
貧窮讓我預訓練

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-26 08:32:45863瀏覽

一、要不要預先訓練

# #預訓練的效果是直接的,所需的資源常常令人望而卻步。如果存在這種預訓練方法,它的啟動所需算力、資料和人工資源很少,甚至只需要單人單卡的原始語料。經過無監督的資料處理,完成一次遷移到自己領域的預訓練之後,就能獲得零樣本的NLG、NLG和向量表示推理能力,其他向量表示的召回能力超過BM25,那麼你有興趣嘗試嗎?

#要不要做一件事,需要衡量投入產出決定。預訓練是大事,需要一些前置條件和資源,也要充足的預期效益才會實行。通常所需要的條件有:充足的語料庫建設,通常來說質量比數量更難得,所以語料庫的質量可以放鬆些,數量一定要管夠;其次是具備相應的人才儲備和人力預算,相較而言,小模型訓練更容易,障礙更少,大模型遇到的問題會多些;最後才是算力資源,根據場景和人才搭配,豐儉由人,最好有一塊大內存顯示卡。預訓練帶來的效益也直觀,遷移模型能直接帶來效果提升,提升幅度跟預訓練投入和領域差異直接相關,最終收益由模型提升和業務規模共同增益。
在我們的場景中,資料領域跟通用領域差異極大,甚至需要大幅更替詞表,業務規模也已經足夠。如果不預訓練的話,也會為每個下游任務專門微調模型。預訓練的預期效益是確定的。我們的語料庫品質上很爛,但是數量足夠。算力資源很有限,配合對應的人才儲備可彌補。此時預訓練的條件都已經具備。
直接決定我們啟動預訓練的因素是需要維護的下游模型太多了,特別佔用機器和人力資源,需要給每個任務都要準備一大堆資料訓練出一個專屬模型,模型治理的複雜度急遽增加。所以我們探索預訓練,希望能建構統一的預訓練任務,讓各個下游模型都受益。我們做這件事的時候也不是一蹴而就的,需要維護的模型多也意味著模型經驗多,結合之前多個專案經驗,包括一些自監督學習、對比學習、多任務學習等模型,經過反覆實驗迭代融合成形的。 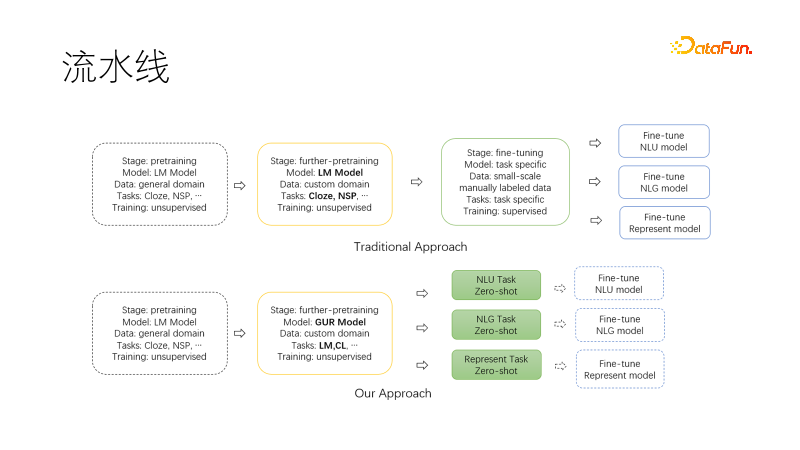
