



#Prometheus 是一款基於時序資料庫的開源監控告警系統,說起Prometheus 則不得不提SoundCloud,這是一個線上音樂分享的平台,類似於做影片分享的YouTube,由於他們在微服務架構的道路上越走越遠,出現了數百上千的服務,使用傳統的監控系統StatsD 和Graphite 有大量的限制。
於是他們在 2012 年開始著手開發一套全新的監控系統。 Prometheus 的原作者是Matt T. Proud,他也是在2012 年加入SoundCloud 的,實際上,在加入SoundCloud 之前,Matt 一直就職於Google,他從Google 的集群管理器Borg 和它的監控系統Borgmon 中獲取靈感,開發了開源的監控系統Prometheus,和Google 的許多專案一樣,使用的程式語言是Go。
很顯然,Prometheus 作為一個微服務架構監控系統的解決方案,它和容器也脫不開關係。早在 2006 年 8 月 9 日,Eric Schmidt 在搜尋引擎大會上首次提出了雲端運算(Cloud Computing)的概念,在之後的十多年裡,雲端運算的發展勢如破竹。
在2013 年,Pivotal 的Matt Stine 又提出了雲端原生(Cloud Native)的概念,雲端原生由微服務架構、DevOps 和以容器為代表的敏捷基礎架構組成,幫助企業快速、持續、可靠、規模化地交付軟體。
為了統一雲端運算介面和相關標準,2015 年 7 月,隸屬於 Linux 基金會的 雲端原生運算基金會(CNCF,Cloud Native Computing Foundation) 應運而生。第一個加入 CNCF 的專案是 Google 的 Kubernetes,而 Prometheus 是第二個加入的(2016 年)。
目前Prometheus 已經廣泛用於Kubernetes 集群的監控系統中,對Prometheus 的歷史感興趣的同學可以看看SoundCloud 的工程師Tobias Schmidt 在2016 年的PromCon 大會上的演講:The History of Prometheus at SoundCloud 。
一、Prometheus 概述
我們在SoundCloud 的官方部落格中可以找到一篇關於他們為什麼需要新開發一個監控系統的文章Prometheus: Monitoring at SoundCloud,在這篇文章中,他們介紹到,他們需要的監控系統必須滿足以下四個特性:
簡單來說,就是下面四個特性:
多維度資料模型 方便的部署與維護 靈活的資料擷取 強大的查詢語言
實際上,多維度資料模型和強大的查詢語言這兩個特性,正是時序資料庫所要求的,所以Prometheus 不只是一個監控系統,同時也是一個時序資料庫。那為什麼 Prometheus 不直接使用現有的時序資料庫作為後端儲存呢?這是因為 SoundCloud 不僅希望他們的監控系統有著時序資料庫的特點,而且還需要部署和維護非常方便。
縱觀比較流行的時序資料庫(請參閱下面的附錄),他們要麼組件太多,要麼外部依賴繁重,例如:Druid 有Historical、MiddleManager、Broker、Coordinator、Overlord、Router 一堆的組件,而且也依賴ZooKeeper、Deep storage(HDFS 或S3 等),Metadata store(PostgreSQL 或MySQL),部署和維護起來成本非常高。而 Prometheus 採用去中心化架構,可以獨立部署,不依賴外部的分散式存儲,你可以在幾分鐘的時間內就可以搭建出一套監控系統。
此外,Prometheus 資料收集方式也非常靈活。要收集目標的監控數據,首先需要在目標處安裝數據採集組件,這被稱之為Exporter,它會在目標處收集監控數據,並暴露出一個HTTP 接口供Prometheus 查詢,Prometheus 透過Pull 的方式來採集數據,這和傳統的Push 模式不同。
不過 Prometheus 也提供了一種方式來支援 Push 模式,你可以將你的資料推送到 Push Gateway,Prometheus 透過 Pull 的方式從 Push Gateway 取得資料。目前的 Exporter 已經可以採集絕大多數的第三方數據,例如 Docker、HAProxy、StatsD、JMX 等等,官網有一份 Exporter 的列表。
除了這四大特性,隨著Prometheus 的不斷發展,開始支援越來越多的高級特性,例如:服務發現,更豐富的圖表展示,使用外部存儲,強大的告警規則和多樣的通知方式。下圖是Prometheus 的整體架構圖:
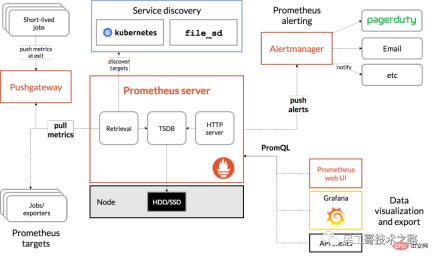
從上圖可以看出,Prometheus 生態系統包含了幾個關鍵的元件:Prometheus server、Pushgateway、Alertmanager、Web UI 等,但是大多數元件都不是必需的,其中最核心的元件當然是Prometheus server,它負責收集和儲存指標數據,支援表達式查詢,和告警的生成。接下來我們就來安裝 Prometheus server。
二、安裝 Prometheus server
Prometheus 可以支援多種安裝方式,包括 Docker、Ansible、Chef、Puppet、Saltstack 等。以下介紹最簡單的兩種方式,一種是直接使用編譯好的可執行文件,開箱即用,另一種是使用 Docker 映像。
