
Linux 保護模式下的記憶體管理

- 王林轉載
- 2023-07-06 15:20:031399瀏覽
我們知道,記憶體可以看做一個非常大的數組,我們想要查找記憶體中某個元素的話,會透過數組的下標來指定,記憶體也是如此,不過這有一個前提是這個數組是由一組有序的位元組組成的,在這個有序的位元組數組中,每個位元組都有一個唯一的位址,這個位址也叫做記憶體位址。
記憶體中儲存著很多對象,每個對像是由不同位元組組成的,例如一個char 對象,一個byte 對象,一個int 對像等等,它們都分部在記憶體的各個位置中, CPU 對記憶體中這些物件的位址定位的操作就叫做記憶體定址。記憶體匯流排寬度決定了可以定址多少位的記憶體位址,從位址0開始計算。由於 80X86 是 32 位元的,所以匯流排寬度也是 32 位,因此總共有 2 ^ 32 個記憶體位址,所以總共可以存放 4GB 的記憶體位址。可以透過連續的記憶體位址來提取多個位元組的資料類型,例如 int、long、double。
雖然能夠尋址到對象,但是這些對象存放的位元組順序是不同的,這裡分為兩種存放方式,即大端法和小端法。
例如現在有一個 int 類型的對象,位於地址 0x100 處,它的十六進制數值是 0x01234567,我給你畫一幅圖你就明白這兩個存放順序的區別了。
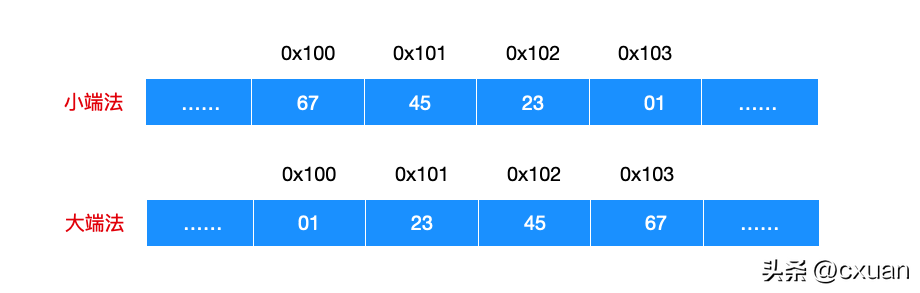
這個其實很好理解,0x01234567 的int 資料型別可以分割為01 23 45 67 個位元組,並且01 是高位,67 是低位,所以可以解釋小端法和大端法的儲存順序:即小端法是低位在前,而大端法是高位在前。大端法和小端法只是儲存順序的區別,和物件的位數、數值無關。大多數 Intel 機器都採用的是小端模式,所以 80X86 也是小端存儲,而一些 IBM 和 Oracle 的大多數機器都是使用的大端存儲方式。
由於電腦是無法直接將記憶體中的資料一次全部尋址完畢,因為它相對實在太過龐大,所以記憶體一般會進行分段,這裡就涉及一個疑問:即記憶體為什麼要分段。我上面只是籠統的介紹了下。
記憶體為什麼要分段?
