
你用對鎖了嗎?淺談 Java '鎖” 事
- Java学习指南轉載
- 2023-07-26 16:27:151090瀏覽
每個時代,都不會虧待學習的人
#最近在公司發現新同事對於鎖這方面有一些誤解,所以今天就來談談「鎖」事和Java 中的並發安全容器使用有哪些注意點。
不過在這之前還是得先來盤一盤為什麼需要鎖這玩意,這得從並發 BUG 的源頭說起。
並發BUG 的源頭
這個問題我19 年的時候寫過一篇文章, 現在回頭看那篇文章真的是羞澀啊。

讓我們來看下這個源頭是什麼,我們知道電腦有CPU、記憶體、硬碟,硬碟的讀取速度最慢,其次是記憶體的讀取,記憶體的讀取相對於CPU 的運行又太慢了,因此又搞了個CPU緩存,L1、L2、L3。
正是這個CPU快取再加上現在多核心CPU的情況產生了並發BUG。

這就一個很簡單的程式碼,如果此時有執行緒A 和執行緒B 分別在CPU - A 和CPU - B 中執行這個方法,它們的操作是先將a 從主存取到CPU 各自的快取中,此時它們快取中a 的值都是0。
然後它們分別執行a ,此時它們各自眼中a 的值都是1,之後把a 刷到主存的時候a 的值還是1,這就出現問題了,明明執行了兩次加一最終的結果卻是1,而不是2。
這個問題就叫做可見性問題。
在看我們a 這條語句,我們現在的語言都是高級語言,這其實和語法糖很類似,用起來好像很方便實際上那隻是表面,真正需要執行的指令一條都少不了。
高階語言的一條語句翻譯成 CPU 指令的時候可不只一條, 就例如 a 轉換成 CPU 指令至少就有三條。
把a 從記憶體拿到暫存器中;
#在暫存器中1;
#將結果寫入快取或記憶體中;
#所以我們以為a 這條語句是不可能中斷的是具備原子性的,而實際上CPU 可以能執行一條指令時間片就到了,此時上下文切換到另一個線程,它也執行a 。再切回來的時候 a 的值其實已經不對了。
這個問題叫做原子性問題。
並且編譯器或解釋器為了優化效能,可能會改變語句的執行順序,這叫指令重排,最經典的例子莫過於單例模式的雙重檢查了。而 CPU 為了提高執行效率,也會亂序執行,例如 CPU 在等待記憶體資料載入的時候發現後面的加法指令不依賴前面指令的計算結果,因此它就先執行了這條加法指令。
這個問題就叫有序性問題。
至此已經分析完了並發 BUG 的源頭,也就是這三大問題。可以看到不管是 CPU 快取、多核心 CPU 、高階語言還是亂序重排其實都是必要的存在,所以我們只能直面這些問題。
而解決這些問題就是透過停用快取、禁止編譯器指令重排、互斥等手段,今天我們的主題和互斥相關。
