
無需標註數據,「3D理解」進入多模態預訓練時代! ULIP系列全面開源,刷新SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-20 17:33:061441瀏覽
透過對齊三維形狀、二維圖片以及對應的語言描述,多模態預訓練方法也帶動了3D表徵學習的發展。
不過現有的多模態預訓練框架收集資料的方法缺乏可擴展性,極大限制了多模態學習的潛力,其中最主要的瓶頸在於語言模態的可擴展性和全面性。
最近,Salesforce AI聯手史丹佛大學和德州大學奧斯汀分校,發布了ULIP(CVP R2023)和ULIP-2項目,這些項目正在引領3D理解的新篇章。

論文連結:https://arxiv.org/pdf/2212.05171.pdf
#論文連結:https://arxiv.org/pdf/2305.08275.pdf
程式碼連結:https: //github.com/salesforce/ULIP
研究人員採用了獨特的方法,使用3D點雲、圖像和文字進行模型的預訓練,將它們對齊到一個統一的特徵空間。這種方法在3D分類任務中取得了最先進的結果,並為跨領域任務(如影像到3D檢索)開闢了新的可能性。
並且ULIP-2將這種多模態預訓練變得可以不需要任何人工標註,從而可以大規模擴展。
ULIP-2在ModelNet40的下游零樣本分類上取得了顯著的效能提升,達到74.0%的最高準確率;在現實世界的ScanObjectNN基準上,僅用140萬個參數就獲得了91.5%的整體準確率,標誌著在無需人類3D標註的可擴展多模態3D表示學習方面的突破。
