
英偉達H100霸榜權威AI性能測試 11分鐘搞定基於GPT-3的大模型訓練

- 王林轉載
- 2023-06-28 20:00:20929瀏覽
當地時間週二,機器學習及人工智慧領域開放產業聯盟MLCommons披露兩項MLPerf基準評測的最新數據,其中英偉達H100晶片組在人工智慧算力表現的測試中,刷新了所有組別的紀錄,也是唯一能夠跑完所有測試的硬體平台。
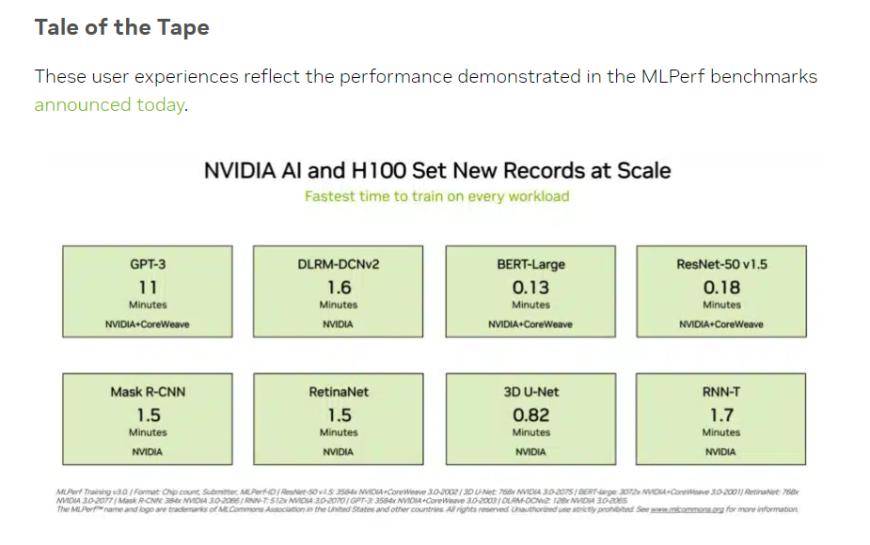
(來源:英偉達、MLCommons)
MLPerf是由學術界、實驗室和產業組成的人工智慧領袖聯盟,是目前國際公認的權威AI效能評測基準。 Training v3.0包含8種不同的負載,包括視覺(影像分類、生物醫學影像分割、兩種負荷的物體偵測)、語言(語音辨識、大語言模型、自然語言處理)和推薦系統。換種說法,就是不同設備供應商完成基準任務所花費的時間不同。
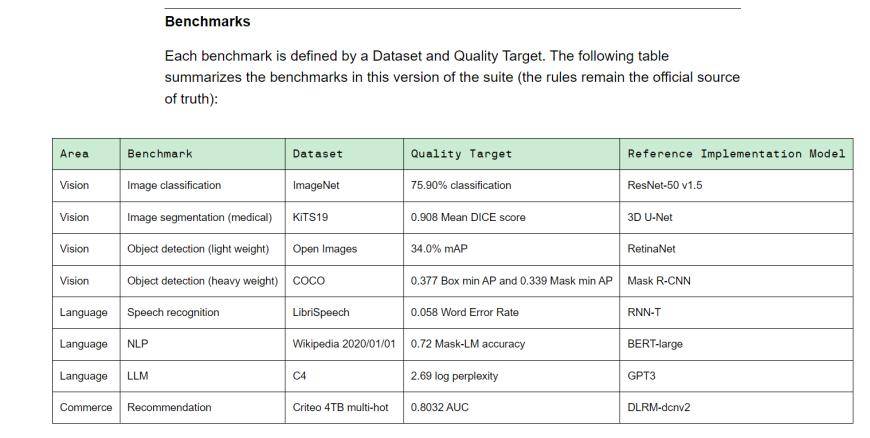
(Training v3.0訓練基準,來源:MLCommons)
在投資人比較關注的「大語言模型」訓練測試中,英偉達和GPU雲端算力平台CoreWeave提交的數據為這項測試設定了殘酷的業界標準。在896個英特爾至強8462Y 處理器和3584個英偉達H100晶片的齊心協力下,僅花了10.94分鐘就完成了基於GPT-3的大語言模型訓練任務。
除了英偉達外,只有英特爾的產品組合在這個專案上獲得評測數據。由96個至強8380處理器和96個Habana Gaudi2 AI晶片建構的系統中,完成同樣測試的時間為311.94分鐘。使用768個H100晶片的平台進行橫向比較測試,僅需45.6分鐘。
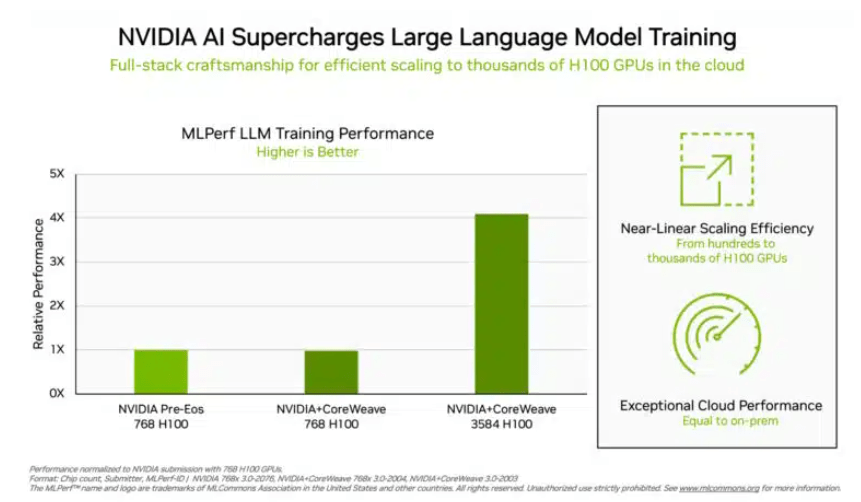
(晶片越多數據越好看,來源:英偉達)
對於這個結果,英特爾也表示仍有上升空間。理論上只要堆更多的晶片,運算的結果自然就會更快。英特爾AI產品資深主管Jordan Plawner對媒體表示,接下來Habana的運算結果將會呈現1.5倍-2倍的提升。 Plawner拒絕透露Habana Gaudi2的具體售價,僅表示業界需要第二家廠商提供AI訓練晶片,而MLPerf的數據顯示英特爾有能力填補這個需求。
而在中國投資者更熟悉的BERT-Large模型訓練中,英偉達和CoreWeave將數據刷到了極端的0.13分鐘,在64卡的情況下,測試數據也達到了0.89分鐘。目前主流大模型的基礎架構是BERT模型中的Transformer結構。
來源:財聯社
以上是英偉達H100霸榜權威AI性能測試 11分鐘搞定基於GPT-3的大模型訓練的詳細內容。更多資訊請關注PHP中文網其他相關文章!