2.1 開箱即用
首先從官網的下載頁面取得Prometheus 的最新版本和下載位址,目前最新版本是2.4.3(2018年10月),執行下面的指令下載並解壓縮:
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
然後切換到解壓縮目錄,檢查Prometheus 版本:
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
運行Prometheus server:
$ ./prometheus --config.file=prometheus.yml
2.2 使用 Docker 镜像
使用 Docker 安装 Prometheus 更简单,运行下面的命令即可:
$ sudo docker run -d -p 9090:9090 prom/prometheus
一般情况下,我们还会指定配置文件的位置:
$ sudo docker run -d -p 9090:9090 \
-v ~/docker/prometheus/:/etc/prometheus/ \
prom/prometheus我们把配置文件放在本地 ~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过 -v 参数将本地的配置文件挂载到 /etc/prometheus/ 位置,这是 prometheus 在容器中默认加载的配置文件位置。如果我们不确定默认的配置文件在哪,可以先执行上面的不带 -v 参数的命令,然后通过 docker inspect 命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):
$ sudo docker inspect 0c
[...]
"Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46",
"Created": "2018-10-15T22:27:34.56050369Z",
"Path": "/bin/prometheus",
"Args": [
"--config.file=/etc/prometheus/prometheus.yml",
"--storage.tsdb.path=/prometheus",
"--web.console.libraries=/usr/share/prometheus/console_libraries",
"--web.console.templates=/usr/share/prometheus/consoles"
],
[...]2.3 配置 Prometheus
正如上面两节看到的,Prometheus 有一个配置文件,通过参数 --config.file 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 prometheus.yml 看下里面的内容:
/etc/prometheus $ cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']Prometheus 默认的配置文件分为四大块:
global 區塊:Prometheus 的全域配置,例如scrape_interval 表示Prometheus 多久抓取一次數據,evaluation_interval 表示多久偵測一次告警規則; alerting 區塊:關於Alertmanager 的配置,這個我們後面再看; rule_files 區塊:警告規則,這個我們後面再看; scrape_config 區塊:這裡定義了Prometheus 要抓取的目標,我們可以看到預設已經配置了一個名稱為prometheus 的job,這是因為Prometheus 在啟動的時候也會透過HTTP 介面暴露自身的指標數據,這就相當於Prometheus 自己監控自己,雖然這在真正使用Prometheus 時沒啥用處,但是我們可以透過這個例子來學習如何使用Prometheus;可以訪問http://localhost:9090/metrics 查看Prometheus 暴露了哪些指標;
#三、學習PromQL
透過上面的步驟安裝好Prometheus 之後,我們現在可以開始體驗Prometheus 了。 Prometheus 提供了可視化的Web UI 方便我們操作,直接訪問http://localhost:9090/ 即可,它默認會跳到Graph 頁面:
第一次訪問這個頁面可能會不知所措,我們可以先看看其他選單下的內容,例如:Alerts 展示了定義的所有告警規則,Status 可以查看各種Prometheus 的狀態信息,有Runtime & Build Information、Command-Line Flags、Configuration、Rules、Targets、 Service Discovery 等等。
實際上 Graph 頁面才是 Prometheus 最強大的功能,在這裡我們可以使用 Prometheus 提供的一種特殊表達式來查詢監控數據,這個表達式被稱為 PromQL(Prometheus Query Language)。透過 PromQL 不僅可以在 Graph 頁面查詢數據,還可以透過 Prometheus 提供的 HTTP API 來查詢。查詢的監控資料有清單和曲線圖兩種展現形式(對應上圖 Console 和 Graph 這兩個標籤)。
