
NTU、上海AI Lab整理300+論文:基於Transformer的視覺分割最新綜述出爐

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-07-04 12:25:081350瀏覽
SAM (Segment Anything )作為一個視覺的分割基礎模型,在短短的 3 個月時間吸引了許多研究者的注意和跟進。如果你想有系統地了解 SAM 背後的技術,並跟上內捲的步伐,並能做出屬於自己的 SAM 模型,那麼接下這篇 Transformer-Based 的 Segmentation Survey 是不容錯過!近期,南洋理工大學和上海人工智慧實驗室幾位研究人員寫了一篇關於 Transformer-Based 的Segmentation 的綜述,系統地回顧了近年來基於Transformer 的分割與檢測模型,研究的最新模型截止至今年6 月!同時,綜述也包括了相關領域的最新論文以及大量的實驗分析與對比,並揭露了多個具有廣闊前景的未來研究方向!
視覺分割旨在將影像、視訊影格或點雲分割為多個片段或群組。這種技術具有許多現實世界的應用,如自動駕駛、影像編輯、機器人感知和醫學分析。在過去的十年裡,基於深度學習的方法在這個領域取得了顯著的進展。最近,Transformer 成為一種基於自註意力機制的神經網絡,最初設計用於自然語言處理,在各種視覺處理任務中明顯超越了以往的捲積或循環方法。具體而言,視覺 Transformer 為各種分割任務提供了強大、統一甚至更簡單的解決方案。本綜述全面概述了基於 Transformer 的視覺分割,總結了最近的進展。首先,本文回顧了背景,包括問題定義、資料集和以往的捲積方法。接下來,本文總結了一個元架構,將所有最近的基於 Transformer 的方法統一起來。基於這個元架構,本文研究了各種方法設計,包括對這個元架構的修改和相關應用。 此外,本文也介紹了幾個相關的設置,包括 3D 點雲分割、基礎模型調優、域適應分割、高效分割和醫學分割。此外,本文在幾個廣泛認可的數據集上編譯和重新評估了這些方法。最後,本文確定了這個領域的開放挑戰,並提出了未來研究的方向。本文仍會持續與追蹤最新的基於 Transformer 的分割與檢測方法。
