
面試必問:從輸入url到頁面展示到底發生了什麼
- Java学习指南轉載
- 2023-07-26 17:01:372358瀏覽
剛開始寫這篇文章還是挺糾結的,因為網上搜尋“從輸入url到頁面展示到底發生了什麼”,你可以搜到一大堆的資料。而且面試這題基本上是必考題,二月面試的時候,雖然知道這個過程發生了什麼,不過當面試官一步步追問下去的,很多細節就不太清楚了。
本文的目的是透過輸入url之後發生的事情來做知識的總結和擴展。所以文章可能會很雜。
總的過程大概如下:
1、輸入位址
當我們開始在瀏覽器中輸入網址的時候,瀏覽器其實就已經在智能的匹配可能得url 了,他會從歷史記錄,書籤等地方,找到已經輸入的字符串可能對應的url,然後給出智能提示,讓你可以補全url地址。對於 google的chrome 的瀏覽器,他甚至會直接從快取中把網頁展示出來,就是說,你還沒按下 enter,頁面就出來了。
2、瀏覽器查找域名的IP 位址
1、請求一旦發起,瀏覽器首先要做的事情就是解析這個域名,一般來說,瀏覽器會先查看本地硬碟的hosts 文件,看看其中有沒有和這個網域對應的規則,如果有的話就直接使用hosts 文件裡面的ip 位址。
2、如果在本地的 hosts 檔案沒有能夠找到對應的 ip 位址,瀏覽器會發出一個 DNS請求到本地DNS伺服器 。本地DNS伺服器一般都是你的網路存取伺服器商提供,例如中國電信,中國移動。
3、查詢你輸入的網址的DNS請求到達本地DNS伺服器之後,本地DNS伺服器會先查詢它的快取記錄,如果快取中有此筆記錄,就可以直接傳回結果,此過程是遞歸的方式進行查詢。如果沒有,本機DNS伺服器也要向DNS根伺服器進行查詢。
4、根DNS伺服器沒有記錄特定的網域名稱和IP位址的對應關係,而是告訴本地DNS伺服器,你可以到網域伺服器上去繼續查詢,並給予網域伺服器的地址。這種過程是迭代的過程。
5、本地DNS伺服器繼續向網域伺服器發出請求,在這個範例中,請求的物件是.com網域伺服器。 .com網域伺服器收到請求之後,也不會直接回傳網域名稱和IP位址的對應關係,而是告訴本地DNS伺服器,你的網域的解析伺服器的位址。
6、最後,本地DNS伺服器向網域名稱的解析伺服器發出請求,這時就能收到一個網域名稱和IP位址對應關係,本地DNS伺服器不只要把IP位址回傳給用戶電腦,還要把這個對應關係保存在快取中,以便下次別的使用者查詢時,可以直接回傳結果,加快網路存取。
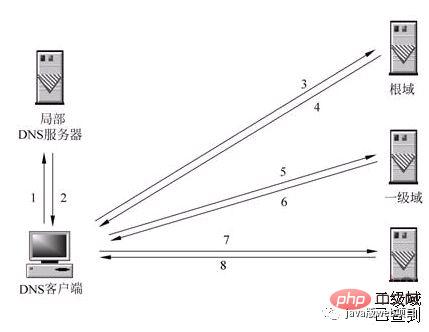
下面這張圖很完美的解釋了這個過程:

知識擴充:
1)什麼是DNS?
