
一句話搞定數據分析,浙大全新大模型數據助手,連蒐集都省了

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-07-13 22:01:051307瀏覽
處理數據,用這一個AI工具就夠了!
依賴背後的大語言模型(LLM),只需要用一句話描述自己想看的數據,其他統統交給它!
處理、分析,甚至視覺化,都能輕鬆搞定,連蒐集也不用自己動手。
 圖片
圖片
這款基於LLM的AI資料助理叫做Data-Copilot,由浙江大學團隊研發。
相關論文預印本已經發布。
以下內容由投稿者提供
金融、氣象、能源等各行各業每天都會產生大量的異質資料。人們急切需要一個工具來有效地管理、處理和展示這些數據。
DataCopilot透過部署大語言模型來自主地管理和處理大量數據,滿足多樣化的使用者查詢、計算、預測、視覺化等需求。
只需要輸入文字告訴DataCopilot你想看的數據,無需繁瑣的操作,無需自己編寫程式碼,DataCopilot自主地將原始資料轉換為最符合使用者意圖的視覺化結果。
為了實現的囊括各種形式的資料相關任務的通用框架,研究團隊提出了Data-Copilot。
這個模型解決了單純使用LLM存在的資料外洩風險、運算能力差、無法處理複雜任務等問題。
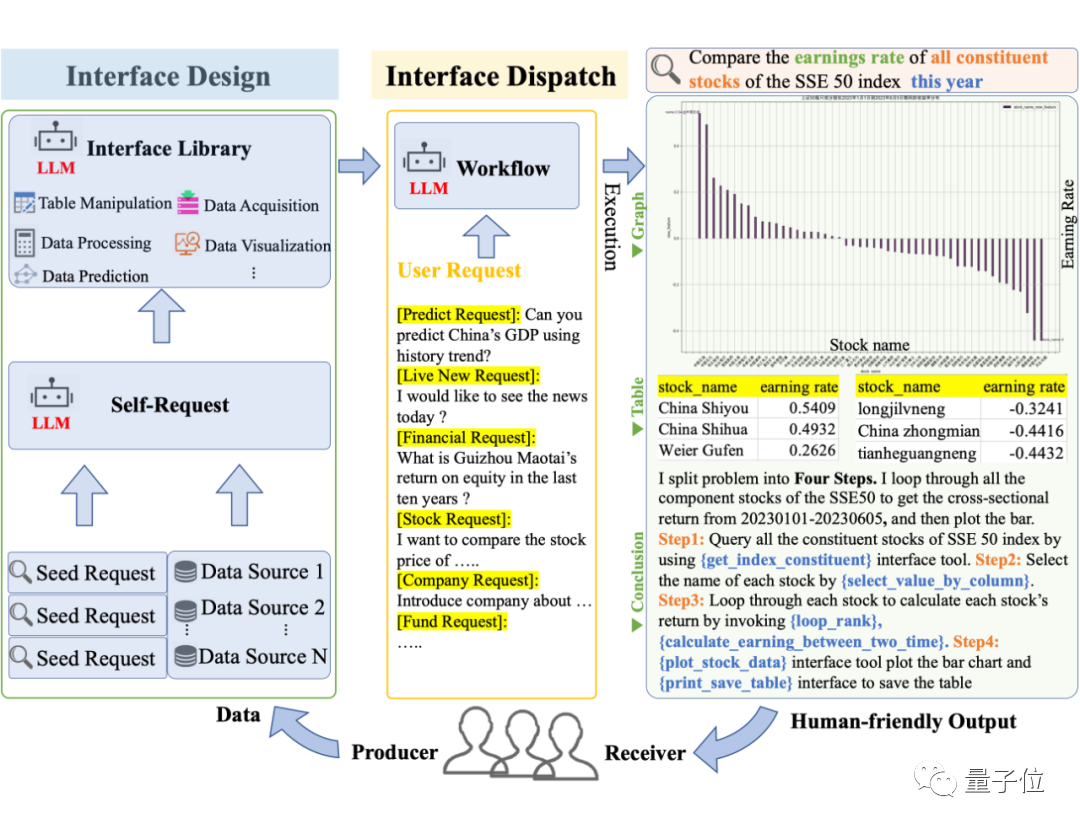 圖片
圖片
在接收到複雜請求時,Data-Copilot會自主設計並調度獨立的接口,建立一個工作流程來滿足使用者的意圖。
在沒有人類協助的情況下,它能夠熟練地將來自不同來源、不同格式的原始資料轉化為人性化的輸出,如圖形、表格和文字。
 圖片
圖片
Data-Copilot專案的主要貢獻包括:
- 連接了不同領域的資料來源和多樣化的使用者需求,減少了繁瑣的勞動和專業知識。
- 實現了自主管理、處理、分析、預測和視覺化數據,可將原始數據轉化為最符合使用者意圖的資訊性結果。
- 具有設計者和調度者的雙重身份,包括兩個過程:介面工具的設計過程(設計者)和調度過程(調度者)。
- 基於中國金融市場數據建構了Data-Copilot Demo。
自主設計並執行工作流程
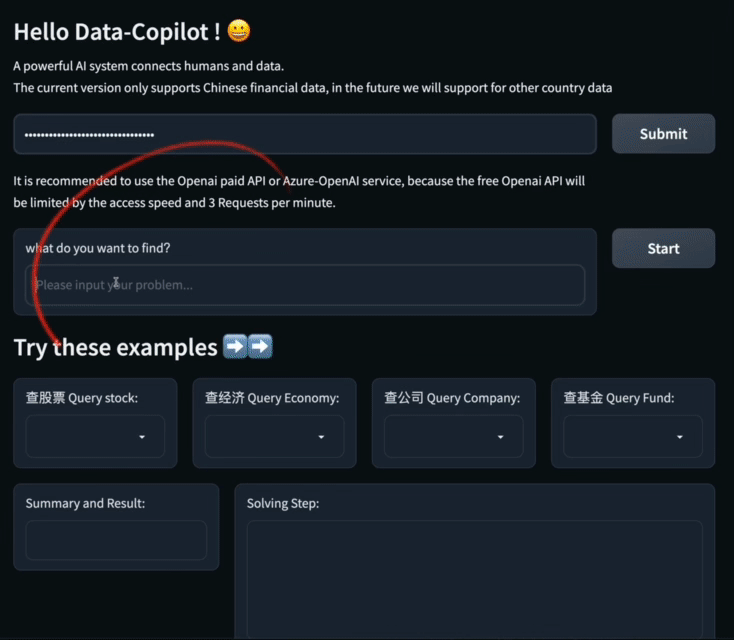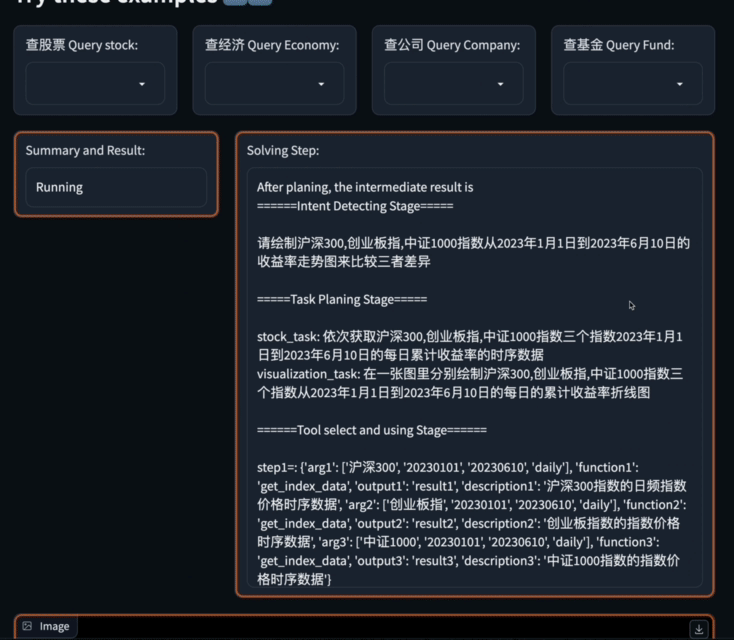