https://www.php.cn/link/d005ce7aeef46bd18515f783fb8e87fa
使用分段機制,記憶體空間被劃分為線性區域,每個線性區域可以通過段基址加上段內偏移定位。段基址部分由16 位元的段選擇符來指定,其中14 位元是可以選擇2 ^ 14 次方即16384 個段,段內偏移位址部分使用32 位元的值來指定,因此段內位址可以是0 - 4G ,一個段的最大長度是4 GB,這也就和上面所說的4 GB 的記憶體位址相呼應。由 16 位元段和 32 位元段內偏移所構成的 48 位元位址或長指標稱為一個邏輯位址,邏輯位址就是虛擬位址。
X86架構中有六個特殊的暫存器用來存放段基址,它們分別是CS、DS、ES、SS、FS和GS。其中 CS 用於尋址程式碼段,SS 用於尋址堆疊段,其他暫存器用於尋址資料段。在任何指定時刻由 CS 尋址的段稱為目前程式碼段。在目前程式碼段內下一條需要執行的指令的偏移位址已經存在於EIP暫存器中。此時的段基址:偏移位址就可以表示為 CS:EIP 了。
由段寄存器SS 尋址的段稱為當前堆疊段,棧頂由ESP 寄存器給出,在任何時刻SS:ESP 都指向棧頂,並且沒有例外情況,其他四個是通用數據段寄存器,當指令中預設沒有資料段時,由DS 給出。
位址轉換
通常,一個完整的記憶體管理系統由兩個組成部分組成:存取保護和位址轉換。存取保護是為了防止一個應用程式存取的記憶體位址是另一塊程式所使用的;位址轉換就是提供不同的應用程式一個動態的位址分配方式。訪問保護和地址轉換是相輔相成的。
位址轉換通常以記憶體區塊作為基本單位,這裡解釋下什麼是區塊,大家知道在Linux 中,一切都是文件,而文件就是由一個個的區塊構成的,區塊(block)是用來描述檔案系統的組成單位,也是資料處理的基本單位。常見的塊有不同大小,如 512B、1KB、4KB 等,雖然塊是基本單位,但它實質上是由一個個扇區構成的。
位址轉換有兩種實作方式:分段機制和分頁機制。 x86 在記憶體管理的實作方式結合了分段和分頁機制,以下是虛擬位址經過分段和分頁後轉換為實體位址的映射圖
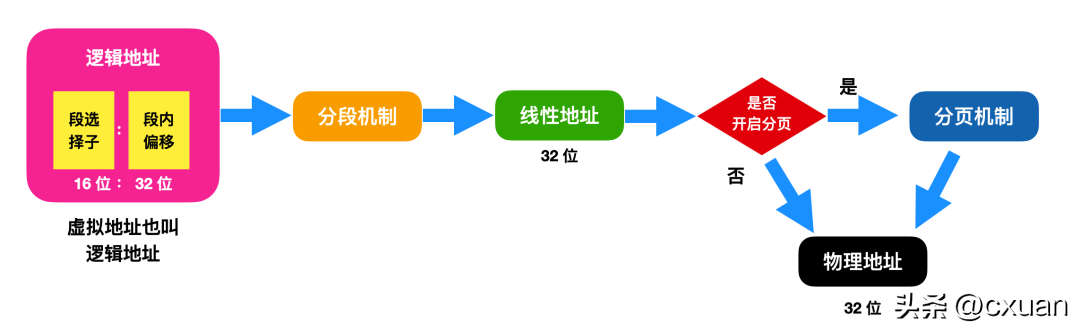
針對這張圖,有必要解釋一下:
首先,這張圖包含三個位址和這三個位址的轉換過程,從大體上來看,邏輯位址會經過分段基址轉換後變成線性位址,線性位址是保護模式下的段基址段內偏移,因此這張圖是保護模式下的位址轉換圖。線性位址會經過分頁機制後轉換為實體位址,前提是需要開啟分頁機制;如果沒有開啟分頁機制,線性位址 = 實體位址。
