
很底層的效能最佳化:讓CPU更快執行你的程式碼
- 嵌入式Linux充电站轉載
- 2023-07-31 15:44:431067瀏覽
Cache對效能的影響
#首先我們要知道,CPU存取記憶體時,不是直接去存取記憶體的,而是先存取快取(cache)。
當快取中已經有了我們要的數據時,CPU就會直接從快取中讀取數據,而不是從記憶體中讀取。
CPU與快取的關係如下:
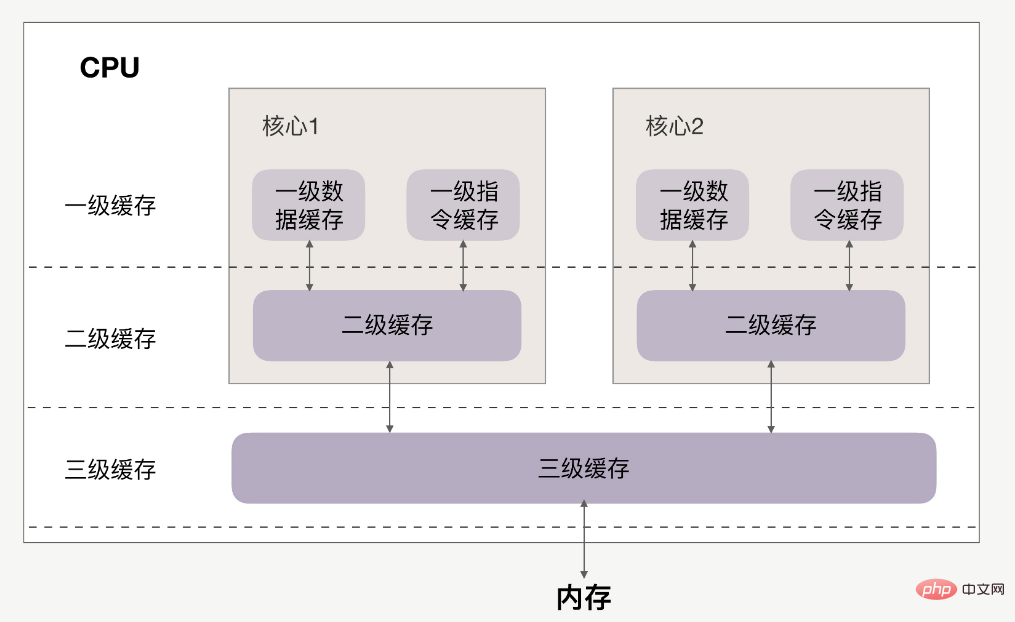
快取分為一級、二級、三級,最靠近CPU的是一級緩存,最遠的是內存,離CPU越近速度越快。
訪問速度上,L1>L2>L3>內存,快取比內存速度要快得非常多。
如果CPU操作的資料在快取中,則直接從快取中讀取,這個過程就叫快取命中。
因此提升效能的關鍵,就是要提高快取命中率。 下面來看如何提高快取命中率。
提高資料快取命中率
#來看一個實例,有一個N*N的二維數組,例如:
int array[N][N];
現在用兩個for循環遍歷這個數組,存取每個元素的內容:
for(i = 0; i < N; i+=1)
{
for(j = 0; j < N; j+=1)
{
array[i][j] = 0;//速度快
//array[j][i] = 0;//速度慢
}
}有两种访问方式:array[i][j]和array[j][i]。
在性能上,array[i][j]会比array[j][i]执行地更快,并且速度相差8倍。
1、速度更快的原因
首先数组在内存上是连续的,假设N等于2,则array[2][2]在内存中的排布是:
array[0][0]、array[0][1]、array[1][0]、array[1][1]、
以array[i][j]方式访问,即按内存中的顺序访问,当访问array[0][0]时,CPU就已经把数组的剩余三个数据(array[0][1]、array[1][0]、array[1][1])加载到了缓存当中。
当继续访问后三个元素时,CPU会直接从缓存中读取数据,而不需要从内存中读取(cache命中)。因此速度会很快。
如果以array[j][i]方式访问数组,则访问顺序为:
array[0][0]、array[1][0]、array[0][1]、array[1][1]
此时访问顺序是跳跃的,并不是按数组在内存中的的排布顺序来访问。如果N很大的话,那么执行array[j][i]时,array[j+1][i]的内容是没法读进缓存里的,等到要访问array[j+1][i]时就只能从内存中读取。
所以array[j][i]的速度会慢于array[i][j]。
2、速度相差8倍的原因
刚刚提到,如果这个二维数组的N很大,array[j+1][i]的内容是没法读到缓存里的,那CPU一次能够将多少数据加载进缓存里呢?