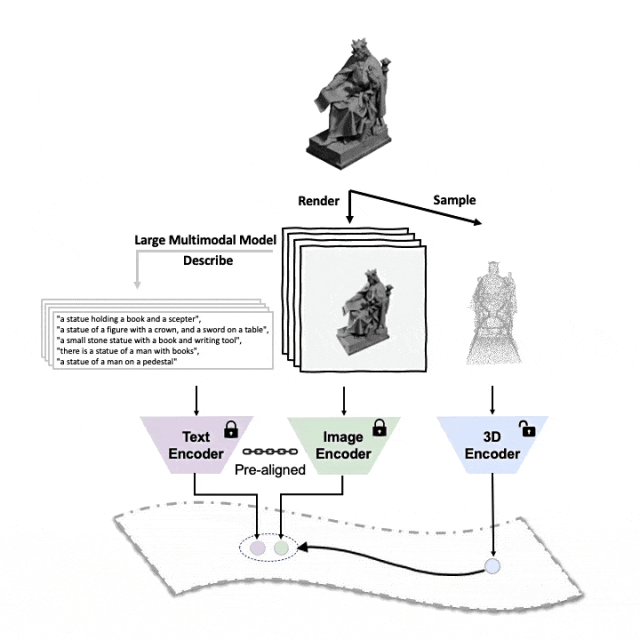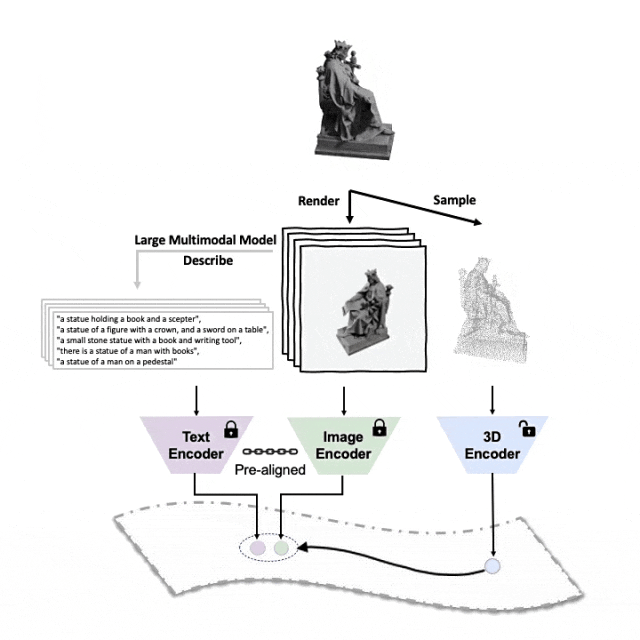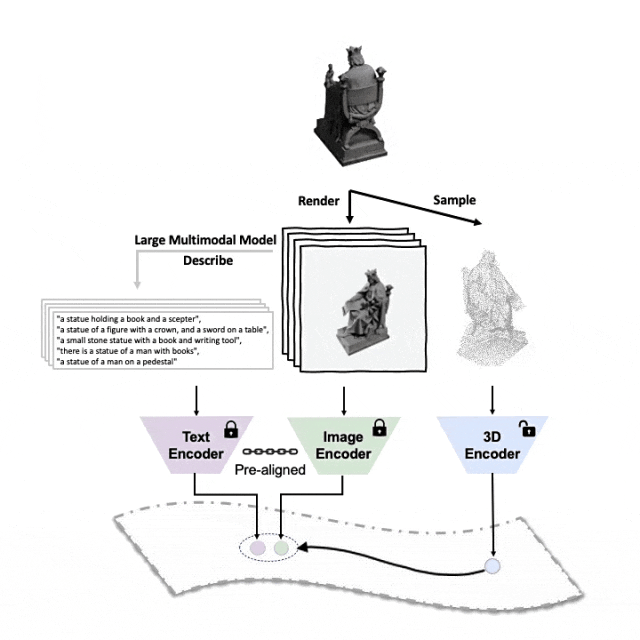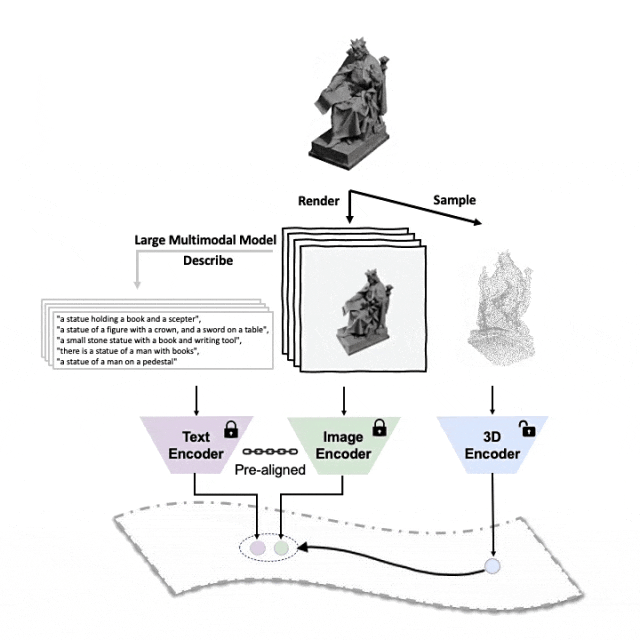
#對準(3D,影像,文字)這三種特徵的預訓練框架示意圖
程式碼以及發布的大規模tri-modal的資料集(“ULIP - Objaverse Triplets”和“ULIP - ShapeNet Triplets”)已經開源。
背景
3D理解是人工智慧領域的重要組成部分,它讓機器能像人類一樣在三維空間中感知和互動。這種能力在自動駕駛汽車、機器人、虛擬實境和擴增實境等領域都有著重要的應用。
然而,由於3D資料的處理和解釋複雜性,以及收集和註釋3D資料的成本,3D理解一直面臨著巨大的挑戰。
ULIP
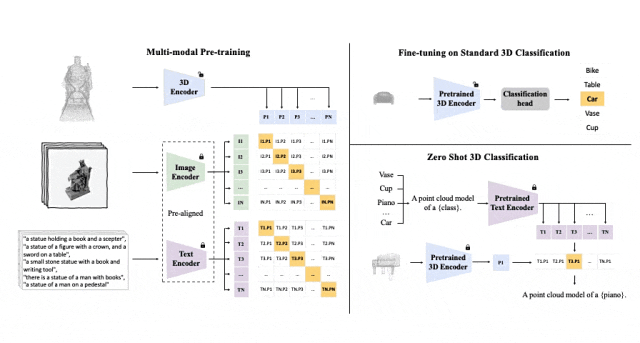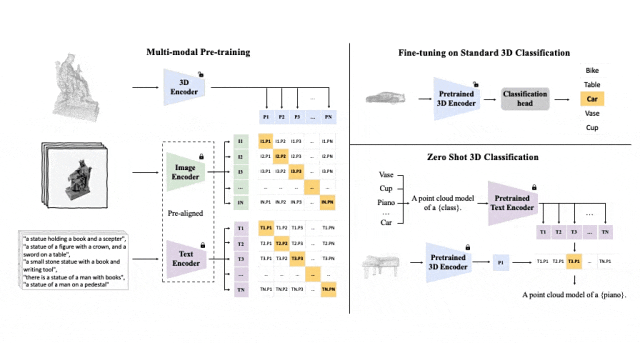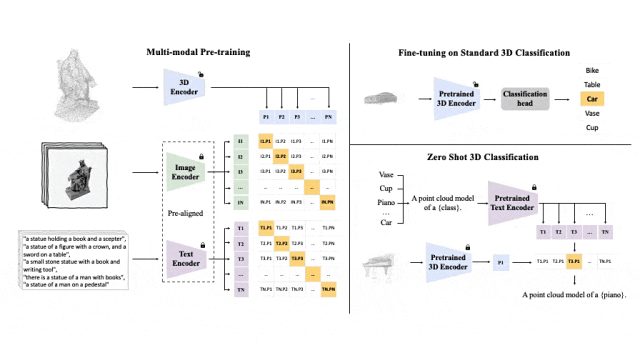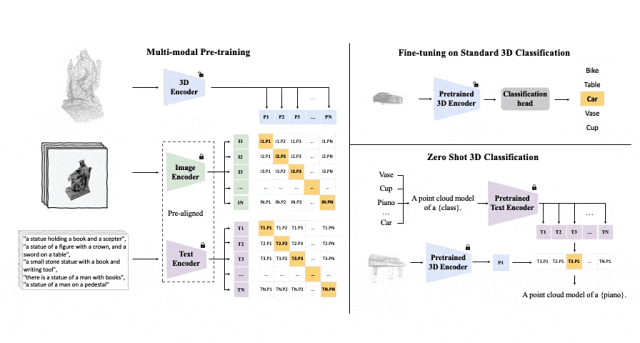
#Tri-modal 預訓練框架以及其下游任務
ULIP(已經被CVPR2023接收)採用了一種獨特的方法,使用3D點雲、圖像和文字進行模型的預訓練,將它們對齊到一個統一的表示空間。