需要再說一下邏輯位址,邏輯位址裡麵包含段選擇子和段內偏移,段選擇子這個概念我剛開始接觸也比較模糊,簡單一點來說可以把它理解為是保護模式下的段基址,大家知道段基址是16 位元的,而段內偏移是32 位元的。
很多書或文章中都提到了段選擇符,其實段選擇子就是段選擇符,這完全是翻譯問題,英文都是 selector。
後面會提到段描述符,段描述符和段選擇子不是一回事,但段選擇子是一個 16 位元的段描述符。
再跟大家說一下這個圖上沒有寫出來的內容,現在大家知道邏輯位址可以轉換成線性位址,線性位址可以轉換成實體位址,那麼根源是如何轉換的呢?實際上這裡使用的方式是 MMU(記憶體管理單元)進行轉換;而線性位址轉換為實體位址使用的是分頁單元的硬體電路。本文的重點不在於討論具體的轉換過程,而是將重點放在分段和分頁這兩個機制。
下面來詳細聊一聊分段和分頁這兩個機制。
分段機制
這裡推薦大家先看一下我寫的 "記憶體為什麼要分段" 的那段描述。
https://www.php.cn/link/d005ce7aeef46bd18515f783fb8e87fa
多個程式在同一個記憶體空間中運行,不會互相干擾,這是因為分段提供了隔離程式碼、資料和堆疊區域的機制。如果CPU 中有多個程式或任務正在運行,那麼每個程式都可以分配各自的一套段(包含程式碼、資料和堆疊),CPU 透過加強段之間的界限來達到防止應用程式相互幹擾的目的。
一個系統中所有使用的段都包含在 CPU 的線性位址空間中。為了定位指定段中的字節,程式必須提供邏輯位址才能轉換。邏輯位址包含段選擇子和段內偏移,每個段都有一個段描述符,段描述符用於指出段的大小、訪問權限和段的特權級、段類型以及段第一個字節在線性位址空間中的位置(段基址)。邏輯位址的偏移量部分加到段基址上就可以定位段中某個位元組的位置,因此段基址 偏移量形成了 CPU 線性位址空間中的位址。
線性位址空間與實體位址空間具有相同的結構,但是它們所能容納的段相差甚遠,虛擬位址也就是邏輯位址空間可包含最多16 K 的段,而每個段可容納的大小為4 GB ,所以虛擬位址總共能查找到64TB(2 ^ 46) 的段,線性位址和實體位址的空間是4GB (2 ^ 32)。所以,如果禁用了分頁機制,那麼線性位址空間就是實體位址空間。
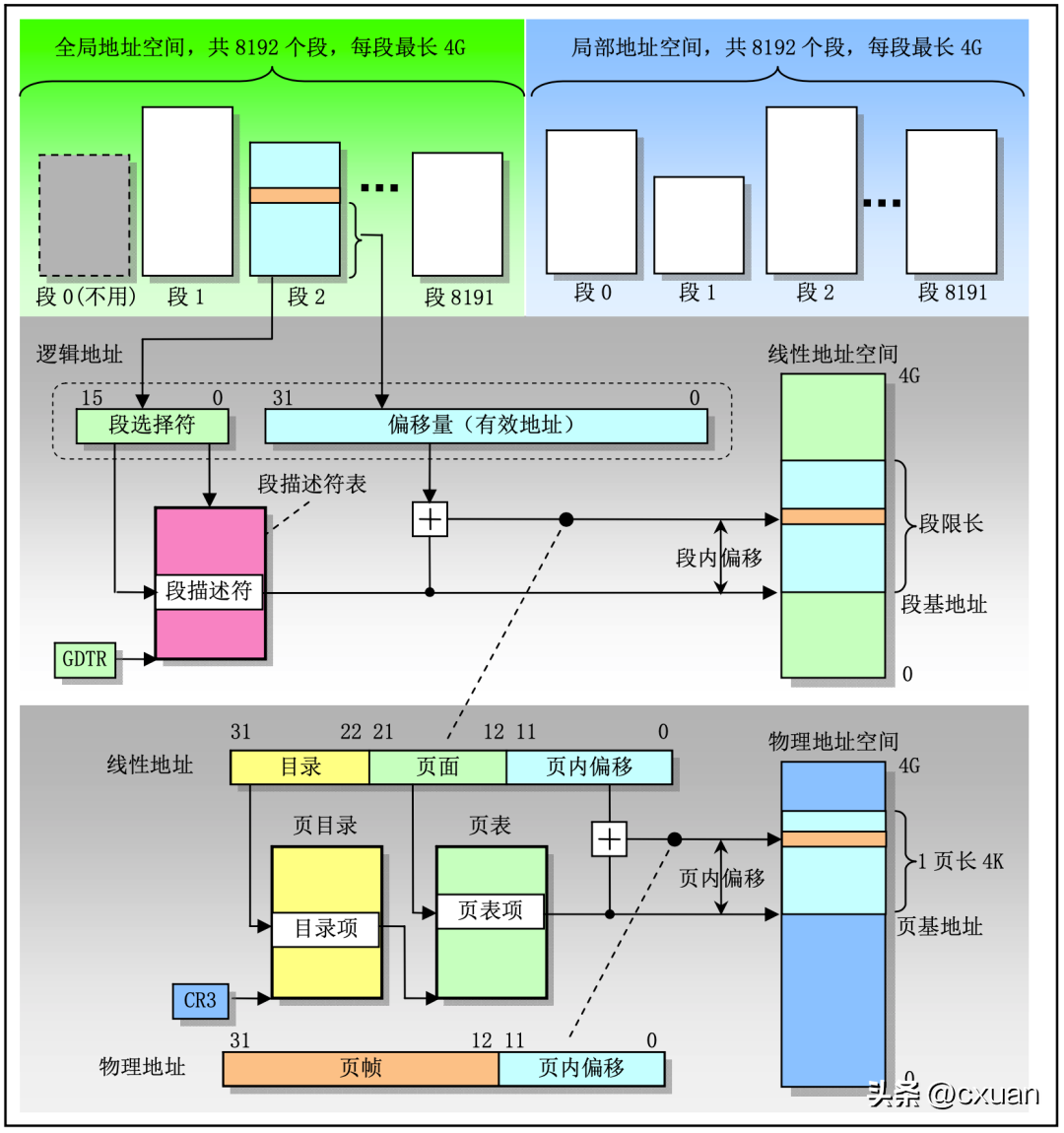