这个其实跟cache line有关,cache line代表缓存一次载入数据的大小。可以通过以下命令查看cache line为多大:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size

cache line为64,代表CPU缓存一次数据的大小为64字节。
當存取array[0][0]時,該元素所佔用的位元組數不到64位元組,CPU就會按順序補足後續元素,就會把後面的array[0][1]、array[1][0]等內容一起讀到快取裡,直到湊夠64位元組。
正因如此,依序存取的array[i][j]才會比不依序存取的array[j][i]速度快。
再看看為什麼速度相差8倍。我們知道,在二維數組中,第一維元素放的是位址,第二維元素才是資料。 64位元系統中,位址佔用8個位元組,cache line為64的話,位址已經佔用了8 字節,那每個cache line最多能載入不到8個二維數組元素,N很大的情況下,他們的效能平均下來就會相差將近8倍。
結論:按記憶體佈局順序訪問,可以提高資料快取命中率。
提高指令緩存命中率
前面說的是資料緩存,現在來看看指令緩存命中率該如何提高。
有一个数组array,数组元素内容为0-255之间的随机数:
int array[N]; for (i = 0; i < TESTN; i++) array[i] = rand() % 256;
现在,要把数组中数字小于128的元素置为0,并且对数组排序。
大家应该都能想到,有两种方法:
先遍历数组,把小于128的元素置为0,然后排序。 先对数组排序,再遍历数组,把小于128的元素置为0。
for(i = 0; i < N; i++) {
if (array [i] < 128)
array[i] = 0;
}
sort(array, array +N);先排序后遍历的速度会比较快,为什么?
因为在for循环中会执行很多次if分支判断语句,而CPU拥有分支预测器。
如果分支预测器可以预测接下来要执行的分支(执行if还是执行else),那么就可以提前把这些指令放到缓存中,CPU执行的时候就会很快了。
如果一个数组的内容完全随机的话,那么分支预测器就很难进行正确的预测。但如果数组内容是有序的,它就会根据历史命中数据的情况对未来进行预测,那命中率就会很高,所以先排序后遍历的速度会比较快。
怎么验证指令缓存命中率的情况呢?
在Linux下,可以使用Perf效能分析工具進行驗證。透過-e選項,指定branch-loads和branch-loads-misses事件,可以分別統計出分支預測成功的次數和分支預測失敗的次數,透過L1-icache-load-misses事件也能統計一級快取中指令未命中的次數。 但是,這些性能事件都屬於硬體事件,perf工具能否統計這些事件取決於CPU是否支援以及晶片原廠是否去實現了該接口,我看很多都是不支持或沒實現的。
另外,在Linux核心中,可以看到大量的likely和unlikely宏,並且它們都出現if語句中,這兩個巨集的作用就是為了提高效能。
這是顯示預測機率的宏,如果你覺得CPU的分支預測不準,但if中條件為"真"的機率很高,那麼你就可以使用likely()括起來,以此提升效能。
#define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0) if (likely(a == 1)) …
提高多核CPU下的缓存命中率
首先要清楚,一级缓存、二级缓存是每颗核心独享的,三级缓存则面向所有核心。
但多核CPU下的系统有个特点,存在CPU核心迁移问题。
例如,進程A在時間片內使用CPU核心1,自然填滿了CPU核心1的一、二級緩存,但基於調度策略,時間片結束後,CPU核心1會被讓出,防止某些進程餓死。如果此時CPU核心1很忙,那麼進程A很可能就會被調度到CPU核心2上運行。這樣的話,無論我們怎麼優化程式碼,也只能在一個時間片內有效率地使用CPU一、二級緩存,下一個時間片就會面臨快取效率問題。
這種情況下,可以考慮將進程綁定CPU運行。
perf工具也提供了這類效能事件的統計,叫做cpu-migrations,即CPU遷移次數。 CPU遷移次數多的話,快取效率就會低。
將進程綁定CPU運行,效能也會提升。
總結
#這些是CPU快取對效能的影響,這已經是很底層的效能優化了,不論什麼程式語言都是有效的。
真正了解緩存,相信你對底層的認識會很有幫助。
提升資料快取命中率:順序操作連續記憶體資料 ##提升指令快取命中率:有規律的條件分支 提升多核心CPU的快取命中率:考慮將行程綁定CPU運作
以上是很底層的效能最佳化:讓CPU更快執行你的程式碼的詳細內容。更多資訊請關注PHP中文網其他相關文章!