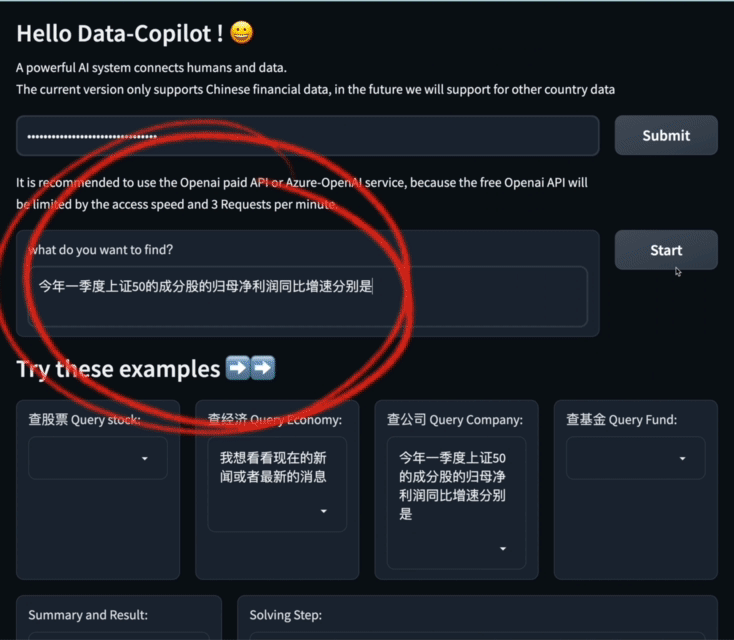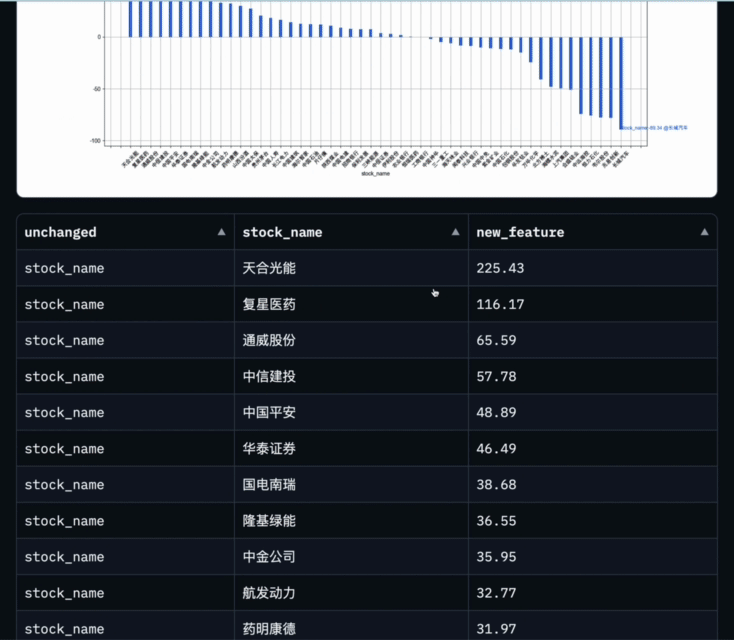
不妨以下面這個範例來看看Data-Copilot的表現:
今年第一季上證50指數的所有成分股的淨利潤增長率是多少
Data-Copilot自主設計了這樣的工作流程:
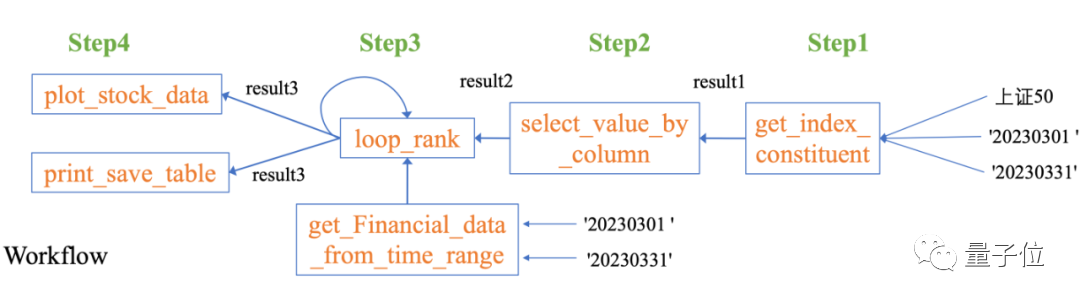 圖片
圖片
針對這個複雜的問題,Data-Copilot採用了loop_rank這個介面來實作多次循環查詢。
Data-Copilot執行該工作流程後得到了這樣的結果:
其中橫座標是每隻成分股的名字,縱座標是第一季的淨利潤同比成長率
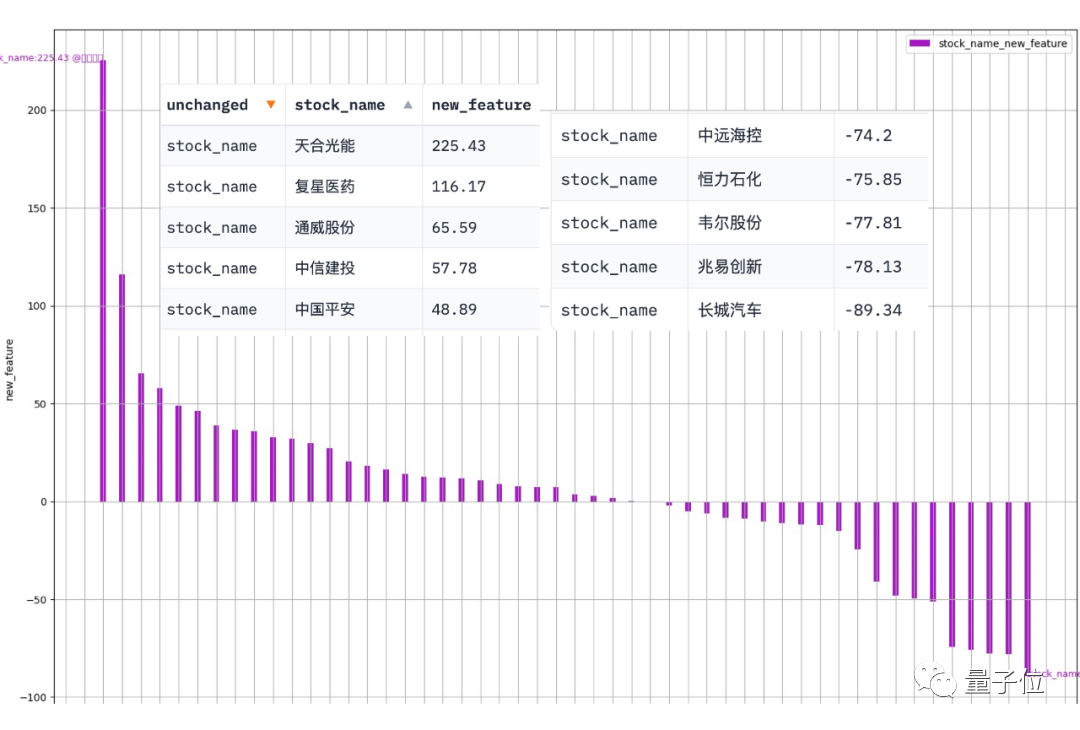 圖片
圖片
除了一般的資料處理過程之外,Data-Copilot還能產生種類豐富的工作流程。
研究團隊以預測和並行兩種工作流程模式分別對Data-Copilot進行了測試。
預測工作流程
對於已知資料以外的部分,Data-Copilot也可以進行預測,例如輸入下面這個問題:
預測下面四個季度的中國季度GDP
Data-Copilot部署了這樣的工作流程:
取得歷史GDP資料→採用線性迴歸模型預測未來→輸出表格
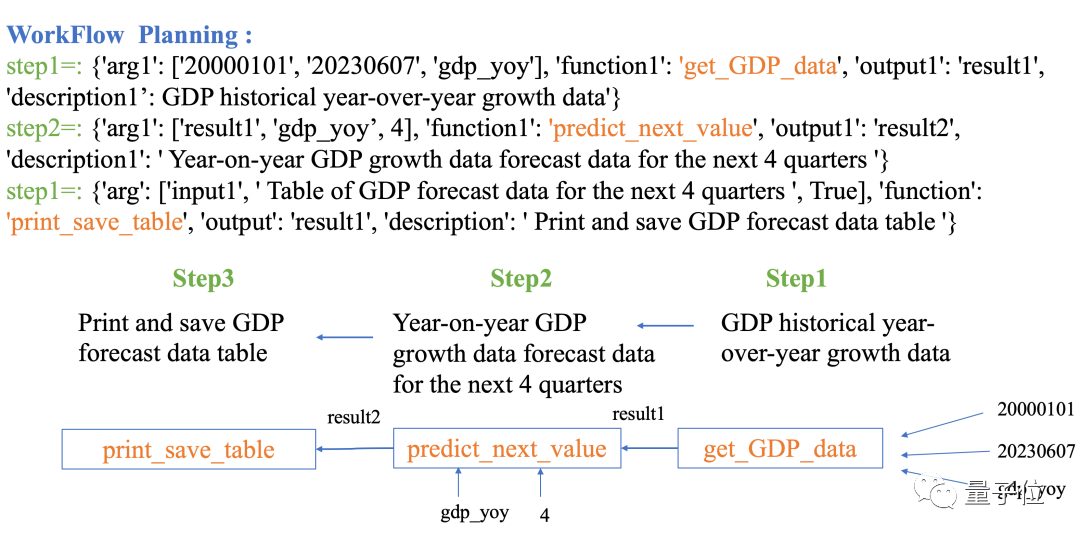 圖片
圖片
執行後的結果如下:
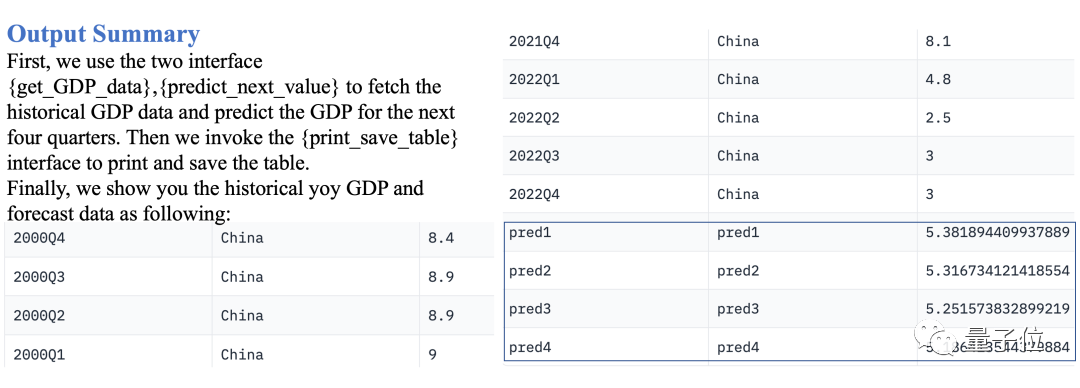 圖片
圖片
並行工作流程
我想看看最近三年寧德時代和貴州茅台的本益比
對應的工作流程是:
取得股價數據→計算相關指數→產生圖表
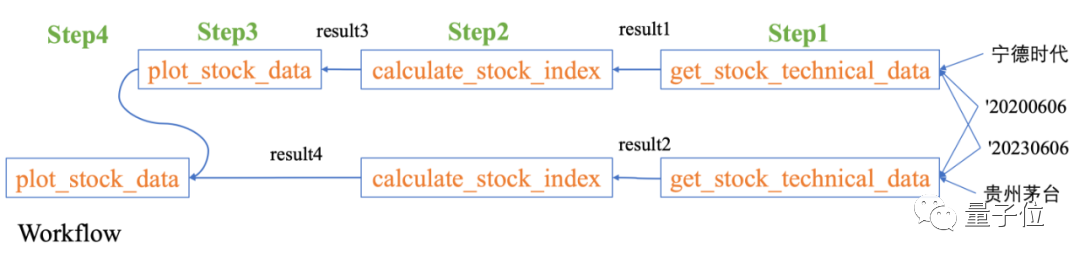 圖片
圖片
兩股的相關工作是同時並行的,最後得到的如下的圖表:
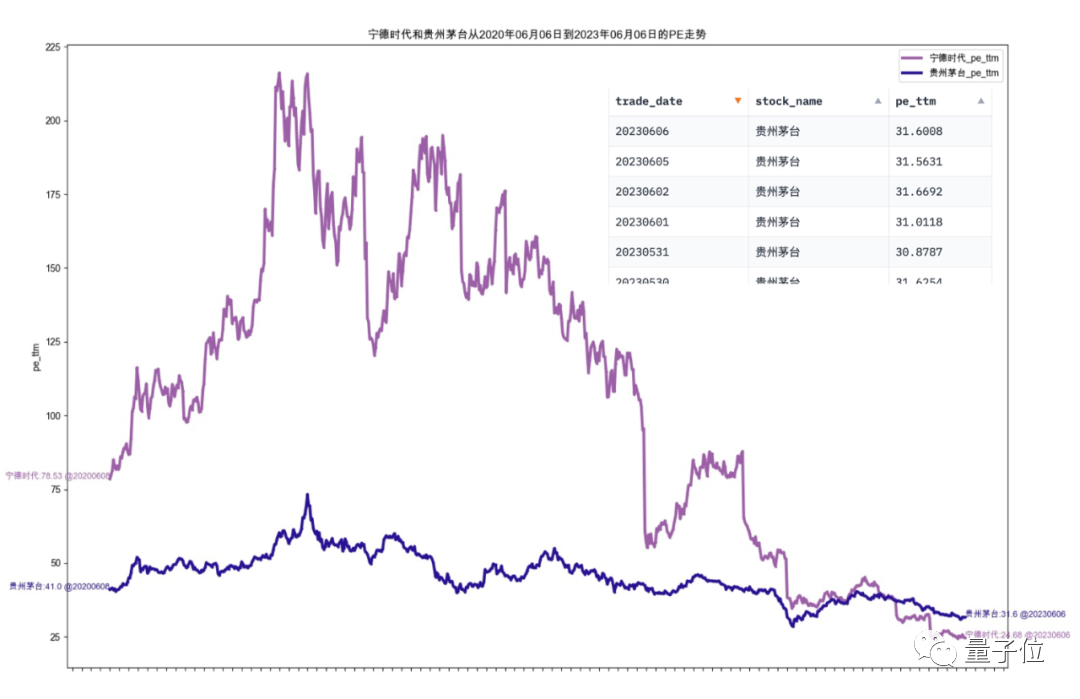 圖片
圖片
#主要方法
Data-Copilot是一個通用的大語言模型系統,具有介面設計和介面調度兩個主要階段。
- 介面設計:研究團隊設計了一個self-request的過程,使LLM能夠自主地從少量種子請求產生足夠的請求。然後,LLM根據產生的請求進行迭代式的設計和最佳化介面。這些介面使用自然語言描述,使它們易於擴展和在不同平台之間轉移。