這幅圖就是邏輯位址-> 線性位址-> 實體位址的對應圖,GDT 表和LDT 表各佔一半的位址空間,各為8192個段,每個段最長為4 G,從GDT 表還是LDT 表查詢,具體從哪個表查還是要看段選擇子的TI 屬性,段選擇子的結構如下所示

#段選擇子總共分成三個部分:
- RPL(Request Privilege Level):請求特權級,表示行程應該以什麼權限來存取段,數值越大權限越小。
- TI(Table Indicator):表示應該查詢哪一個表,TI = 0 查 GDT 表;TI = 1 查詢 LDT 表。
- Index:CPU 會自動將 Index * 8,加上 GDT 和 LDT 中的段基址,就是要載入的段描述子。
這裡沒有太細緻的詳解一下段描述符,因為此篇還是偏向於記憶體管理,沒有太執著於某個細節。
在GDTR中,段選擇子和偏移量組成的邏輯位址可以合成段描述符,並直接保存。段選擇子和段內偏移經過 MMU 後可以轉換成為線性位址。
分頁機制
上面我們說到,線性位址是由邏輯位址轉換過來的,如果停用了分頁機制,線性位址就是實體位址,如果開啟分頁機制,線性位址和邏輯地址空間的數量還是不同的。一般程序都是多任務的,而多任務通常定義的線性位址空間要比實體記憶體容量大得多,為什麼呢?地址轉換映射圖上畫著明明線性位址和物理位址都是 4G 的大小啊。那是因為,線性位址被虛擬儲存技術所虛擬化了。
虛擬儲存是一種記憶體管理技術,使用這項技術可以讓我們產生記憶體空間要比實際的實體記憶體容量大的多的錯覺,其本質是把記憶體虛擬化了,就是說記憶體可能只有4G,但你以為記憶體有64 G,所以我為什麼能開那麼多應用程式的原因。
分頁機制其實就是虛擬化的一種實現,在虛擬化的環境中,大量的線性位址空間會對應到一小塊實體記憶體(RAM 或 ROM)。當進行分頁時,每個段被分割為頁面(通常是4K),這些頁面會儲存在實體記憶體或磁碟上。作業系統透過使用一個頁目錄和頁表來維護這些頁面。當程式試圖存取線性位址空間中的某一個位址位置時,CPU 就會使用頁目錄和頁表把這個線性位址轉換成實體位址,再儲存在實體記憶體上。
如果目前存取的頁面不在實體記憶體中,CPU 就會執行中斷,一般錯誤就是頁面異常,然後作業系統會把這個頁面從硬碟上讀入實體記憶體中,然後繼續從中斷處執行程式.作業系統常常頻繁進行頁面換入和換出,這也成為一個效能瓶頸。
在分段中,每個段落的長度是不固定的,最大長度為4G;而在分頁中,每個頁面的大小是固定的。不論在實體記憶體或磁碟上,使用固定大小的頁面更適合管理實體記憶體;而分段機制使用大小可變的區塊更適合處理複雜系統的邏輯分割區。
