
自己動手使用AI技術實現數位內容生產

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-15 19:03:111731瀏覽

背景
今年以來以chatgpt為代表的大模型的驚艷表現徹底點燃了AICG這個領域的。各類gpt,各種AI作圖產品如雨後春筍般出現。每個成功產品的背後都是一個個精妙的演算法,這篇文章給大家詳細介紹下如何使用一個手機拍攝若干張同一場景的照片,然後合成新視角,生成影片的流程與程式碼。本文所使用的技術是NeRF(Neural Radiance Fields),它是2020年以來出現的一種基於深度學習的3D重建方法,它通過學習場景的光線傳輸和輻射傳遞,能夠生成高質量的場景渲染影像和3D模型。關於它的原理與文獻,我在最後有一個參考清單供大家學習。本文主要從程式碼使用以及環境建構的新角度介紹它。
環境搭建
environment.yml修改
#本文所使用的硬體環境是 GPU RTX3090,作業系統是windows 10.採用的軟體是開源的NeRF實作(https://github.com/cjw531/nerf_tf2)。由於RTX 3090需要CUDA 11.0以上版本的支持,TensorFlow-gpu 需要2.4.0以及以上的支持,所以我們沒有選擇官方的https://github.com/bmild/nerf,因為bmild這個的環境使用的tensorflow -gpu==1.15,版本太久了。跑起來會有下面的問題https://github.com/bmild/nerf/issues/174#issue-1553410900,我在這個tt中也回復指出了需要升級到2.8。但就算是使用https://github.com/cjw531/nerf_tf2,它的環境也是有點問題。首先由於它連接的國外的conda的channel,所以速度很慢。其次它的環境使用的是tensorflow==2.8沒有指明tensorflow-gpu的版本。針對這兩個問題。我們對environment.yml進行了修改。
# To run: conda env create -f environment.ymlname: nerf_tf2channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/- conda-forgedependencies:- python=3.7- pip- cudatoolkit=11.0- cudnn=8.0- numpy- matplotlib- imageio- imageio-ffmpeg- configargparse- ipywidgets- tqdm- pip:- tensorflow==2.8- tensorflow-gpu==2.8- protobuf==3.19.0- -i https://pypi.tuna.tsinghua.edu.cn/simple
啟動conda環境
開啟cmd,然後輸入下面的指令。
conda env create -f environment.yml
將nerf_tf2加入jupyter中,這樣使用jupyter能很方便的查看系統的運作結果。
// 安装ipykernelconda install ipykernel
//是该conda环境在jupyter中显示python -m ipykernel install --user --name 环境名称 --python -m ipykernel install --user --name 环境名称 --display-name "jupyter中显示名称"display-name "jupyter中显示名称"
//切换到项目目录cd 到项目目录//激活conda环境activate nerf_tf2//在cmd启动jupyterjupyter notebook
至此conda環境以及jupyter準備就緒。
資料準備
- 下載並安裝colmap,我的環境是windows(https://demuc.de/colmap/#download)
- 使用https: //github.com/fyusion/llff提供的imgs2poses.py實現自己相機拍攝的圖片的相機內外參數的獲取,例如我們的拍攝了10張圖片,它們放置的目錄位置很講究,D:/LanJing/AI /LLFF/data/images,也就是說一定要放在images子目錄下面。而你傳入的參數是python imgs2poses.py D:/LanJing/AI/LLFF/data。因為它的程式碼裡面的images_path的寫法是這個樣子(https://github.com/Fyusion/LLFF/blob/master/llff/poses/colmap_wrapper.py#L28)

