軟日前推出了名為NaturalSpeech2 的語音模型,該模型採用「潛在擴散」式設計,在零樣本語音合成層面效果出眾,微軟宣稱該模型提供了「商業級」的語音/ 歌唱解決方案,能夠給予用戶高品質、多樣化的語音合成體驗。
微軟進行了一系列演示,展示了NaturalSpeech2 在沒有樣本的情況下生成具有不同說話人身份、韻律和風格(如唱歌)的語音的能力

#▲ 圖源來自NaturalSpeech 2 論文
據悉,與傳統的語音轉文字(TTS)系統不同,微軟的NaturalSpeech2 使用「連續向量」取代「離散標記」來表示語音,從而產生更完整的語音片段,不會產生「缺乏感情」的「棒讀(一字一頓地講話)」現象。
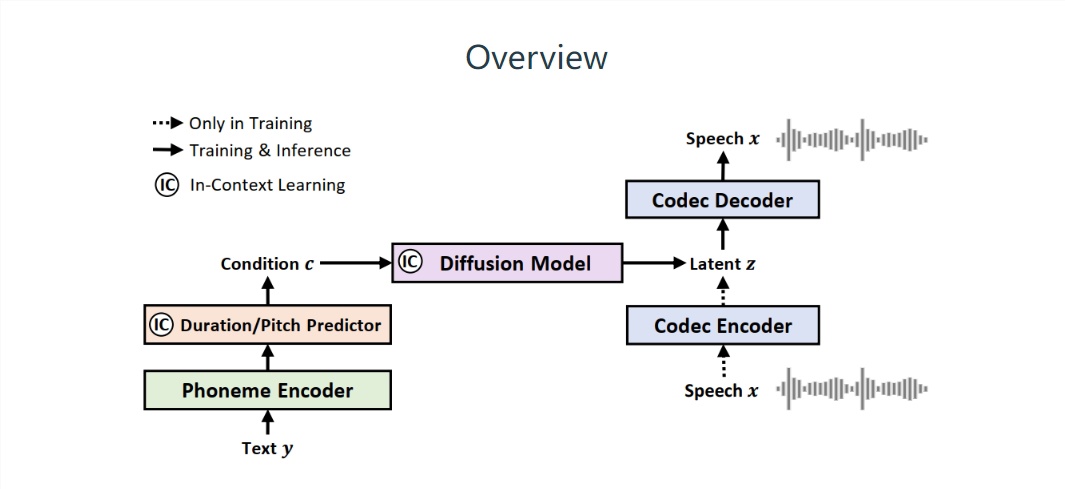
▲ 圖源來自NaturalSpeech 2 論文
實驗結果表明,NaturalSpeech2 在零樣本條件下產生的語音與語音提示和真實語音的韻律幾乎一致,並且在LibriTTS 和VCTK 測試集上的自然度(以CMOS 為度量)與真人語音難以區分。
該專案的論文目前已經發佈於 GitHub 中,有興趣的IT之家小夥伴可以點此造訪。
以上是微軟最新推出的NaturalSpeech2語音合成模型:提供更精確的語音重構,避免棒讀效果的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:51cto.com。如有侵權,請聯絡admin@php.cn刪除