DNS(Domain Name System,網域名稱系統),因特網路上作為網域名稱和IP位址相互映射的一個分散式資料庫,能夠使用戶更方便的存取互聯網,而不用去記住能夠被機器直接讀取的IP數串。透過主機名,最後得到該主機名對應的IP位址的過程叫做網域解析(或稱主機名解析)。
通俗的講,我們更習慣於記住一個網站的名字,例如www.baidu.com,而不是記住它的ip位址,例如:167.23.10.2。而電腦更擅長記住網站的ip位址,而不是像www.baidu.com等連結。因為,DNS就相當於一個電話本,例如你要找www.baidu.com這個域名,那我翻一翻我的電話本,我就知道,哦,它的電話(ip)是167.23.10.2。
2)DNS查詢的兩種方式:遞迴查詢與迭代查詢
1、遞迴解析
當局部DNS伺服器本身無法回答客戶機的DNS查詢時,它就需要向其他DNS伺服器進行查詢。此時有兩種方式,如圖所示的是遞歸方式。局部DNS伺服器自己負責向其他DNS伺服器查詢,一般是先向該網域的根網域伺服器查詢,再由根網域伺服器一級向下查詢。最後得到的查詢結果回傳給局部DNS伺服器,再由局部DNS伺服器傳回給客戶端。

2、迭代解析
當局部DNS伺服器本身無法回答客戶機的DNS查詢時,也可以透過迭代查詢的方式解析,如圖所示。局部DNS伺服器不是自己向其他DNS伺服器進行查詢,而是把能解析該網域的其他DNS伺服器的IP位址傳回給客戶端DNS程序,客戶端DNS程序再繼續向這些DNS伺服器進行查詢,直到得到查詢結果為止。也就是說,迭代解析只是幫你找相關的伺服器而已,而不會幫你查。比如說:baidu.com的伺服器ip位址在192.168.4.5這裡,你自己去查吧,本人比較忙,只能幫你到這裡了。
3)DNS領域名稱空間的組織方式
我們在前面有說到根DNS伺服器,域DNS伺服器,這些都是DNS域名稱空間的組織方式。依其功能命名空間中用來描述DNS 域名稱的五個類別的介紹詳見下表中,以及與每個名稱類型的範例
 (盜圖)
(盜圖)
4)DNS負載平衡
當一個網站有足夠多的用戶的時候,假如每次請求的資源都位於同一台機器上面,那麼這台機器隨時可能會彈跳。處理辦法就是用DNS負載平衡技術,它的原理是在DNS伺服器中為同一個主機名稱配置多個IP位址,在應答DNS查詢時,DNS伺服器對每個查詢將以DNS檔案中主機記錄的IP位址依序返回不同的解析結果,將客戶端的存取引導到不同的機器上去,使得不同的客戶端訪問不同的伺服器,從而達到負載平衡的目的。例如可以根據每台機器的負載量,該機器離用戶地理位置的距離等等。
3、瀏覽器向web 伺服器發送一個HTTP 請求
拿到網域對應的IP位址之後,瀏覽器會以一個隨機連接埠(102438140922b2a263c5e7cb6ee274ae2ffa 建立render樹-> 佈局render樹-> 繪製render樹
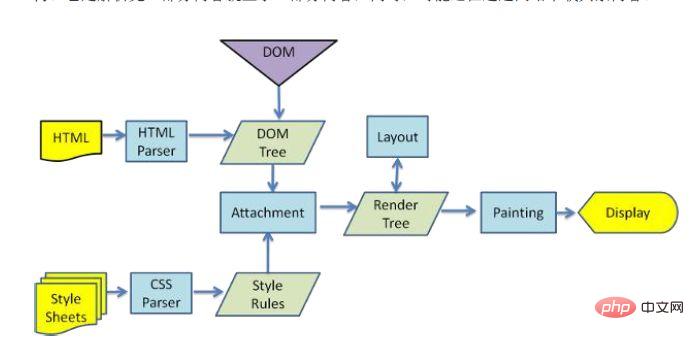
瀏覽器在解析html檔案時,會」自上而下「加載,並在加載過程中進行解析渲染。在解析過程中,如果遇到請求外部資源時,例如圖片、外鏈的CSS、iconfont等,請求過程是非同步的,並不會影響html文檔進行載入。
解析過程中,瀏覽器首先會解析HTML檔案建構DOM樹,然後解析CSS檔案建構渲染樹,等到渲染樹建置完成後,瀏覽器開始佈局渲染樹並將其繪製到螢幕上。這個過程比較複雜,涉及到兩個概念: reflow(回流)和repain(重繪)。