- 介面調度:在接收到使用者請求後,LLM根據自設計的介面描述和in context demonstration來規劃和呼叫介面工具,部署一個滿足使用者需求的工作流程,並以多種形式呈現結果給用戶。
Data-Copilot透過自動產生請求和自主設計介面的方式,實現了高度自動化的資料處理和視覺化,滿足使用者的需求並以多種形式向使用者展示結果。
 圖片
圖片
介面設計
如上圖所示,首先要實作資料管理,第一步需要介面工具。
Data-Copilot會自行設計了大量介面作為資料管理的工具,其中介面是由自然語言(功能描述)和程式碼(實作)組成的模組,負責資料擷取、處理等任務。
- 首先,LLM透過少量的種子請求並自主產生大量請求(explore data by self-request),盡可能覆蓋各種應用場景。
- 然後,LLM為這些請求設計對應的介面(interface definition:只包含描述和參數),並在每次迭代中逐步最佳化介面設計(interface merge)。
- 最後,研究人員利用LLM強大的程式碼產生能力為介面庫中的每個介面產生具體的程式碼(interface implementation)。這個過程將介面的設計與具體的實作分開來,創建了一套多功能的介面工具,可以滿足大多數請求。
如下圖:Data-Copilot自己設計的介面工具用於資料處理
 #圖片
#圖片
- Data-Copilot首先進行意圖分析來準確地理解使用者的請求。
- 一旦準確了解使用者的意圖,Data-Copilot將規劃一個合理的工作流程來處理使用者的請求。 Data-Copilot會產生一個固定格式的JSON,代表調度的每個步驟,例如step={“arg”:””, “function”:””, “output”:”” ,”description”:””} 。
GitHub專案頁:https://github.com/zwq2018/Data-Copilot
論文網址:https://arxiv.org/abs /2306.07209
HuggingFace DEMO:https://huggingface.co/spaces/zwq2018/Data-Copilot
以上是一句話搞定數據分析,浙大全新大模型數據助手,連蒐集都省了的詳細內容。更多資訊請關注PHP中文網其他相關文章!