互斥就是保證共享變數的修改是互斥的,也就是同一時刻只有一個執行緒在執行。而說到互斥相信大家腦海中浮現的就是鎖定。沒錯,我們今天的主題就是鎖!鎖就是為了解決原子性問題。
鎖定
說到鎖定可能 Java 的同學第一反應就是 synchronized 關鍵字,畢竟是語言層面支援的。我們就先來看看 synchronized,有些同學對 synchronized 理解不到位所以用起來會有很多坑。
synchronized 注意點
我們先來看一份程式碼,這段程式碼就是咱們的加薪之路,最終百萬是灑灑水的。而一個線程時刻的對比著我們薪水是不是相等的。我簡單說一下IntStream.rangeClosed(1,1000000).forEach#,可能有些人對這個不太熟悉,這個程式碼的就等於 for 迴圈了100W次。
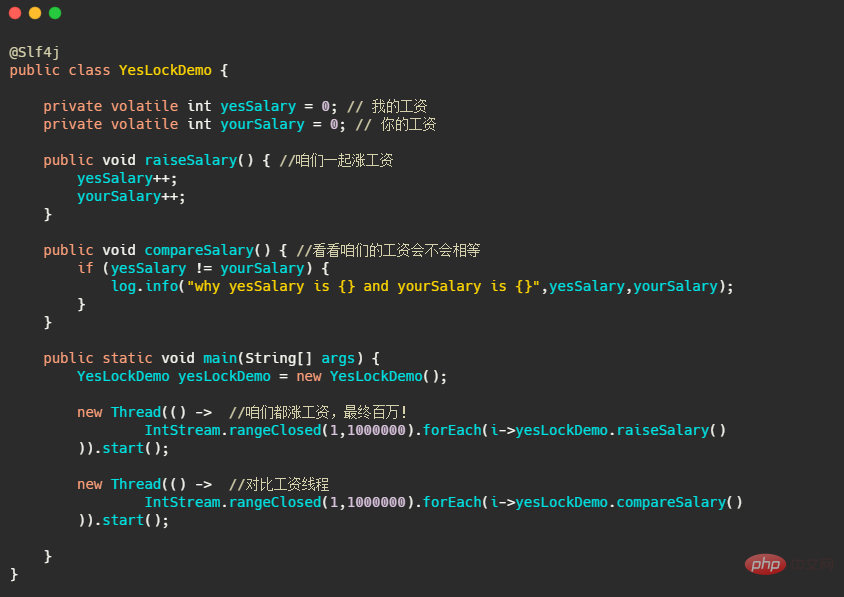
你先自己理解下,看看你覺得有沒有什麼問題?第一反應好像沒問題,你看著加薪就一個線程執行著,這比工資也沒有修改值,看起來好像沒啥毛病?沒有啥並發資源的競爭,也用 volatile 修飾了保證了可見性。
讓我們來看結果,我截取了一部分。
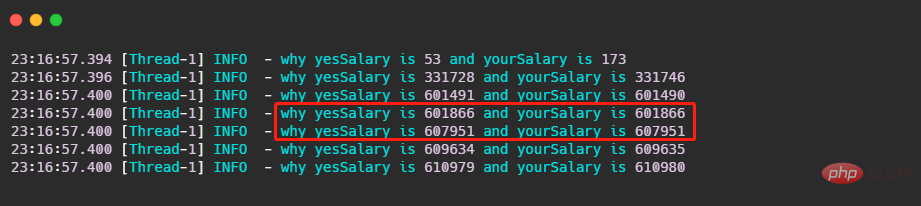
可以看到先有 log 打出來就已經不對了,再打出來的值竟然還相等!有沒有出乎你的意料之外?有同學可能下意識就想到這就raiseSalary在修改,所以肯定是線程安全問題來給raiseSalary 加個鎖!
請注意只有一個執行緒在呼叫raiseSalary方法,所以單給raiseSalary方法加鎖並沒啥用。
這其實就是我上面提到的原子性問題,想像漲工資線程在執行完yesSalary 還未執行yourSalary 時,比工資線程剛好執行到yesSalary != yourSalary 是不是肯定是true ?所以才會印出 log。
再者由於用volatile 修飾保證了可見性,所以當打log 的時候,可能yourSalary 已經執行完了,這時候打出來的log 才會是yesSalary = = yourSalary。
所以最簡單的解決方法就是把raiseSalary() 和compareSalary() 都用synchronized 修飾,這樣加薪和比工資兩個執行緒就不會在同一時刻執行,因此肯定就安全了!
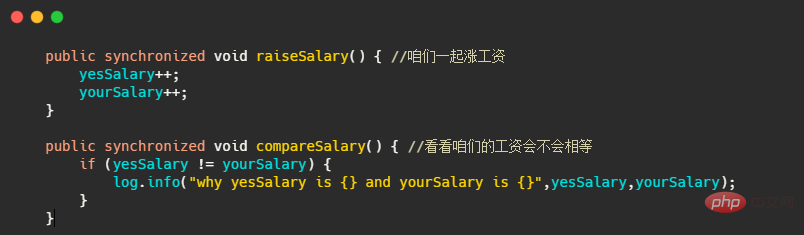
看起來鎖好像也挺簡單,不過這個 synchronized 的使用還是對於新手來說還是有坑的,就是你要關注 synchronized 鎖的究竟是什麼。