#手機拍攝的圖片範例
feature_extractor_args = ['colmap', 'feature_extractor','--database_path', os.path.join(basedir, 'database.db'),'--image_path', os.path.join(basedir, 'images'),'--ImageReader.single_camera', '1',# '--SiftExtraction.use_gpu', '0',]
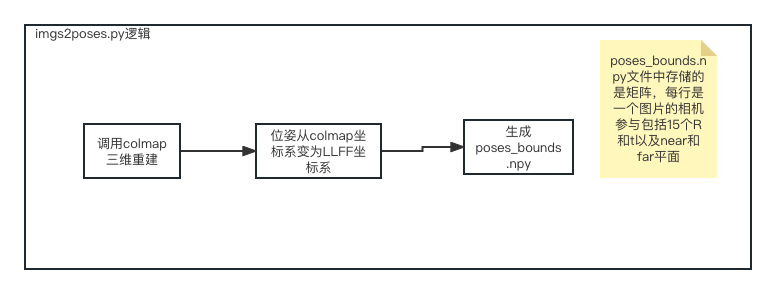
python imgs2poses.py
在運行完後,產生了sparse目錄、colmap_out.txt、database.db、poses_bounds.npy,然後我們在nerf_tf2專案下建立新目錄data/nerf_llff_data/ll,將上面的sparse目錄以及poses_bounds.npy複製到這個目錄下。最後我們再設定個新檔案config_ll.txt。至此我們的資料準備工作完成了。
expname = ll_testbasedir = ./logsdatadir = ./data/nerf_llff_data/lldataset_type = llfffactor = 8llffhold = 8N_rand = 1024N_samples = 64N_importance = 64use_viewdirs = Trueraw_noise_std = 1e0