 圖片
圖片
專案網址:https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
論文網址:https://arxiv.org/pdf/2304.09854.pdf
研究動機
- ViT 與DETR 的出現使得分割與偵測領域有了十足的進展,目前幾乎各個資料集基準上,排名靠前的方法都是基於Transformer 的。為此有必要有系統地總結與對比下這個方向的方法與技術特性。
- 近期的大模型架構皆基於 Transformer 結構,包含多模態模型以及分割的基礎模型(SAM),視覺各個任務朝向統一的模型建模靠攏。
- 分割與偵測衍生出來了許多相關下游任務,這些任務很多方法也是採用 Transformer 結構來解決。
綜述特色
- #系統性與可讀性。 本文系統性地回顧了分割的各個任務定義,以及相關任務定義,評估指標。而本文從卷積的方法出發,基於 ViT 和 DETR,總結出了一種元架構。基於此元架構,本篇綜述把相關的方法歸納與總結,系統性回顧了近期的方法。具體的技術回顧路線如圖 1 所示。
- 技術的角度進行細緻分類。 比起前人的 Transformer 綜述,本文對方法的分類會更加的細緻。本文把類似想法的論文匯聚在一起,對比了他們的相同點以及不同點。例如,本文會對同時修改元架構的解碼器端的方法進行分類,分為基於影像的 Cross Attention,以及基於視訊的時空 Cross Attention 的建模。
- 研究問題的全面性。 本文會系統地回顧分割各個方向,包括圖像,視頻,點雲分割任務。同時,本文也會同時回顧相關的方向例如開集分割於偵測模型,無監督分割和弱監督分割。
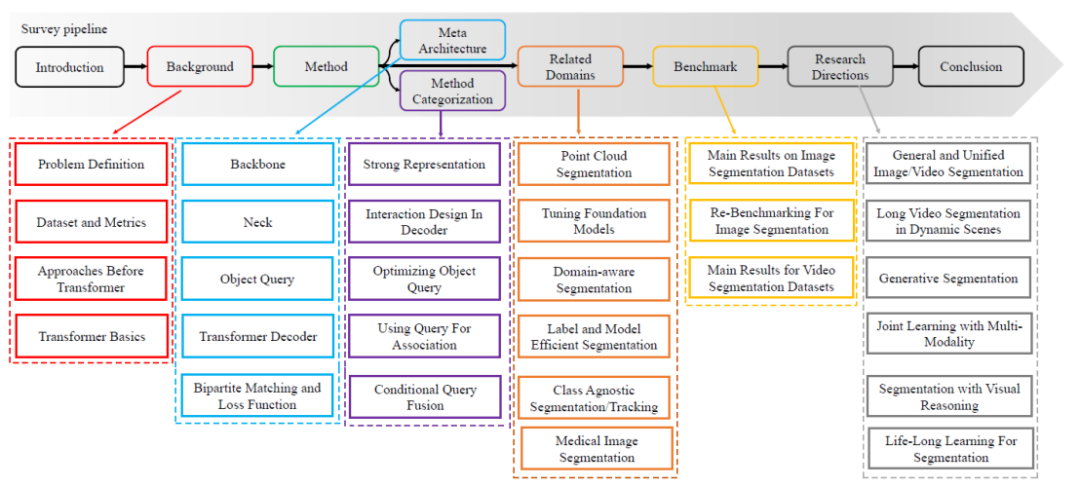 圖片
圖片
#圖 1. Survey 的內容路線圖
#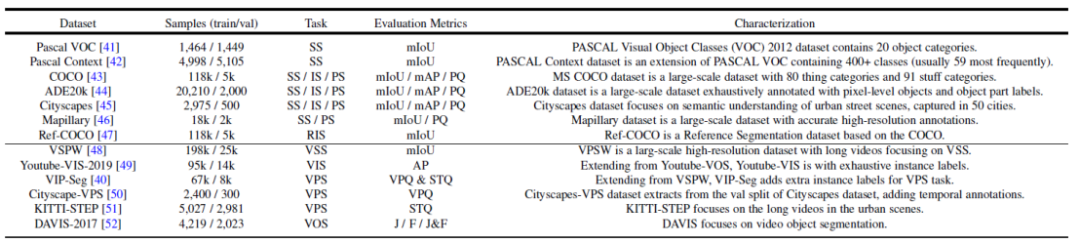
圖2. 常用的資料集以及分割任務摘要
Transformer-Based 分割與偵測方法總結與比較
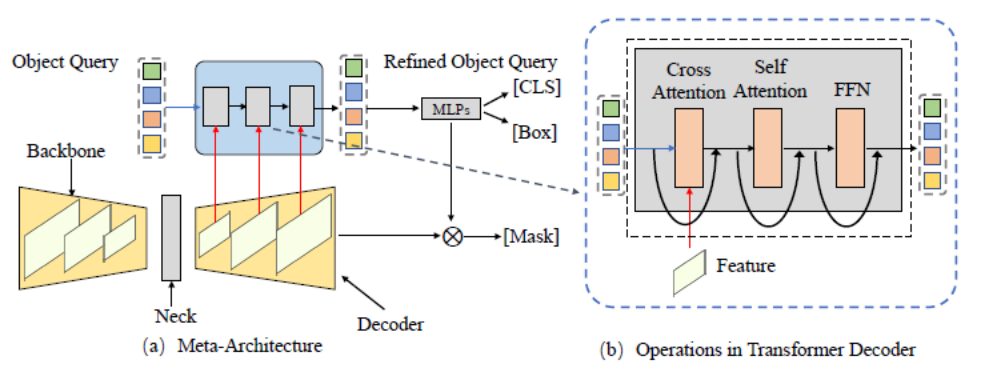
