
大模型訓練成本降低近一半!新加坡國立大學最新優化器已投入使用

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-07-17 22:13:171424瀏覽
優化器在大語言模型的訓練中佔據了大量記憶體資源。
現在有一種新的最佳化方式,在效能保持不變的情況下將記憶體消耗降低了一半。
此成果由新加坡國立大學打造,在ACL會議上獲得了傑出論文獎,並已經投入了實際應用。
 圖片
圖片
隨著大語言模型不斷增加的參數量,訓練時的記憶體消耗問題更為嚴峻。
研究團隊提出了 CAME 優化器,在減少記憶體消耗的同時,擁有與Adam相同的效能。
 圖片
圖片
CAME優化器在多個常用的大規模語言模型的預訓練上取得了相同甚至超越Adam優化器的訓練表現,並對大batch預訓練場景顯示出更強的穩健性。
進一步地,透過CAME優化器訓練大語言模型,能夠大幅降低大模型訓練的成本。
實作方法
CAME 最佳化器是基於 Adafactor 最佳化器改進而來,後者在大規模語言模型的預訓練任務中往往帶來訓練效能的損失。
Adafactor中的非負矩陣分解操作在深度神經網路的訓練中不可避免地會產生錯誤,對這些錯誤的修正就是效能損失的來源。
而透過比較發現,當起始數值mt和目前數值t相差較小時,mt的置信度更高。
 圖片
圖片
受這一點啟發,團隊提出了一種新的最佳化演算法。
下圖的藍色部分就是CAME比較像Adafactor增加的部分。
 圖片
圖片
CAME 最佳化器基於模型更新的置信度進行更新量修正,同時對引入的置信度矩陣進行非負矩陣分解運算。
最終,CAME成功以Adafactor的消耗得到了Adam的效果。
相同效果只消耗一半資源
團隊使用CAME分別訓練了BERT、GPT-2和T5模型。
先前常用的Adam(效果較優)和Adafactor(消耗更低)是衡量CAME表現的參考。
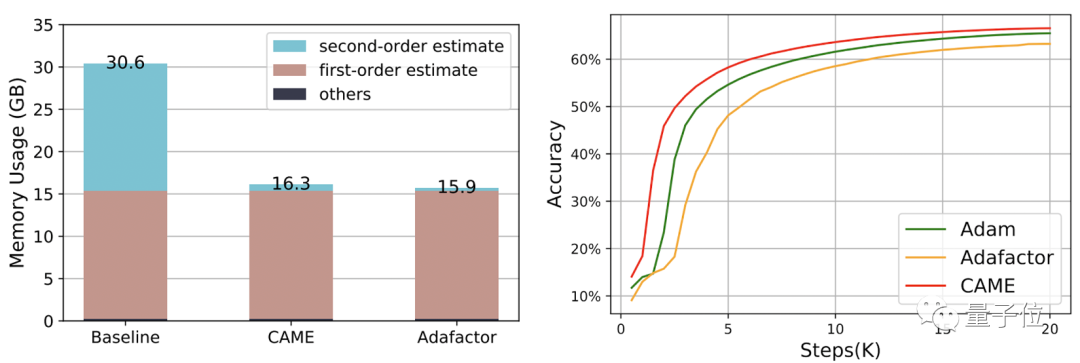
其中,在訓練BERT的過程中,CAME只用一半的步數就達到了和Adafaactor相當的精確度。
 △左側為8K規模,右側為32K規模
△左側為8K規模,右側為32K規模
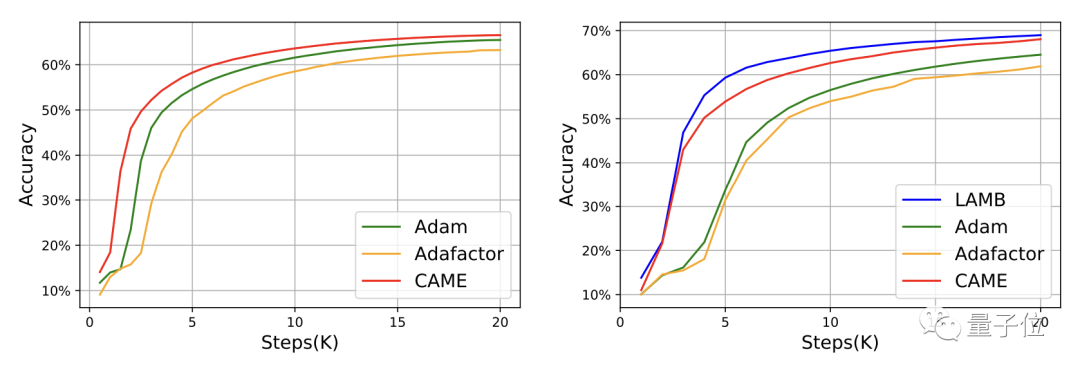
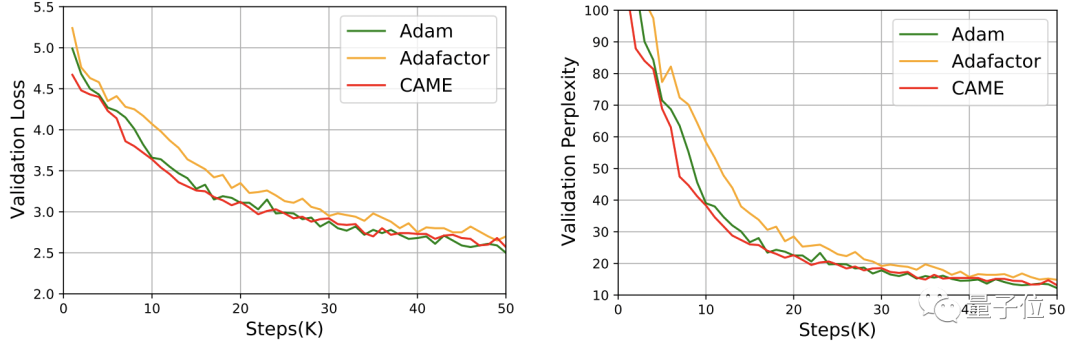
對於GPT-2,從損失和困惑度兩個角度看,CAME的表現和Adam十分接近。

在T5模型的訓練中,CAME也呈現了類似的結果。
而對於模型的微調,CAME在精確度上的表現也不輸於基準。
資源消耗方面,在使用PyTorch訓練4B資料量的BERT時,CAME消耗的記憶體資源比基準減少了近一半。
團隊簡介
新加坡國立大學HPC-AI 實驗室是尤洋教授領導的高效能運算與人工智慧實驗室。
實驗室致力於高效能運算、機器學習系統和分散式平行運算的研究和創新,並推動在大規模語言模型等領域的應用。
實驗室負責人尤洋是新加坡國立大學電腦系的校長青年教授(Presidential Young Professor)。
尤洋在2021年被選入福布斯30歲以下精英榜(亞洲)並獲得IEEE-CS超算傑出新人獎,目前的研究重點是大規模深度學習訓練演算法的分散式最佳化。
本文第一作者羅暘是該實驗室的在讀碩士生,他目前研究重點為大模型訓練的穩定性以及高效訓練。
論文網址:https://arxiv.org/abs/2307.02047
GitHub專案頁:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
#以上是大模型訓練成本降低近一半!新加坡國立大學最新優化器已投入使用的詳細內容。更多資訊請關注PHP中文網其他相關文章!