訓練
將開源軟體遷移到windows平台上。
由於此開源軟體主要是支援mac和linux,它無法在windows運行,需要對load_llff.py的修改。
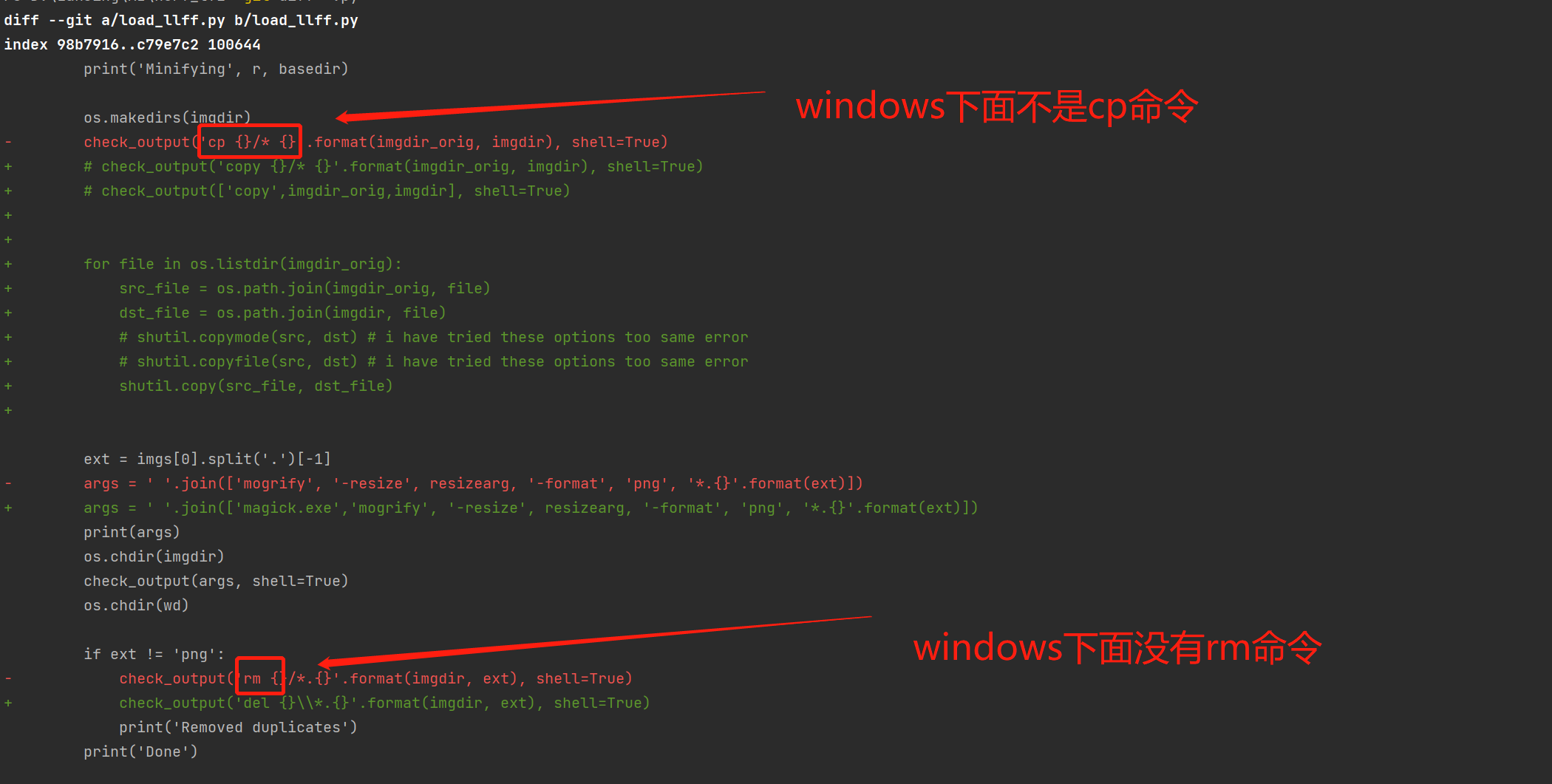
load_llff程式碼遷移
執行300000次批次訓練。
activate nerf_tf2python run_nerf.py --config config_ll.txt
測試
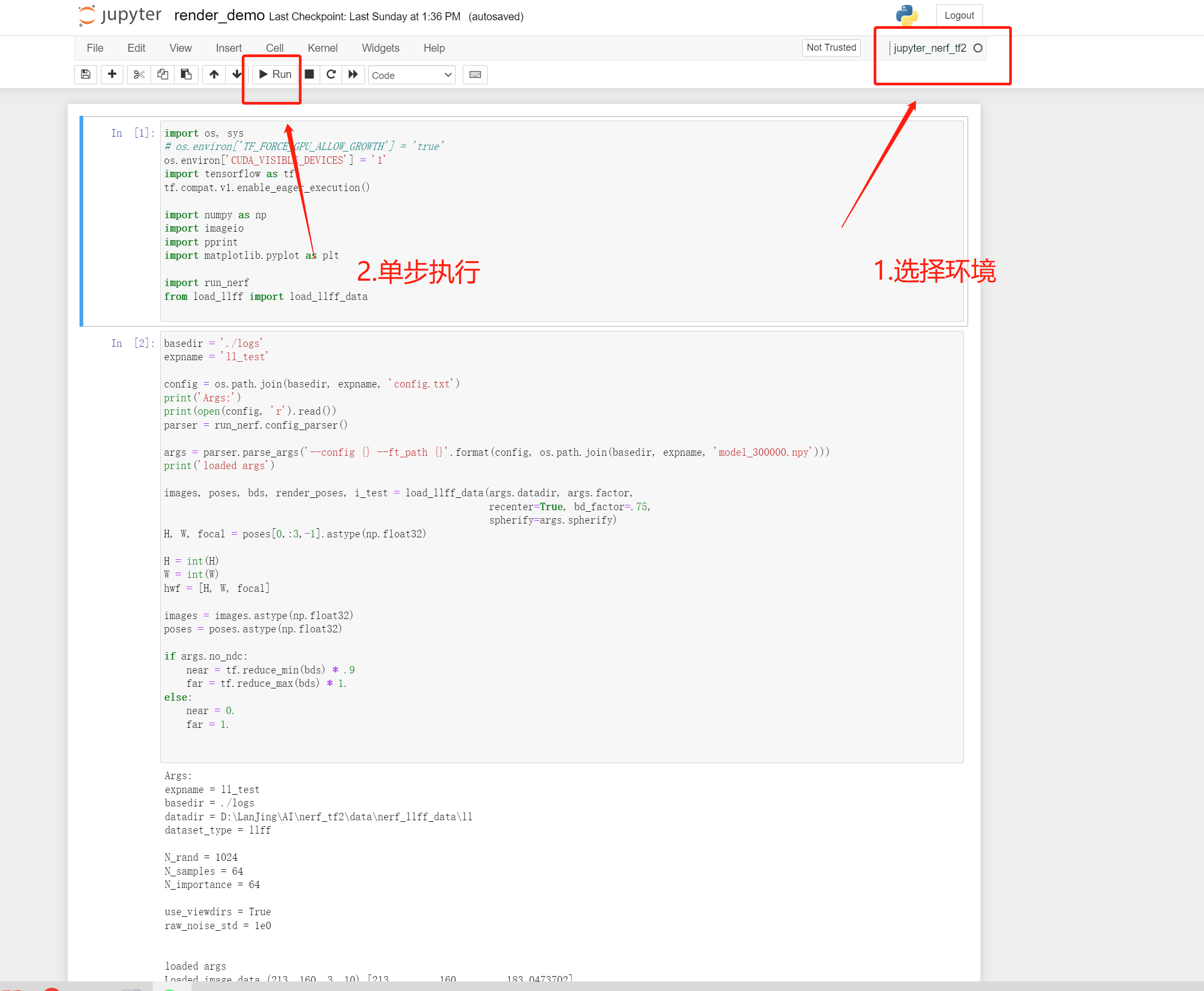
render_demo的運行
效果
由於我們使用的輸入圖片有些少,只有10張,所以運行出來的效果不是很好,但整體的流程是一樣。 tips:官方的程式碼裡面使用的一半都是30,甚至100張圖片。
我們的效果

一個新視角的渲染
官方效果

fern官方合成新視角效果
參考資料
https://zhuanlan.zhihu.com/p/554093703。
https://arxiv.org/pdf/2003.08934.pdf。
https://zhuanlan.zhihu.com/p/593204605。
https://inst.eecs.berkeley.edu/~cs194-26/fa22/Lectures/nerf_lecture1.pdf。
以上是自己動手使用AI技術實現數位內容生產的詳細內容。更多資訊請關注PHP中文網其他相關文章!