這種方法在3D分類任務中取得了最先進的結果,並為跨領域任務(如圖像到3D檢索)開闢了新的可能性。
ULIP的成功關鍵在於使用預先對齊的圖像和文字編碼器,例如CLIP,它在大量的圖像-文字對上進行預訓練。
這些編碼器將三種模態的特徵對齊到一個統一的表示空間,使模型更有效地理解和分類3D物件。
這種改進的3D表示學習不僅增強了模型對3D資料的理解,也使得跨模態應用如zero-shot 3D分類和影像到3D檢索成為可能,因為3D編碼器獲得了多模態上下文。
ULIP的預訓練損失函數如下:
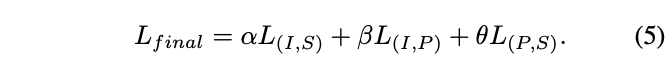
#在ULIP的預設設定中,α被設定為0, β和θ設定為1,每兩個模態之間的比較學習損失函數的定義如下,這裡M1和M2指三個模態中的任兩個模態:
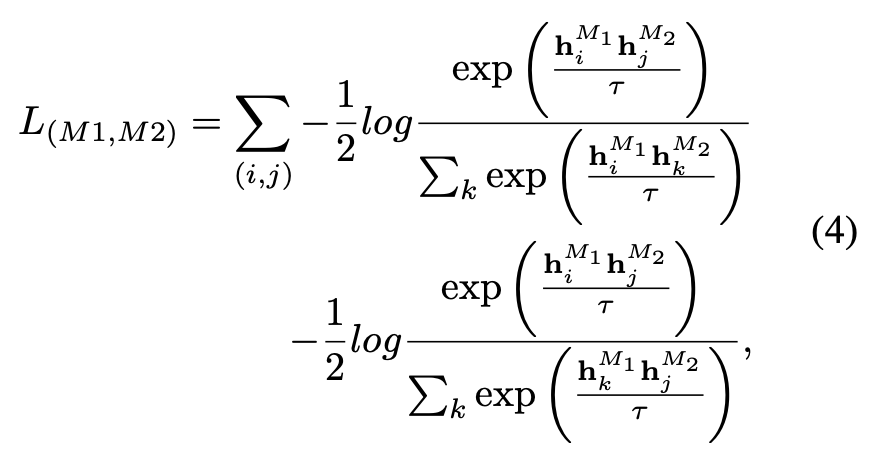
ULIP也做了由影像到3D的retrieval的實驗,效果如下:

實驗結果可以看出ULIP預訓練的模型已經能夠學習到影像和三維點雲間有意義的多模態特徵。
令人驚訝的是,相較於其他的檢索到的三維模型,第一名檢索到的三維模型與查詢影像的外觀最為接近。
例如,當我們使用來自不同飛機類型(戰鬥機和客機)的圖片進行檢索(第二行和第三行),檢索到的最接近的3D點雲仍然保留了查詢圖像的微妙差異。
ULIP-2
#這裡有一個3D物件產生多角度文字描述的範例。我們先將3D物件以一組視角渲染成2D影像,接著使用大型多模態模型為所產生的所有影像產生描述