DOM節點中的各個元素都是以盒模型的形式存在,這些都需要瀏覽器去計算其位置和大小等,這個過程稱為relow;當盒模型的位置,大小以及其他屬性,如顏色,字體,等確定下來之後,瀏覽器便開始繪製內容,這個過程稱為repain。
頁面在首次載入時必然會經歷reflow和repain。 reflow和repain過程是非常消耗效能的,尤其是在行動裝置上,它會破壞使用者體驗,有時會造成頁面卡頓。所以我們應該盡可能少的減少reflow和repain。
# 當文件載入過程中遇到js文件,html文檔會掛起渲染(載入解析渲染同步)的線程,不僅要等待文檔中js檔案載入完畢,還要等待解析執行完畢,才可以恢復html文檔的渲染線程。因為JS有可能會修改DOM,最經典的document.write,這意味著,在JS執行完成前,後續所有資源的下載可能是沒有必要的,這是js阻塞後續資源下載的根本原因。所以我明平常的程式碼中,js是放在html文檔最後的。
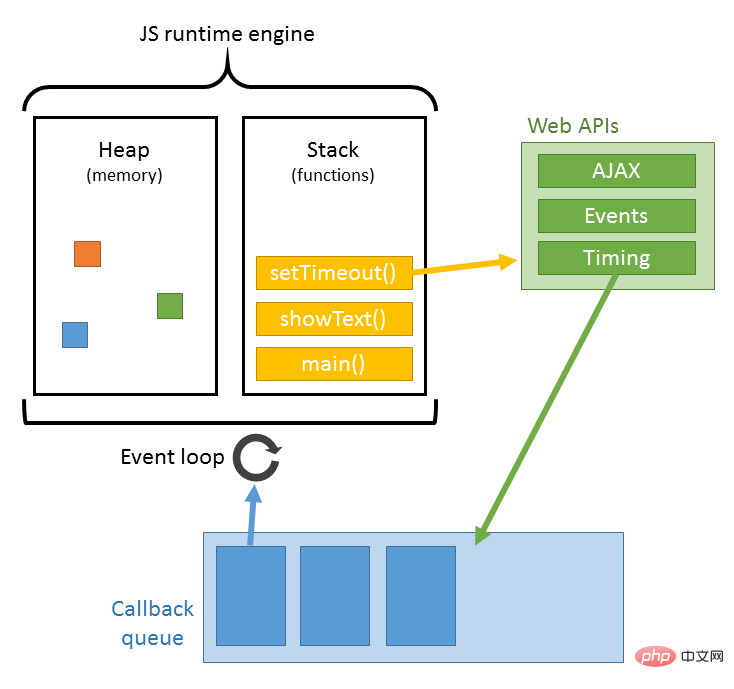
JS的解析是由瀏覽器中的JS解析引擎完成的,例如Google的是V8。 JS是單執行緒運行,也就是說,在同一時間只能做一件事,所有的任務都需要排隊,前一個任務結束,後一個任務才能開始。但是又存在某些任務比較耗時,如IO讀寫等,所以需要一種機制可以先執行排在後面的任務,這就是:同步任務(synchronous)和異步任務(asynchronous)。
JS的執行機制就可以看做是一個主執行緒加上一個任務佇列(task queue)。同步任務就是放在主執行緒上執行的任務,非同步任務是放在任務佇列中的任務。所有的同步任務在主執行緒上執行,形成一個執行棧;非同步任務有了運行結果就會在任務隊列中放置一個事件;腳本運行時先依次運行執行棧,然後會從任務隊列中提取事件,運行任務佇列中的任務,這個過程是不斷重複的,所以又叫做事件迴圈(Event loop)。具體的過程可以看我這篇文章:點這裡
9、瀏覽器發送請求獲取嵌入在HTML 中的資源(如圖片、音訊、視訊、CSS、JS等等)
其實這個步驟可以並列在步驟8中,在瀏覽器顯示HTML時,它會注意到需要取得其他位址內容的標籤。這時,瀏覽器會發送一個獲取請求來重新獲得這些文件。例如我要取得外圖片,CSS,JS檔案等,類似下面的連結:
圖片:http://static.ak.fbcdn.net/rsrc.php/z12E0 /hash/8q2anwu7.gif
CSS樣式表:http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
JavaScript 檔案:http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
這些位址都要經歷一個和HTML讀取類似的過程。所以瀏覽器會在DNS中尋找這些域名,發送請求,重定向等等...
不像動態頁面,靜態檔案會允許瀏覽器對其進行快取。有的檔案可能不需要與伺服器通訊,而從快取直接讀取,或是可以放到CDN中
至此,從輸入url到頁面展示的過程終於整理完了。當然,文筆有限,有誤之處,歡迎指出,本文參考了很多的文章,不過很多文章的連結不記得了,所以只列出了下面三個參考連結。
以上是面試必問:從輸入url到頁面展示到底發生了什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!