上圖是傳統的nlp管線範式,基於現有的通用預訓練模型,在可選的遷移預訓練完成後,為每個下游任務收集資料集,微調訓練,並且需要許多人工和顯示卡維護多個下游模型和服務。
下圖是我們提出的新範式,在遷移到我們領域繼續預訓練時候,使用聯合語言建模任務和對比學習任務,使得產出模型具備零樣本的NLU、NLG、向量表示能力,這些能力是模型化的,可以按需取用。如此需要維護的模型就少了,尤其是在專案啟動時候可以直接用於調查,如果有需要再進一步微調,所需的資料量也大大降低。
二、如何預先訓練
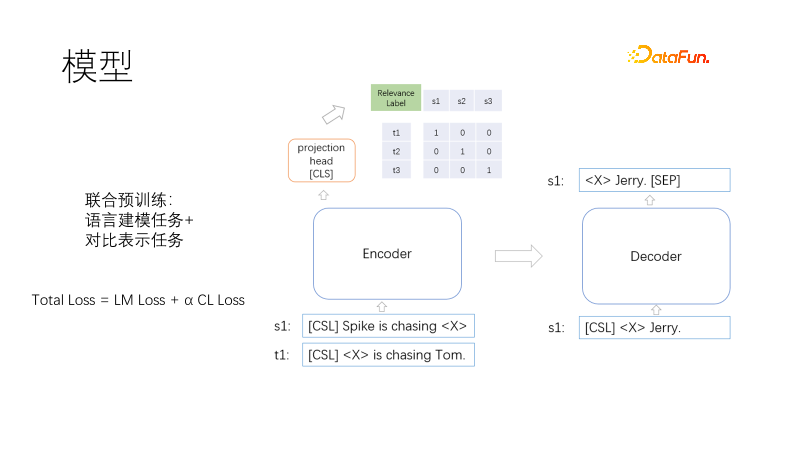
## #########這是我們的預訓練模型架構,包括Transformer的編碼器、解碼器和向量表示頭。 ##########
預訓練的目標包括語言建模和對比表示,損失函數為Total Loss = LM Loss α CL Loss,採用語言建模任務與對比表示任務聯合訓練,其中α表示權重係數。語言建模採用遮罩模型,類似T5,只解碼遮罩部分。對比表示任務類似CLIP,在一個批次內,有一對相關訓練正樣本,其他未負樣本,對於每一條樣本對(i,I)中的i,有一個正樣本I,其他樣本為負樣本,使用對稱交叉熵損失,迫使正樣本的表示相近,負樣本的表示相遠。採用T5方式解碼可以縮短解碼長度。一個非線性向量表示頭加載編碼器上方,一是向量表示場景中要求更快,二是兩個所示函數作用遠離,防止訓練目標衝突。那麼問題來了,完形填空的任務很常見,不需要樣本,那相似性樣本對是怎麼來的呢?

#當然,作為預訓方法,樣本對一定是無監督演算法挖掘的。通常資訊檢索領域採用挖掘正樣本基本方法是逆完形填空,在一篇文件中挖掘幾個片段,假定他們相關。我們這裡將文檔拆分為句子,然後列舉句子對。我們採用最長公共子字串來判定兩個句子是否相關。如圖取兩個正負句對,最長公共子串長到一定程度判定為相似,否則不相似。閾值自取,例如長句子為三個漢字,英文字母要求多一些,短句子可以放鬆些。