##ULIP-2在ULIP的基礎上,利用大型多模態模型為3D物件產生全方面對應的語言描述,從而收集可擴展的多模態預訓練數據,無需任何人工標註,使預訓練過程和訓練後的模型更加高效並且增強其適應性。
ULIP-2的方法包括為每個3D物件產生多角度不同的語言描述,然後用這些描述來訓練模型,使3D物件、2D圖像、和語言描述在特徵空間對齊一致。
這個框架使得無需手動註解即可建立大量的三模態資料集,從而充分發揮多模態預訓練的潛力。
ULIP-2也發布了產生的大規模三模態資料集:「ULIP - Objaverse Triplets」和「ULIP - ShapeNet Triplets」。

兩個tri-modal的datasets的一些統計資料
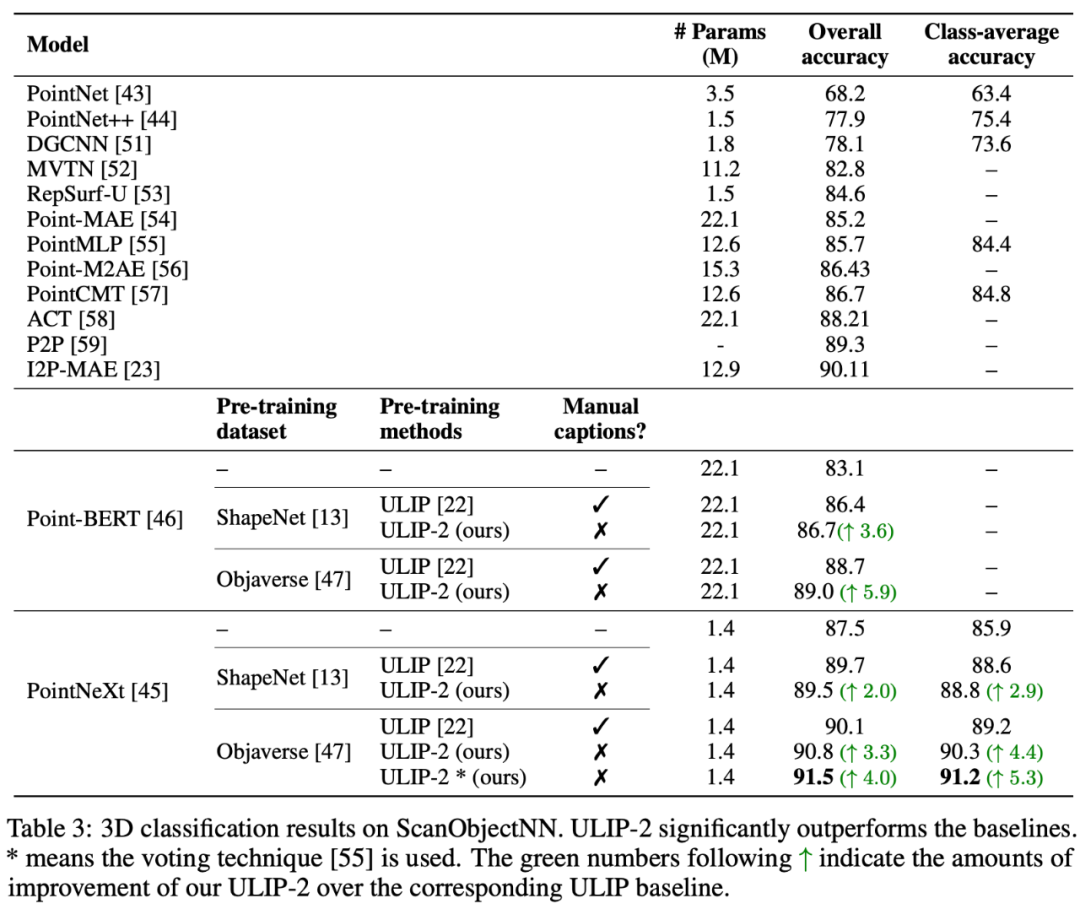
實驗結果ULIP系列在多模態下游任務和3D表達的微調實驗中均取得了驚人的效果,尤其ULIP-2中的預訓練是完全不需要藉助任何人工的標註就可以實現的。
ULIP-2在ModelNet40的下游零樣本分類任務中取得了顯著的提升(74.0%的top-1準確率);在真實世界的ScanObjectNN基準測試中,它僅用1.4M參數就取得了91.5%的整體準確率,這標誌著在無需人工3D標註的情況下,實現了可擴展的多模態3D表示學習的突破。
兩篇論文都做了詳盡的消融實驗。