例如我改成多執行緒來加薪。這裡再提一下parallel,這個其實就是利用了 ForkJoinPool 執行緒池操作,預設執行緒數是 CPU 核心數。
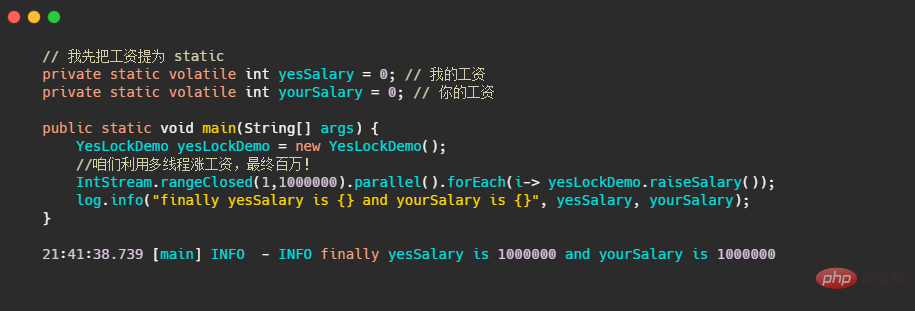
由於 raiseSalary() 加了鎖,所以最終的結果是對的。這是因為 synchronized 修飾的是yesLockDemo實例,我們的 main 中只有一個實例,所以等於多執行緒競爭的是一把鎖,所以最後計算出來的資料正確。
那我再修改下程式碼,讓每個執行緒自己有一個 yesLockDemo 實例來加薪。
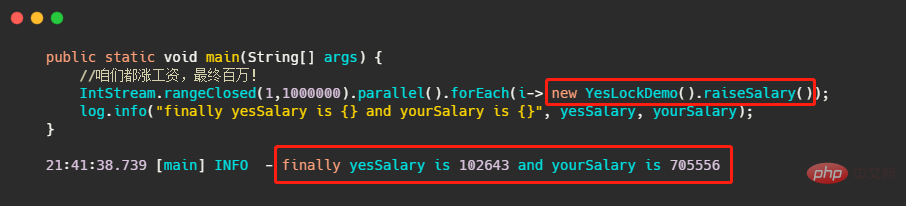
你會發現這鎖怎麼沒用了?這說好的百萬年薪我就變 10w 了? ?這你還好還有 70w。
這是因為此時我們的鎖定修飾的是非靜態方法,是實例層級的鎖定,而我們為每個執行緒都建立了一個實例,因此這幾個執行緒競爭的就根本不是一把鎖,而上面多執行緒計算正確程式碼是因為每個執行緒用的都是同一個實例,所以競爭的是一把鎖。如果想要此時的程式碼正確,只需要把實例層級的鎖定變成類別層級的鎖定。
很簡單只要把這個方法變成靜態方法,synchronized 修飾靜態方法就是類別層級的鎖定。

還有一種就是宣告一個靜態變量,比較推薦這種,因為把非靜態方法變成靜態方法其實就等於改了程式碼結構了。

我們來小結一下,使用synchronized 的時候需要注意鎖的到底是什麼,如果修飾靜態欄位和靜態方法那就是類別層級的鎖,如果修飾非靜態欄位和非靜態方法就是實例層級的鎖定。
鎖定的粒度
相信大家知道Hashtable 不被推薦使用,要用就用ConcurrentHashMap,是因為Hashtable 雖然是線程安全的,但它太粗暴了,它為所有的方法都上了同一把鎖!我們來看下源碼。
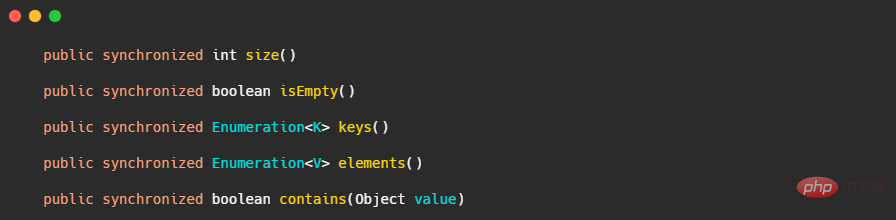
你說這 contains 和 size 方法有啥關係?我在呼叫 contains 的時候憑啥不讓我調 size ? 這就是鎖的粒度太粗了我們得評估一下,不同的方法用不同的鎖,這樣才能在線程安全的情況下再提高並發度。
但是不同方法不同鎖還不夠的,因為有時候一個方法裡面有些操作其實是線程安全的,只有涉及競爭競態資源的那一段程式碼才需要加鎖。特別是不需要鎖的程式碼很耗時的情況,就會長時間佔這把鎖,而且其他執行緒只能排隊等著,例如下面這段程式碼。