我們上面說過,Prometheus 本身也揭露了許多的監控指標,也可以在Graph 頁面查詢,展開Execute 按鈕旁的下拉框,可以看到很多指標名稱,我們隨便選一個,譬如: promhttp_metric_handler_requests_total,這個指標表示/metrics 頁面的訪問次數,Prometheus 就是透過這個頁面來抓取自身的監控資料的。在Console 標籤中查詢結果如下:
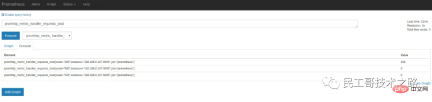
上面在介紹Prometheus 的設定檔時,可以看到scrape_interval 參數是15s,也就是說Prometheus 每15s 造訪一次/metrics頁面,所以我們過15s 刷新下頁面,可以看到指標值會自增。在 Graph 標籤中可以看得更明顯:
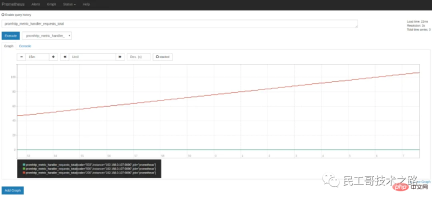
3.1 数据模型
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
promhttp\_metric\_handler\_requests\_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。另外,搜索公众号Linux就该这样学后台回复“Linux”,获取一份惊喜礼包。
这种数据模型和 OpenTSDB 的数据模型是比较类似的,详细的信息可以参考官网文档 Data model。
虽然 Prometheus 里存储的数据都是 float64 的一个数值,但如果我们按类型来分,可以把 Prometheus 的数据分成四大类:
Counter Gauge #Histogram - ##Summary
3.2 PromQL 入门
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查 up
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
up{instance="192.168.0.107:9090",job="prometheus"} 1
up{instance="192.168.0.108:9090",job="prometheus"} 1
up{instance="192.168.0.107:9100",job="server"} 1
up{instance="192.168.0.108:9104",job="mysql"} 0也可以指定某个 label 来查询:
up{job="prometheus"}这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
up{job!="prometheus"}
up{job=~"server|mysql"}
up{job=~"192\.168\.0\.107.+"}
#=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
http_requests_total[5m]
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
# 计算的是每秒的平均值,适用于变化很慢的 counter # per-second average rate of increase, for slow-moving counters rate(http_requests_total[5m]) # 计算的是每秒瞬时增加速率,适用于变化很快的 counter # per-second instant rate of increase, for volatile and fast-moving counters irate(http_requests_total[5m])
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
3.3 HTTP API
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
GET /api/v1/query GET /api/v1/query_range GET /api/v1/series GET /api/v1/label/<label_name>/values GET /api/v1/targets GET /api/v1/rules GET /api/v1/alerts GET /api/v1/targets/metadata GET /api/v1/alertmanagers GET /api/v1/status/config GET /api/v1/status/flags
从 Prometheus v2.1 开始,又新增了几个用于管理 TSDB 的接口:
POST /api/v1/admin/tsdb/snapshot POST /api/v1/admin/tsdb/delete_series POST /api/v1/admin/tsdb/clean_tombstones
四、安装 Grafana