圖3.通用的元架構框架(Meta-Architecture)
本文首先基於DETR 和MaskFormer 的框架總結出了一個元架構。這個模型包含如下幾個不同的模組:
- Backbone:特徵擷取器,用來擷取影像特徵。
- Neck:建構多尺度特徵,用來處理多尺度的物件。
- Object Query:查詢對象,用於代表場景中的每個實體,包括前景物體以及背景物體。
- Decoder:解碼器,用於逐步最佳化 Object Query 以及對應的特徵。
- End-to-End Training:#基於 Object Query 的設計可以做到端到端的最佳化。
基於這個元架構,現有的方法可以分為如下五個不同的方向來進行最佳化以及根據任務進行調整,如圖4 所示,每個方向有包含幾個不同的子方向。
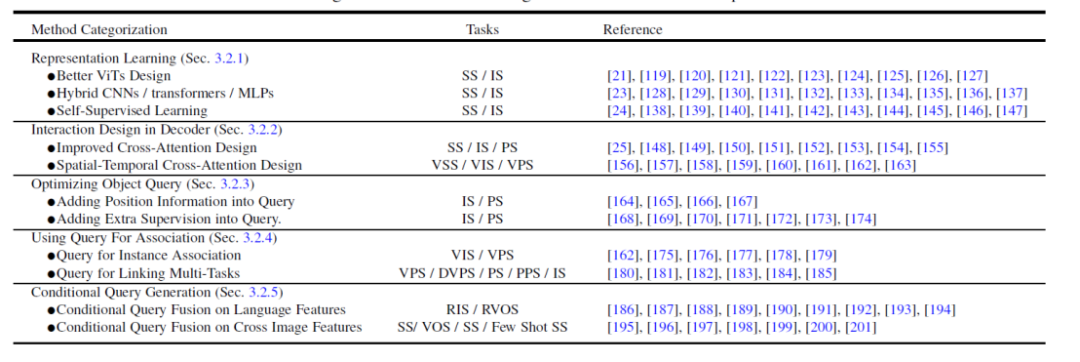
圖 4. Transformer-Based Segmentation 方法總結與比較
- 更好的特徵表達學習,Representation Learning。 強大的視覺特徵表示總是會帶來更好的分割結果。本文將相關工作分為三個面向:更好的視覺 Transformer 設計、混合 CNN/Transformer/MLP 以及自監督學習。
- 解碼器端的方法設計,Interaction Design in Decoder。 本章節回顧了新的 Transformer 解碼器設計。本文將解碼器設計分為兩組:一組用於改善影像分割中的交叉注意力設計,另一組用於視訊分割中的時空交叉注意力設計。前者專注於設計一個更好的解碼器,以改進原始 DETR 中的解碼器。後者將基於查詢物件的目標偵測器和分割器擴展到視訊領域,用於視訊目標檢測(VOD)、視訊實例分割(VIS)和視訊像素分割(VPS),重點在建模時間一致性和關聯性。
- 嘗試從查詢物件最佳化的角度,Optimizing Object Query。 與 Faster-RCNN 相比,DETR 要更長的收斂時間表。由於查詢對象的關鍵作用,現有的一些方法已經展開了研究,以加快訓練速度並提高效能。根據物件查詢的方法,本文將以下的文獻分為兩個面向:新增位置資訊和採用額外監督。位置資訊提供了對查詢特徵進行快速訓練採樣的線索。額外監督著重設計了除 DETR 預設損失函數之外的特定損失函數。