很明顯第二段程式碼才是正常的使用鎖的姿勢,不過在平時的業務程式碼中可不是像我程式碼裡貼的sleep 這麼容易一眼就看出的,有時候還需要修改程式碼執行的順序等等來確保鎖的粒度夠細。
而有時候又需要保證鎖足夠的粗,不過這部分JVM會偵測到,它會幫我們做最佳化,例如下面的程式碼。

可以看到明明是方法裡面呼叫的邏輯卻經歷了加上鎖定-執行A-解鎖-加鎖-執行B-解鎖# ,很明顯的可以看出其實只需要經歷加鎖-執行A-執行B-解鎖。
所以 JVM 會在即時編譯的時候做鎖的粗化,將鎖的範圍擴大,類似變成下面的情況。

而且JVM 還會有鎖定消除的動作,透過逃逸分析判斷實例物件是線程私有的,那麼肯定是線程安全的,於是就會忽略物件裡面的加鎖動作,直接呼叫。
讀寫鎖定
讀寫鎖定就是我們上面提交的根據場景減少鎖定的粒度了,把一個鎖拆成了讀鎖和寫鎖,特別適合在讀多寫少的情況下使用,例如自己實現的一個快取。
ReentrantReadWriteLock
讀寫鎖定允許多個執行緒同時讀取共享變數,但是寫入操作是互斥的,即寫寫互斥、讀寫互斥。講白了就是寫的時候就只能一個線程寫,其他線程也讀不了也寫不了。
我們來看個小例子,裡面也有個小細節。這段程式碼就是模擬快取的讀取,先上讀鎖去快取拿數據,如果快取沒數據則釋放讀鎖,再上寫鎖去資料庫取數據,然後塞入快取中返回。
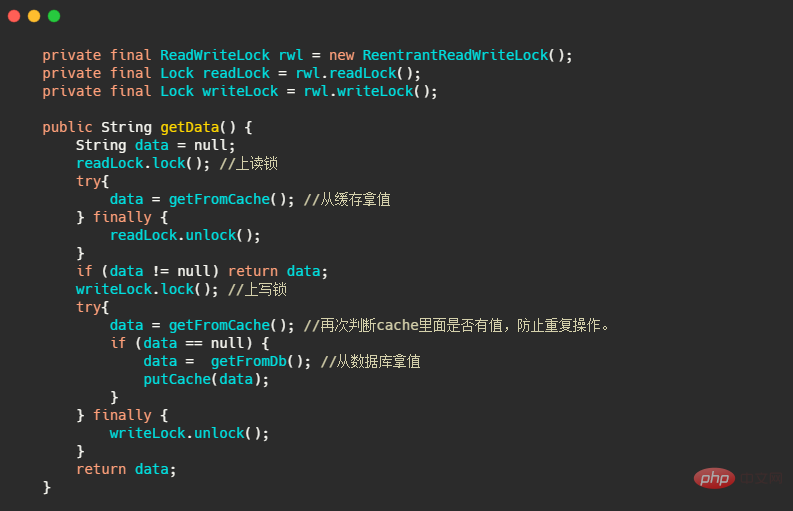
這裡面的小細節就是再次判斷data = getFromCache() 是否有值,因為同一時刻可能會有多個執行緒呼叫getData(),然後快取都會為空因此都去競爭寫鎖,最後只有一個執行緒會先拿到寫鎖,然後將資料又塞入快取中。
此時等待的執行緒最終一個個的都會拿到寫鎖,取得寫鎖的時候其實快取裡面已經有值了所以沒必要再去資料庫查詢。
當然 Lock 的使用範式大家都知道,需要用 try- finally,來保證一定會解鎖。而讀寫鎖還有一個重點要注意,也就是說鎖定不能升級。什麼意思呢?我改一下上面的程式碼。
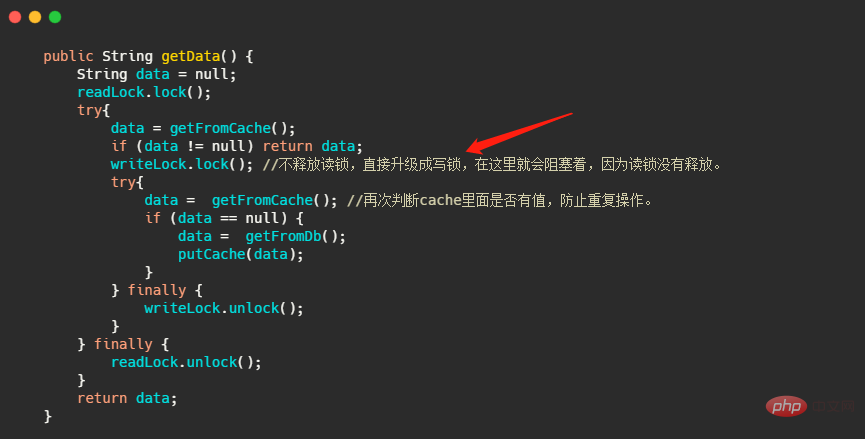
但是寫鎖定內可以再用讀取鎖,來實現鎖定的降級,有些人可能會問了這寫鎖定都加了還要什麼讀鎖。
還是有點用處的,例如某個線程搶到了寫鎖,在寫的動作要完畢的時候加上讀鎖,接著釋放了寫鎖,此時它還持有讀鎖可以保證能馬上使用寫鎖操作完的數據,而別的線程也因為此時寫鎖已經沒了也能讀數據。
其實就是目前已經不需要寫鎖這種比較霸道的鎖!所以來降個級讓大家都能讀。