在「ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding」中,由於ULIP的預訓練框架有三個模態的參與,所以作者用實驗探究了究竟是只對齊其中的兩個模態好還是對齊所有三個模態好,實驗結果如下:
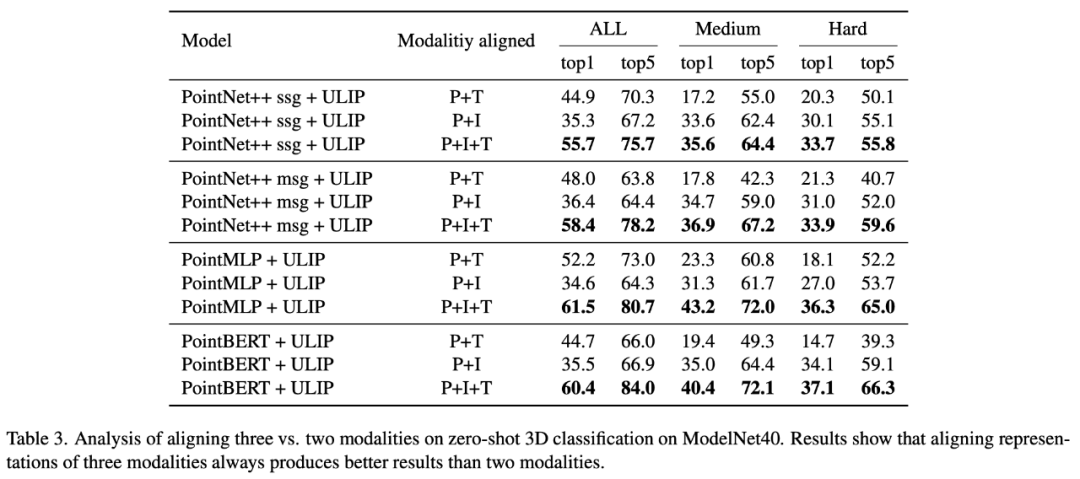
#從實驗結果可以看到,在不同的3D backbone中,對齊三個模態一致的比只對齊兩個模態好,這也應證了ULIP的預訓練框架的合理性。
在「ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding」中,作者探討了不同的大型多模態模型會對預訓練的框架有什麼影響,結果如下:
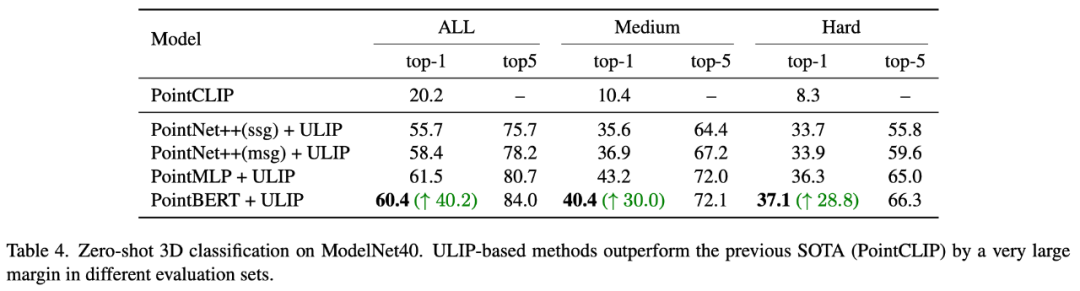
實驗結果可以看出,ULIP-2框架預訓練的效果可以隨著所使用的大型多模態模型的升級而提升,具有一定的成長性。
在ULIP-2中,作者也探討了在產生tri-modal的資料集是採用不同數量的視角會如何影響整體預訓練的表現,實驗結果如下:
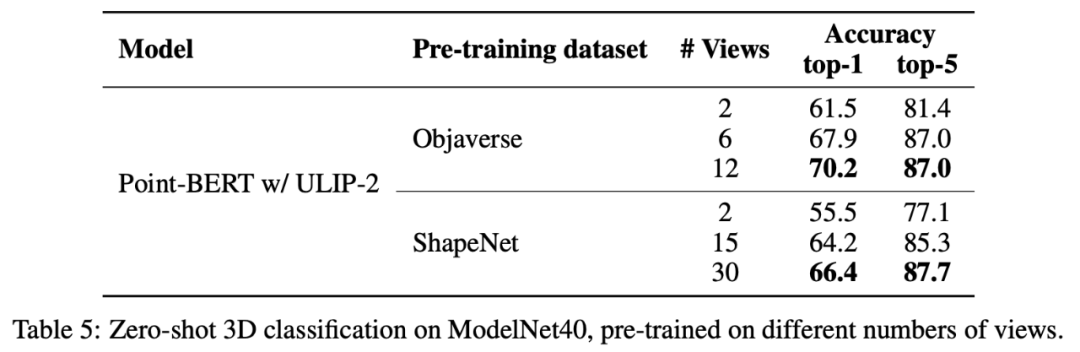
實驗結果顯示,隨著所使用的視角數量的增加,預先訓練的模型的zero-shot classification的效果也會隨之增加。
這也應證了ULIP-2中的觀點,更全方位多樣性的語言描述會對多模態預訓練有正向的作用。
除此之外,ULIP-2也探討了取CLIP排序過的不同topk的語言描述會對多模態預訓練有什麼影響,實驗結果如下:
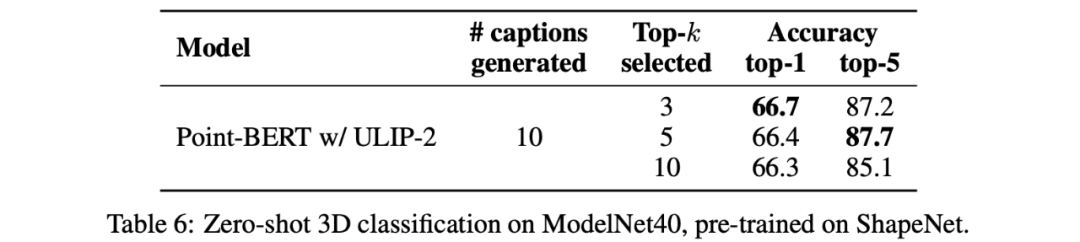