我們採用相關性作為樣本對,而不是語意等價性,是因為二者目標是衝突的。如上圖所示,貓抓老鼠跟老鼠抓貓,語意相反卻相關。我們的場景搜尋為主,更專注於相關性。而且相關性比語意等價性更廣泛,語意等價更適合在相關性基礎上繼續微調。
有些句子篩選多次,有些句子沒有被篩選。我們限制句子入選頻次上限。對於落選句子,可以複製作為正樣本,可以拼接到入選句子中,也可以用逆向完型填空作為正樣本。
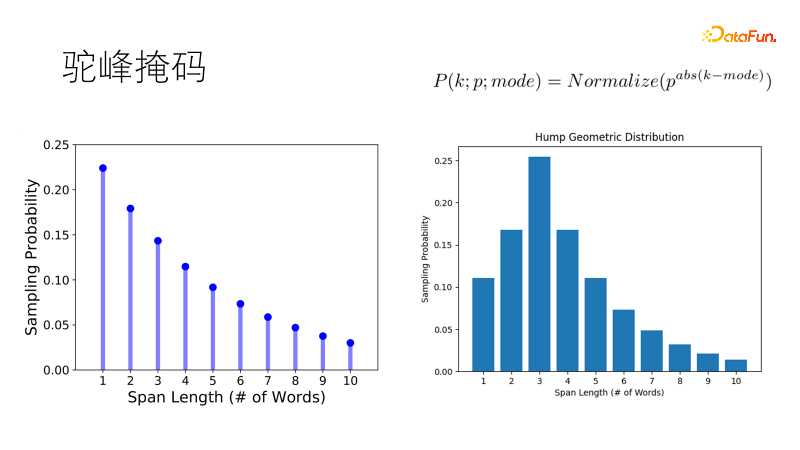
傳統的遮罩方式如SpanBert,採用幾何分佈取樣遮罩長度,短遮罩機率高,長掩碼機率低,適用於長句子。但我們的語料是支離破碎的,當面對一二十個字的短句子時,傳統傾向掩碼兩個單字勝過遮蔽一個雙字,這不符合我們期望。所以我們改進了這個分佈,讓他取樣最優長度的機率最大,其他長度機率逐次降低,就像一個駱駝的駝峰,成為駝峰幾何分佈,在我們短句富集的場景中更加健壯。
三、實驗效果
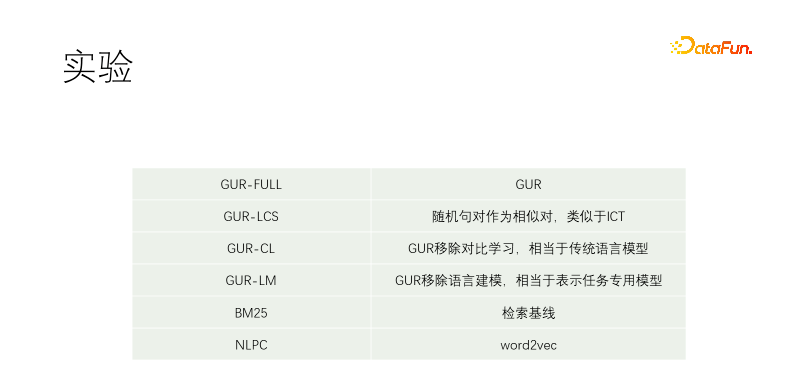
#我們做了對照實驗。包括GUR-FULL,用到了語言建模和向量對比表示;UR-LCS的樣本對沒有經過LCS篩選過濾;UR-CL沒有對比表示學習,相當於傳統的語言模型;GUR-LM只有向量對比表示學習,沒有語言建模學習,相當於專門為下游任務微調;NLPC是百度場內的一個word2vec算符。
實驗從一個T5-small開始繼續預訓練。訓練語料包括維基百科、維基文庫、CSL和我們的自有語料。我們的自有語料從物料庫抓來的,品質很差,品質最佳的部分是物料庫的標題。所以在其他文檔中挖正樣本時是近乎任意文字對篩選,而在我們語料庫中是用標題來匹配正文的每一個句子。 GUR-LCS沒有經過LCS選,如果不這樣幹的話,樣本對太爛了,這麼做的話,跟GUR-FULL差別就小多了。
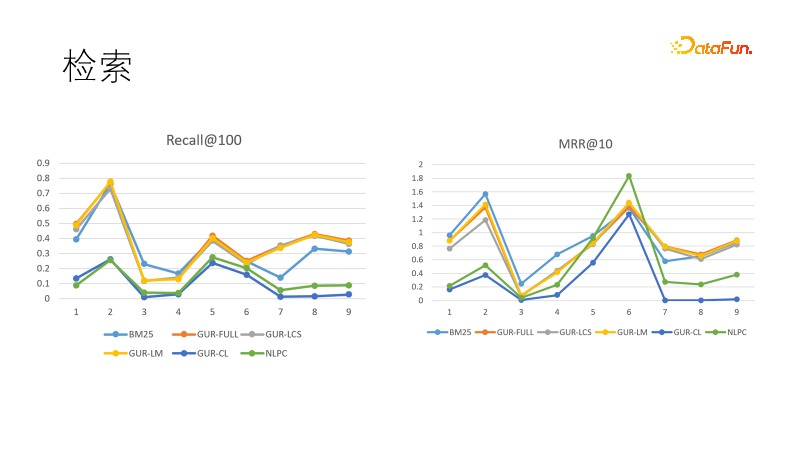
我們在幾個檢索任務中評測模型的向量表示效果。左圖是幾個模型在召回中的表現,我們發現經過向量表示學習的模型表現都是最好的,勝過BM25。我們也比較了排序目標,這回BM25扳回一局。這顯示密集模型的泛化能力強,稀疏模型的確定性強,二者可以互補。實際上在資訊檢索領域的下游任務中,密集模型和稀疏模型經常搭配使用。