- 使用查詢物件來做特徵和實例的關聯,Using Query For Association。 受益於查詢物件的簡單性,最近的多個研究將其作為關聯工具來解決下游任務。主要有兩種用法:一種是實例層級的關聯,另一種是任務層級的關聯。前者採用實例判別的思想,用於解決影片中的實例層級匹配問題,例如視訊的分割和追蹤。後者使用查詢物件來橋接不同子任務實現高效的多任務學習。
- 多模態的條件查詢物件生成,Conditional Query Generation。 這一章主要關注多模態分割任務。條件查詢查詢物件主要來處理跨模態和跨影像的特徵匹配任務。根據任務輸入條件而決定的,解碼器頭部使用不同的查詢來取得對應的分割遮罩。根據不同輸入的來源,本文將這些工作分為兩個面向:語言特徵和圖像特徵。這些方法基於不同模型特徵融合查詢物件的策略,在多個多模態的分割任務以及 few-shot 分割上取得了不錯的結果。
圖 5 中給出這 5 個不同方向的一些代表性的工作對比。更具體的方法細節以及對比可以參考論文的內容。
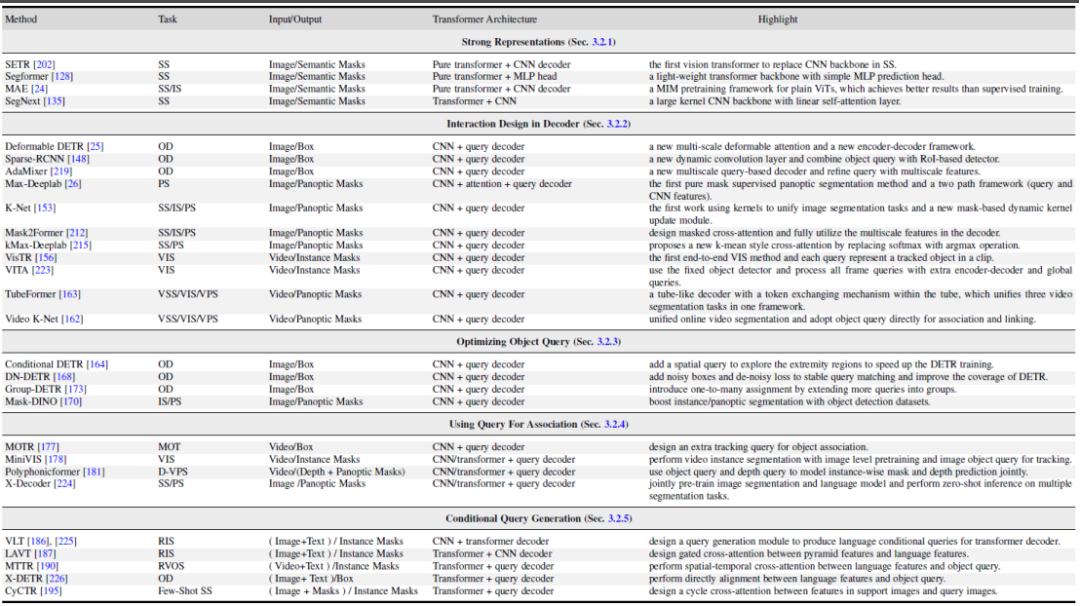 圖片
圖片
圖5. Transformer-based 的分割與偵測代表性的方法總結與比較
相關研究領域的方法總結與比較
本文也探討了幾個相關的領域:1,基於Transformer 的點雲分割方法。 2, 視覺與多模態大模型調優。 3,領域相關的分割模型研究,包括領域遷移學習,域泛化學習。 4,高效語意分割:無監督與弱監督分割模型。 5,類別無關的分割與追蹤。 6,醫學影像分割。
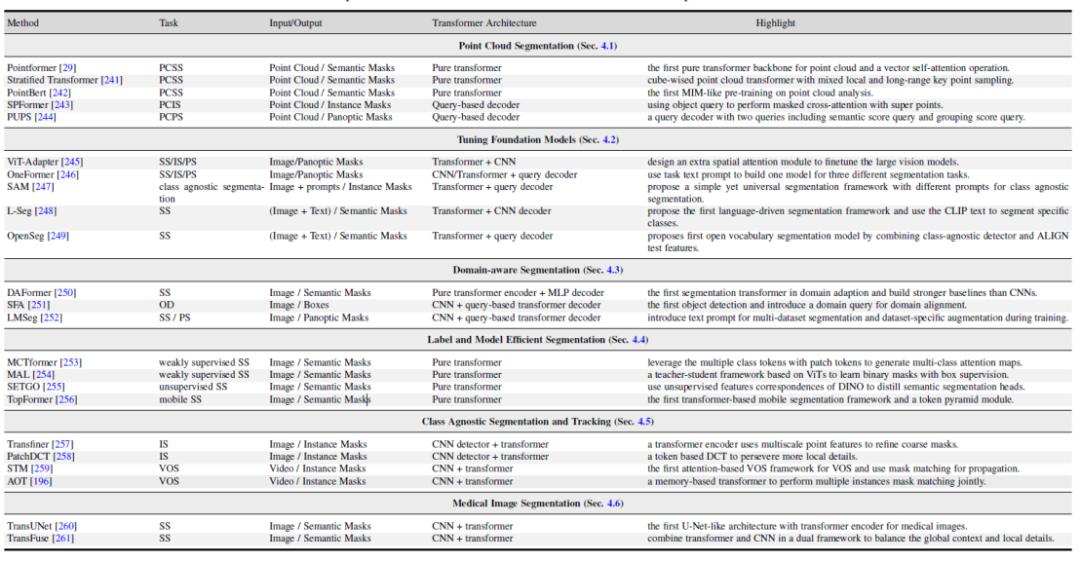 圖片
圖片
圖6. 相關研究領域的基於Transformer 方法總結與比較
不同方法的實驗結果比較
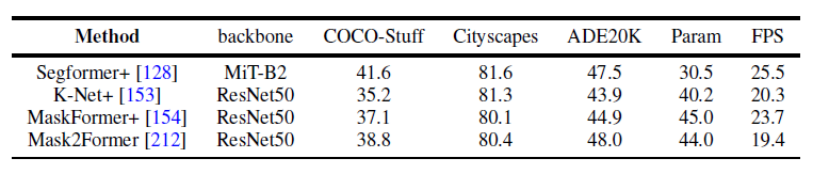
圖7.語意分割資料集的基準實驗
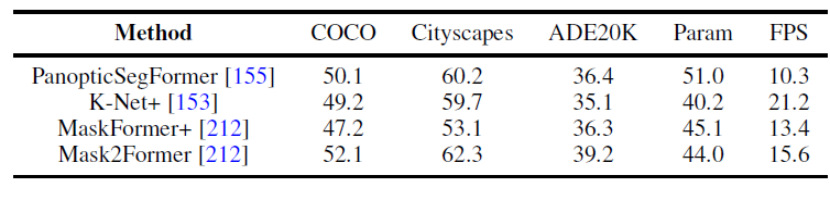