虽然 Prometheus 提供的 Web UI 也可以很好的查看不同指标的视图,但是这个功能非常简单,只适合用来调试。要实现一个强大的监控系统,还需要一个能定制展示不同指标的面板,能支持不同类型的展现方式(曲线图、饼状图、热点图、TopN 等),这就是仪表盘(Dashboard)功能。
因此 Prometheus 开发了一套仪表盘系统 PromDash,不过很快这套系统就被废弃了,官方开始推荐使用 Grafana 来对 Prometheus 的指标数据进行可视化,这不仅是因为 Grafana 的功能非常强大,而且它和 Prometheus 可以完美的无缝融合。
Grafana 是一个用于可视化大型测量数据的开源系统,它的功能非常强大,界面也非常漂亮,使用它可以创建自定义的控制面板,你可以在面板中配置要显示的数据和显示方式,它 支持很多不同的数据源,比如:Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus 等,而且它也 支持众多的插件。
下面我们就体验下使用 Grafana 来展示 Prometheus 的指标数据。首先我们来安装 Grafana,我们使用最简单的 Docker 安装方式:
$ docker run -d -p 3000:3000 grafana/grafana
运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问 http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。
要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
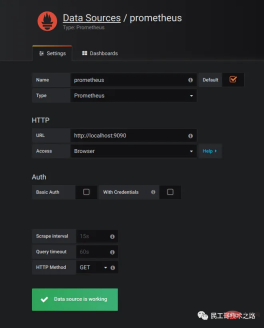
我们在这里依次填上:
Name: prometheus Type: Prometheus URL: http://localhost:9090 Access: Browser
要注意的是,這裡的Access 指的是Grafana 存取資料來源的方式,有Browser 和Proxy 兩種方式。 Browser 方式表示當使用者存取Grafana 面板時,瀏覽器直接透過URL 存取資料來源的;而Proxy 方式表示瀏覽器先存取Grafana 的某個代理介面(介面位址是/api/datasources/proxy/),由Grafana 的服務端來存取資料來源的URL,如果資料來源是部署在內網,使用者透過瀏覽器無法直接存取時,這種方式非常有用。
配置好資料來源,Grafana 會預設提供幾個已經配置好的面板供你使用,如下圖所示,預設提供了三個面板:Prometheus Stats、Prometheus 2.0 Stats 和 Grafana metrics。點擊 Import 就可以匯入並使用該面板。
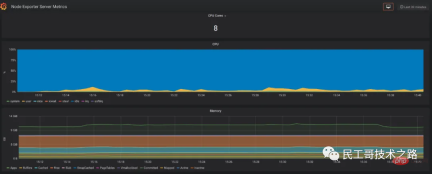
我們導入 Prometheus 2.0 Stats 這個面板,可以看到下面這樣的監控面板。如果你的公司有條件,可以申請個大顯示器掛在牆上,將這個面板投影在大螢幕上,即時觀察線上系統的狀態,可以說是非常 cool 的。
五、使用Exporter 收集指標
目前為止,我們看到的都還只是一些沒有實際用途的指標,如果我們要在我們的生產環境中真正使用Prometheus,往往需要關注各種各樣的指標,譬如伺服器的CPU負載、記憶體佔用量、IO開銷、入網和出網流量等等。
正如上面所說,Prometheus 是使用Pull 的方式來獲取指標數據的,要讓Prometheus 從目標處獲得數據,首先必須在目標上安裝指標收集的程序,並暴露出HTTP 接口供Prometheus查詢,這個指標收集程序被稱為Exporter,不同的指標需要不同的Exporter 來收集,目前已經有大量的Exporter 可供使用,幾乎囊括了我們常用的各種系統和軟體。
官網列出了一份 常用 Exporter 的清單,各個 Exporter 都遵循一份端口約定,避免端口衝突,即從 9100 開始依次遞增,這裡是 完整的 Exporter 端口列表。另外值得注意的是,有些軟體和系統不需要安裝 Exporter,這是因為他們本身就提供了暴露 Prometheus 格式的指標資料的功能,例如 Kubernetes、Grafana、Etcd、Ceph 等。
這一節就讓我們來收集一些有用的數據。
5.1 收集服务器指标
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporter
node_exporter 启动之后,我们访问下 /metrics 接口看看是否能正常获取服务器指标:
$ curl http://localhost:9100/metrics
如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.0.107:9090']
- job_name: 'server'
static_configs:
- targets: ['192.168.0.107:9100']修改配置后,需要重启 Prometheus 服务,或者发送 HUP 信号也可以让 Prometheus 重新加载配置:
$ killall -HUP prometheus
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
在Graph 頁面的指標下拉框可以看到很多名稱以node 開頭的指標,譬如我們輸入 node_load1觀察伺服器負載:
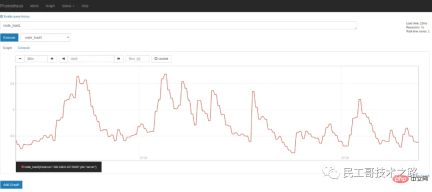
如果您想在Grafana 中查看伺服器的指標,可以在Grafana 的Dashboards 頁面搜尋node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或Node Exporter Full 等。我們開啟 Grafana 的 Import dashboard 頁面,輸入面板的 URL(https://grafana.com/dashboards/405)或 ID(405)即可。
注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter \ --path.rootfs /host
关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter。
5.2 收集 MySQL 指标
mysqld_exporter 是 Prometheus 官方提供的一个 exporter,我们首先 下载最新版本 并解压(开箱即用):
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/
mysqld_exporter 需要连接到 mysqld 才能收集它的指标,可以通过两种方式来设置 mysqld 数据源。第一种是通过环境变量 DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。
$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporter
另一种方式是通过配置文件,默认的配置文件是 ~/.my.cnf,或者通过 --config.my-cnf 参数指定:
$ ./mysqld_exporter --config.my-cnf=".my.cnf"
配置文件的格式如下:
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456
如果要把 MySQL 的指标导入 Grafana,可以参考 这些 Dashboard JSON。
注意事项
这里为简单起见,在 mysqld_exporter 中直接使用了 root 连接数据库,在真实环境中,可以为 mysqld_exporter 创建一个单独的用户,并赋予它受限的权限(PROCESS、REPLICATION CLIENT、SELECT),最好还限制它的最大连接数(MAX_USER_CONNECTIONS)。
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
5.3 收集 Nginx 指标
官方提供了两种收集 Nginx 指标的方式。
第一种是 Nginx metric library,这是一段 Lua 脚本(prometheus.lua),Nginx 需要开启 Lua 支持(libnginx-mod-http-lua 模块)。为方便起见,也可以使用 OpenResty 的 OPM(OpenResty Package Manager) 或者 luarocks(The Lua package manager) 来安装。 第二种是 Nginx VTS exporter,这种方式比第一种要强大的多,安装要更简单,支持的指标也更丰富,它依赖于 nginx-module-vts 模块,vts 模块可以提供大量的 Nginx 指标数据,可以通过 JSON、HTML 等形式查看这些指标。Nginx VTS exporter 就是通过抓取 /status/format/json 接口来将 vts 的数据格式转换为 Prometheus 的格式。
不过,在 nginx-module-vts 最新的版本中增加了一个新接口:/status/format/prometheus,这个接口可以直接返回 Prometheus 的格式,从这点这也能看出 Prometheus 的影响力,估计 Nginx VTS exporter 很快就要退役了(TODO:待验证)。
除此之外,还有很多其他的方式来收集 Nginx 的指标,比如:nginx_exporter 通过抓取 Nginx 自带的统计页面 /nginx_status 可以获取一些比较简单的指标(需要开启 ngx_http_stub_status_module 模块);nginx_request_exporter 通过 syslog 协议 收集并分析 Nginx 的 access log 来统计 HTTP 请求相关的一些指标;nginx-prometheus-shiny-exporter 和 nginx_request_exporter 类似,也是使用 syslog 协议来收集 access log,不过它是使用 Crystal 语言 写的。还有 vovolie/lua-nginx-prometheus 基于 Openresty、Prometheus、Consul、Grafana 实现了针对域名和 Endpoint 级别的流量统计。另外,搜索公众号技术社区后台回复“猴子”,获取一份惊喜礼包。
有需要或感兴趣的同学可以对照说明文档自己安装体验下,这里就不一一尝试了。
5.4 收集 JMX 指标