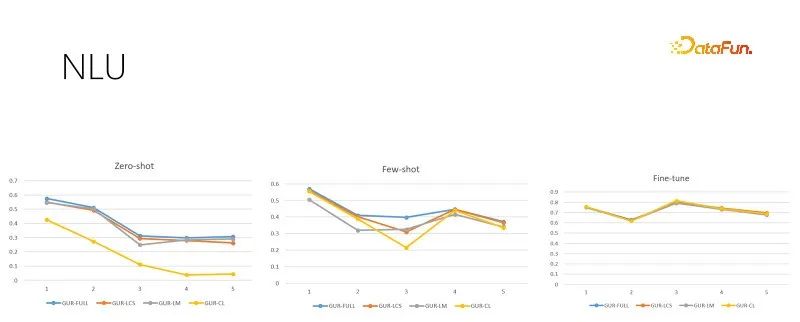
#上圖是不同訓練樣本量的NLU評測任務,每個任務有數十到幾百個類別,以ACC得分評估效果。 GUR模型也將分類的標籤轉換為向量,來為每個句子找到最近的標籤。上圖由左至右依據訓練樣本量遞增分別是零樣本、小樣本和足夠微調評測。右圖是經過充足微調之後的模型表現,顯示了各個子任務的本身難度,也是零樣本和小樣本表現的天花板。可見GUR模型可以依靠向量表示就可以在一些分類任務中實現零樣本推理。且GUR模型的小樣本能力表現最為突出。
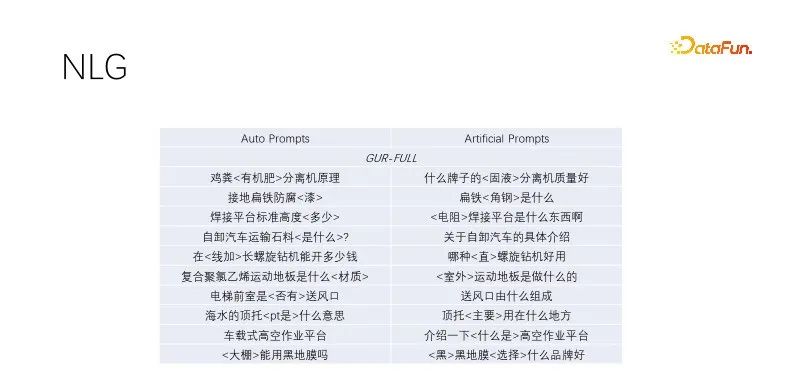
#這是NLG的零樣本表現。我們在做標題生成和query擴展中,挖掘優質流量的標題,將關鍵字保留,非關鍵字隨機掩碼,經過語言建模訓練的模型表現都不錯。這種自動prompt效果跟人工構造的目標效果差不多,多樣性更廣泛,能夠滿足大量生產。經過語言建模任務的幾個模型表現差不多,上圖採用GUR模型範例。
四、結語
#本文提出了一個新的預訓練範式,上述對照實驗顯示了,聯合訓練不會造成目標衝突。 GUR模型在繼續預訓練時,可以在維持語言建模能力的基礎上,增加向量表示的能力。一次預訓練,到處零原樣本推理。適合業務部門低成本預訓練。

#上述連結記載了我們的訓練細節,參考文獻詳見論文引用,程式碼版本比論文新一點。希望能給AI民主化做一點微小貢獻。大小模型有各自應用場景,GUR模型除了直接用於下游任務之外,還可以結合大模型使用。我們在管線中先用小模型辨識再用大模型指令任務,大模型也可以給小模型生產樣本,GUR小模型可以提供大模型向量檢索。
論文中的模型為了探討多個實驗選用的小模型,實踐中若選用更大模型增益明顯。我們的探索還很不夠,需要有進一步工作,如果有意願的話可以聯絡laohur@gmail.com,期待能與大家共同進步。
#以上是貧窮讓我預訓練的詳細內容。更多資訊請關注PHP中文網其他相關文章!