#圖8. 全景分割資料集的基準實驗
本文也統一地使用相同的實驗設計條件來比較了幾個代表性的工作在全景分割以及語意分割上多個資料集的結果。結果發現,在使用相同的訓練策略以及編碼器的時候,方法表現之間的差距會縮小。
此外,本文也同時比較了近期的 Transformer-based 的分割方法在多個不同資料集和任務上結果。 (語意分割,實例分割,全景分割,以及對應的視訊分割任務)
未來方向
此外本文也給了一些未來的可能一些研究方向分析。這裡舉出三個不同的方向作為例子。
- 更加上通用與統一的分割模型。 使用 Transformer 結構來統一不同的分割任務是一個趨勢。最近的研究使用基於查詢物件的 Transformer 在一個體系結構下執行不同的分割任務。一個可能的研究方向是透過一個模型在各種分割資料集上統一影像和視訊分割任務。這些通用模型可以在各種場景中實現通用和穩健的分割,例如,在各種場景中檢測和分割罕見類別有助於機器人做出更好的決策。
- 結合視覺推理的分割模型。 視覺推理要求機器人理解場景中物體之間的聯繫,這種理解在運動規劃中起著關鍵作用。先前的研究已經探索了將分割結果作為視覺推理模型的輸入,用於各種應用,如目標追蹤和場景理解。聯合分割和視覺推理可以是一個有前景的方向,對分割和關係分類都具有互惠的潛力。透過將視覺推理納入分割過程中,研究人員可以利用推理的能力來提高分割的準確性,同時分割結果也可以為視覺推理提供更好的輸入。
- 持續學習的分割模型研究。 現有的分割方法通常在封閉世界的資料集上進行基準測試,這些資料集具有一組預先定義的類別,即假設訓練和測試樣本具有預先知道的相同類別和特徵空間。然而,真實場景通常是開放世界和非穩定的,新類別的數據可能不斷出現。例如,在自動駕駛車輛和醫學診斷中,可能會突然出現未預料到的情況。現有方法在現實和封閉世界場景中的表現和能力之間存在明顯差距。因此,希望能夠逐漸且持續地將新概念納入分割模型的現有知識庫中,使得模型能夠進行終身學習。
更多的研究方向內容可以查閱原始論文。
以上是NTU、上海AI Lab整理300+論文:基於Transformer的視覺分割最新綜述出爐的詳細內容。更多資訊請關注PHP中文網其他相關文章!