小結一下,讀寫鎖定適用於讀多寫少的情況,無法升級,但是可以降級。 Lock 的鎖需要搭配 try- finally,來保證一定會解鎖。
對了,我再稍稍提一下讀寫鎖的實作,熟悉AQS 的同學可能都知道裡面的state ,讀寫鎖就是把這個int 型別的state 分成了兩半,高16 位元與低16 位元分別記錄讀鎖和寫鎖的狀態。 它和普通的互斥鎖的差別在於要維護這兩個狀態和在等待佇列處區別處理這兩種鎖。
所以在不適用於讀取和寫入鎖定的場景還不如直接用互斥鎖定,因為讀寫鎖定還需要對state進行位移判斷等等。
StampedLock
#這玩意我也稍微提一下,是1.8 提出來的出鏡率似乎沒有ReentrantReadWriteLock 高。它支援寫鎖、悲觀讀鎖和樂觀讀。寫鎖和悲觀讀鎖其實和 ReentrantReadWriteLock 裡面的讀寫鎖是一致的,它就多了個樂觀讀。
從上面的分析我們知道讀寫鎖在讀的時候其實是無法寫的,而 StampedLock 的樂觀讀則允許一個線程寫。樂觀讀其實就是跟我們所知道的資料庫樂觀鎖一樣,資料庫的樂觀鎖例如透過version欄位來判斷,例如下面這條 sql。
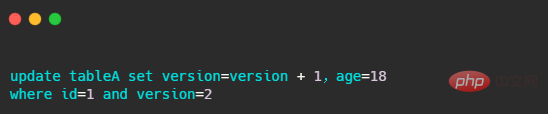
StampedLock 樂觀讀就是與其類似,我們來看看簡單的用法。

它與 ReentrantReadWriteLock 比較也就強在這裡,其他的不行,例如 StampedLock 不支援重入,不支援條件變數。 還有一點使用 StampedLock 一定不要呼叫中斷操作,因為會導致CPU 100%,我跑了一下並發程式網上面提供的例子,復現了。
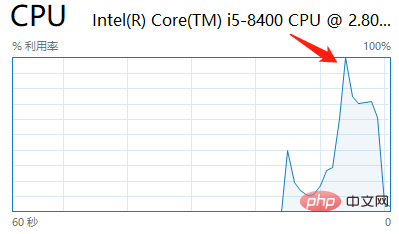
具體的原因這裡不再贅述,文末會貼上鏈接,上面說的很詳細了。
所以出來一個看似好像很厲害的東西,你需要真正的去理解它,熟悉它才能做到有的放矢。
CopyOnWrite
寫時複製的在很多地方也會用到,例如進程 fork() 操作。對於我們業務程式碼層面而言也是很有幫助的,在於它的讀取操作不會阻塞寫,寫入操作也不會阻塞讀取。適用於讀多寫少的場景。
例如 Java 中的實作 CopyOnWriteArrayList,有人可能一聽,這玩意線程安全讀的時候還不會阻塞寫,好傢伙就用它了!
你得先搞清楚,寫時複製是會拷貝一份資料,你的任何一個修改動作在CopyOnWriteArrayList 中都會觸發一次Arrays .copyOf,然後在副本上修改。如果修改的動作很多,而且拷貝的資料也很大,這將是災難!