最后让我们来看下如何收集 Java 应用的指标,Java 应用的指标一般是通过 JMX(Java Management Extensions) 来获取的,顾名思义,JMX 是管理 Java 的一种扩展,它可以方便的管理和监控正在运行的 Java 程序。
JMX Exporter 用于收集 JMX 指标,很多使用 Java 的系统,都可以使用它来收集指标,比如:Kafaka、Cassandra 等。首先我们下载 JMX Exporter:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
JMX Exporter 是一个 Java Agent 程序,在运行 Java 程序时通过 -javaagent 参数来加载:
$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
其中,9404 是 JMX Exporter 暴露指标的端口,config.yml 是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。然后检查下指标数据是否正确获取:
$ curl http://localhost:9404/metrics
六、告警和通知
至此,我们能收集大量的指标数据,也能通过强大而美观的面板展示出来。不过作为一个监控系统,最重要的功能,还是应该能及时发现系统问题,并及时通知给系统负责人,这就是 Alerting(告警)。
Prometheus 的告警功能被分成两部分:一个是告警规则的配置和检测,并将告警发送给 Alertmanager,另一个是 Alertmanager,它负责管理这些告警,去除重复数据,分组,并路由到对应的接收方式,发出报警。常见的接收方式有:Email、PagerDuty、HipChat、Slack、OpsGenie、WebHook 等。
6.1 配置告警规则
我们在上面介绍 Prometheus 的配置文件时了解到,它的默认配置文件 prometheus.yml 有四大块:global、alerting、rule_files、scrape_config,其中 rule_files 块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在 rule_files 块中添加一个告警规则文件:
rule_files: - "alert.rules"
然后参考 官方文档,创建一个告警规则文件 alert.rules:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"这个规则文件里,包含了两条告警规则:InstanceDown 和 APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。
配置好后,需要重启下 Prometheus server,然后访问 http://localhost:9090/rules 可以看到刚刚配置的规则:
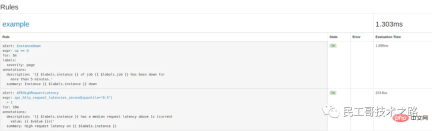
访问 http://localhost:9090/alerts 可以看到根据配置的规则生成的告警:
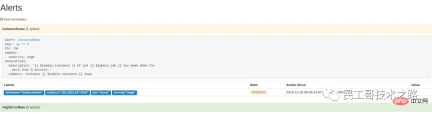
这里我们将一个实例停掉,可以看到有一条 alert 的状态是 PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的 for 参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了 FIRING。
6.2 使用 Alertmanager 发送告警通知
虽然 Prometheus 的 /alerts 页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanager
Alertmanager 启动后默认可以通过 http://localhost:9093/ 来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件 prometheus.yml,添加下面几行:
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "192.168.0.107:9093"这个配置告诉 Prometheus,当发生告警时,将告警信息发送到 Alertmanager,Alertmanager 的地址为 http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:
$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:
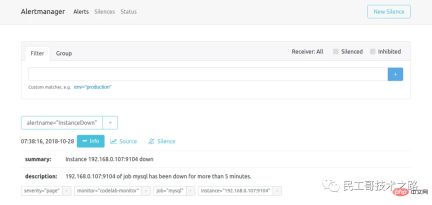
下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,我们打开默认的配置文件 alertmanager.ym:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']其中 global 块表示一些全局配置;route 块表示通知路由,可以根据不同的标签将告警通知发送给不同的 receiver,这里没有配置 routes 项,表示所有的告警都发送给下面定义的 web.hook 这个 receiver;如果要配置多个路由,可以参考 这个例子:
routes:
- receiver: 'database-pager'
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager'
group_by: [product, environment]
match:
team: frontend紧接着,receivers 块表示告警通知的接收方式,每个 receiver 包含一个 name 和一个 xxx_configs,不同的配置代表了不同的接收方式,Alertmanager 内置了下面这些接收方式:
email_config hipchat_config pagerduty_config pushover_config slack_config opsgenie_config victorops_config wechat_configs webhook_config
虽然接收方式很丰富,但是在国内,其中大多数接收方式都很少使用。最常用到的,莫属 email_config 和 webhook_config,另外 wechat_configs 可以支持使用微信来告警,也是相当符合国情的了。
其實告警的通知方式是很難做到面面俱到的,因為訊息軟體各種各樣,每個國家還可能不同,不可能完全覆蓋到,所以Alertmanager 已經決定不再添加新的receiver 了,而是推薦使用webhook 來整合自訂的接收方式。可以參考 這些整合的例子,譬如 將釘子連接到 Prometheus AlertManager WebHook。
七、學習更多
到這裡,我們已經學習了Prometheus 的大多數功能,結合Prometheus Grafana Alertmanager 完全可以建立一套非常完整的監控系統。不過在真正使用時,我們會發現更多的問題。
7.1 服務發現
由於Prometheus 是透過Pull 的方式主動獲取監控數據,所以需要手動指定監控節點的列表,當監控的節點增多之後,每次增加節點都需要更改設定文件,非常麻煩,這個時候就需要透過服務發現(service discovery,SD)機制去解決。
Prometheus 支援多種服務發現機制,可以自動取得要收集的targets,可以參考這裡,包含的服務發現機制包括:azure、consul、dns、ec2、openstack、file、gce、kubernetes、marathon、triton、 zookeeper(nerve、serverset),設定方法可以參考手冊的Configuration 頁面。可以說 SD 機制是非常豐富的,但目前由於開發資源有限,已經不再開發新的 SD 機制,只對基於檔案的 SD 機制進行維護。 關注Linux中文社區
關於服務發現網上有很多教程,譬如Prometheus 官方博客中這篇文章Advanced Service Discovery in Prometheus 0.14.0 對此有一個比較系統的介紹,全面的講解了relabeling 配置,以及如何使用DNS-SRV、Consul 和文件來做服務發現。
另外,官網也提供了 一個基於文件的服務發現的入門例子,Julius Volz 寫的 Prometheus workshop 入門教程中也 使用了 DNS-SRV 來當服務發現。
7.2 告警配置管理
無論是 Prometheus 的配置還是 Alertmanager 的配置,都沒有提供 API 供我們動態的修改。一個很常見的場景是,我們需要基於Prometheus 做一套可自訂規則的告警系統,使用者可根據自己的需求在頁面上建立修改或刪除告警規則,或是修改告警通知方式和聯絡人,正如在Prometheus Google Groups 裡的這個使用者的問題:How to dynamically add alerts rules in rules.conf and prometheus yml file via API or something?
不過遺憾的是,Simon Pasquier 在下面說到,目前並沒有這樣的API,而且以後也沒有這樣的計劃來開發這樣的API,因為這樣的功能更應該交給譬如Puppet、Chef 、Ansible、Salt 這樣的設定管理系統。
7.3 使用 Pushgateway
Pushgateway 主要用於收集一些短期的 jobs,由於這類 jobs 存在時間較短,可能在 Prometheus 來 Pull 之前就消失了。官方對 什麼時候該使用 Pushgateway 有一個很好的說明。
總結
最近兩年 Prometheus 的發展非常迅速,社區也非常活躍,國內研究 Prometheus 的人也越來越多。隨著微服務,DevOps,雲端運算,雲端原生等概念的普及,越來越多的企業開始使用Docker 和Kubernetes 來建立自己的系統和應用,像Nagios 和Cacti 這樣的老牌監控系統會變得越來越不適用,相信Prometheus 最終會發展成一個最適合雲端環境的監控系統。
以上是號稱下一代監控系統!來看看它有多屌的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

禪工作室 13.0.1
強大的PHP整合開發環境

SublimeText3漢化版
中文版,非常好用

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