實驗結果顯示:ULIP-2的框架對不同的topk有一定的穩健性,論文中採用了top 5作為預設值。
結論
由Salesforce AI,史丹佛大學,德州大學奧斯汀分校聯手發布的ULIP計畫(CVPR2023)和ULIP-2正在改變3D理解領域。
ULIP將不同的模態對齊到一個統一的空間,增強了3D特徵的學習並啟用了跨模態應用。
ULIP-2進一步發展,為3D物件產生整體語言描述,創建並開源了大量的三模態資料集,並且這個過程無需人工標註。
這些項目在3D理解方面設定了新的基準,為機器真正理解我們三維世界的未來鋪平了道路。
團隊
Salesforce AI:
#Le Xue (薛樂), Mingfei Gao (高明菲),Chen Xing (星星),Ning Yu(於寧), Shu Zhang(張澍),Junnan Li(李俊男), Caiming Xiong(熊蔡明),Ran Xu(徐然),Juan carlos niebles,Silvio savarese。
史丹佛大學:
Prof. Silvio Savarese, Prof. Juan Carlos Niebles, Prof. Jiajun Wu(吳佳俊)。
UT Austin:
Prof. Roberto Martín-Martín。
以上是無需標註數據,「3D理解」進入多模態預訓練時代! ULIP系列全面開源,刷新SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!