並發安全容器
最後再來談談並發安全容器的使用,我就拿相對而言大家比較熟悉的 ConcurrentHashMap 來作為例子。我看新來的同事好像認為只要是使用並發安全容器一定就是線程安全了。其實不盡然,還得看怎麼用。
我們先來看以下的程式碼,簡單的說就是利用 ConcurrentHashMap 來記錄每個人的薪資,最多就記錄 100 個。
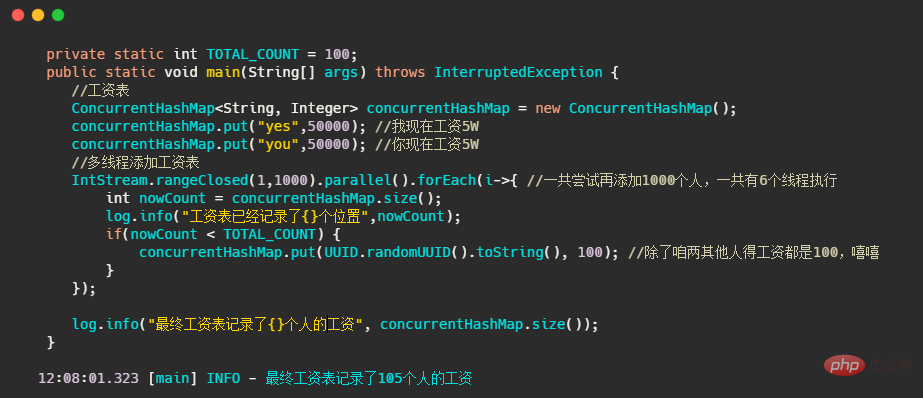
最終的結果都會超標,也就是 map 裡面不只記錄了100個人。那怎麼樣結果才會是對的?很簡單就是加個鎖。
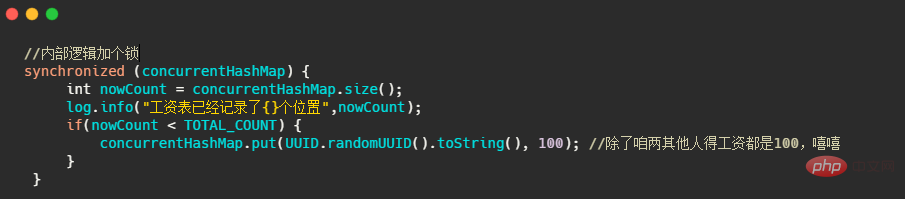
看到這有人說,你這都加鎖了我還用啥 ConcurrentHashMap ,我 HashMap 加個鎖也能完事!是的你說的沒錯!因為目前我們的使用場景是複合型操作,也就是我們先拿map 的size 做了判斷,然後再執行了put 方法,ConcurrentHashMap 無法保證複合型的運算是執行緒安全的!
而ConcurrentHashMap 合適只是用其暴露出來的線程安全的方法,而不是複合操作的情況下。例如以下程式碼

當然,我這個範例不夠恰當其實,因為ConcurrentHashMap 效能比HashMap 鎖高的原因在於分段鎖,需要多個key 運算才能體現出來,不過我想突出的重點是使用的時候不能大意,不能純粹的認為用了就線程安全了。
總結一下
今天談了談並發BUG 的源頭,即三大問題:可見性問題、原子性問題和有序性問題。然後簡單的說了下 synchronized 關鍵字的注意點,即修飾靜態字段或靜態方法是類別層面的鎖,而修飾非靜態字段和非靜態方法是實例層面的類別。
再說了下鎖的粒度,在不同場景定義不同的鎖不能粗暴的一把鎖搞定,並且方法內部鎖的粒度要細。例如在讀多寫少的場景可以使用讀寫鎖、寫時複製等。
最終要正確的使用並發安全容器,不能一味的認為使用並發安全容器就一定線程安全了,要注意複合操作的場景。

當然我今天只是淺淺的談了一下,關於並發程式設計其實還有很多點,要寫出線程安全的程式碼不是一件容易的事情,就像我之前分析的Kafka 事件處理全流程一樣,原先的版本就是各種鎖控制並發安全,到後來bug根本修不動,多執行緒程式設計難,調試也難,修bug也難。
因此Kafka 事件處理模組最終改成了單執行緒事件佇列模式,將涉及到共享資料競爭相關方面的存取抽象化成事件,將事件塞入阻塞佇列中,然後單線程處理。
所以在用鎖之前我們要先想想,有必要嘛?能簡化麼?不然之後維護起來有多痛苦到時候你就知道了。
以上是你用對鎖了嗎?淺談 Java '鎖” 事的詳細內容。更多資訊請關注PHP中文網其他相關文章!