儘管分段和分頁是兩種不同的位址轉換機制,但它們在整個位址變換過程中被獨立處理,每個過程都是獨立的。這兩種機制都使用了一種中間表來儲存表項映射,但是這個中間表的結構是不同的。段表存在線性位址空間中,頁表則儲存在實體位址空間。
保護機制
80x86擁有兩種保護機制,其中一種是透過為每個任務分配不同的虛擬位址空間來實現任務之間的完全隔離。這是透過給每個任務邏輯位址到實體位址的不同變換得到的,每個應用程式只能存取自己虛擬空間內的資料和指令,只能透過它自己的映射得到實體位址;第二種機制是保護任務,保護作業系統的記憶體段和一些特殊暫存器不會被應用程式所存取。下面我們就來具體探討一下這兩個任務。
任務之間的保護
每個任務會單獨的放在自己的虛擬位址空間中,再經過硬體映射成為物理位址,不同的虛擬位址會轉換成為不同的物理位址,不會存在A 的虛擬位址會對應到B 所在的實體位址的範圍內,這樣就會把所有的任務隔絕開,且不同任務之間不會互相干擾。
每個任務都有各自的映射表、段表和頁表,當 CPU 切換不同的應用程式或任務時,這些表也會切換。
虛擬位址是作業系統的抽象,也就是說虛擬位址完全是作業系統所抽象化能夠更好管理應用程式和任務的載體,每個任務都可以把邏輯位址映射成為虛擬位址,這也顯示每個任務都可以存取作業系統,作業系統可以被所有的任務所共用。這個所有任務都具有相同虛擬位址空間的部分稱為全域位址空間(Global address space),Linux 就使用到了全域位址空間。
全域位址空間中每個任務都有自己的唯一的虛擬位址空間,這個虛擬位址空間叫做局部位址空間(Local address space)。
記憶體段和暫存器的特殊保護
如果將作業系統在不同任務之間的保護比喻為橫向保護,那麼對記憶體段和暫存器的保護可看作是縱向保護。為了限制對任務中各段的訪問,作業系統設定了4個特權級別,以保護每個任務。
優先權分為 4 個等級,0 最高,3 最低。一般最敏感的資料會被賦予最高優先級,它們只能被任務中最受信任的部分訪問,不太敏感的資料會賦予低優先級;內核作業系統存取一般是0 級,應用程式資料一般是3 級。每個記憶體段都與一個特權級相關聯。
我們知道CPU 透過CS 從段中取得指令和資料執行,從段中取得的指令和資料是具有特權級的,一般用當前特權級(Current Privilege Level)來訪問,CPL 就是當前活動程式碼的特權級。當應用程式嘗試存取段時,將與該特權級進行比較,只有低於該段的特權級才能存取。
以上是Linux 保護模式下的記憶體管理的詳細內容。更多資訊請關注PHP中文網其他相關文章!