


昨天一個跑了220個小時的微調訓練完成了,主要任務是想在CHATGLM-6B上微調出一個能夠較為精確的診斷資料庫錯誤訊息的對話模型來。

#不過這個等了將近十天的訓練最後的結果令人失望,比起我之前做的一個樣本覆蓋更小的訓練來,差的還是挺大的。
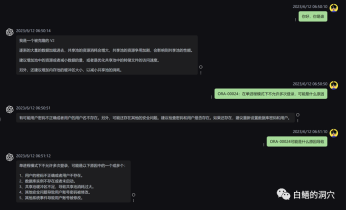
#這樣的結果還是有點令人失望的,這個模型基本上是沒有實用價值的。看樣子需要重新調整參數與訓練集,再做一次訓練。大語言模型的訓練是一場軍備競賽,沒有好的裝備是玩不起來的。看來我們也必須升級一下實驗室的裝備了,否則沒有幾個十天可以浪費。
從最近幾次的失敗的微調訓練來看,微調訓練這條路也不容易完成。不同的任務目標混雜在一起跑訓練,可能不同的任務目標所需的訓練參數不同,使最終的訓練集無法滿足某些任務的需求。因此PTUNING只適合某個十分確定的任務,不一定適合混合任務,以混合任務為目的的模型,可能需要用FINETUNE。這和前幾天我在和朋友交流時大家的觀點類似。
其實因為訓練模型難度比較大,有些人已經放棄了自己訓練模型,而採用將本地知識庫向量化後進行較為精準的檢索,然後透過AUTOPROMPT將檢索後的結果產生自動提示,去問打語音模型。利用langchain很容易達成這個目標。
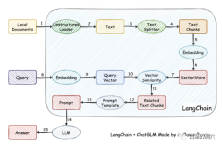
#這個工作的原理是將本機文件透過載入器載入為文本,然後對文字進行切分行程文字片段,經過編碼後寫入向量儲存中功查詢使用。查詢結果出來後,透過Prompt Template自動形成提問用的提示,去詢問LLM,LLM產生最後的回答。
這項工作裡有另一個要點,一個是較為精準的搜尋到本地知識庫中的知識,這個透過向量儲存於搜尋來實現,目前針對中英文的本地知識庫的向量化與搜尋的解決方案很多,可以選擇某個對你的知識庫比較友善的方案來使用。
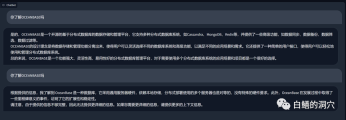
#上面有一個在vicuna-13b上通過關於OB的知識庫進行的問答,上面的是沒有使用本地知識庫,直接使用LLM的能力的回答,下面是加載了本地知識庫後的回答。可以看出性能提升還挺明顯的。

我們再來看看剛才那個ORA錯誤的問題,在沒有使用本地知識庫之前,LLM基本上是胡說八道的,而載入了本地知識庫之後,這個回答還是中規中矩的,文中的錯字也是我們知識庫中的錯誤。實際上PTUNING所使用的訓練集也是透過這個本地知識庫產生出來的。
從最近我們踩過的坑可以收穫一些經驗。首先ptuning的難度比我們想像得高很多,雖然說ptuning比finetune需要的裝備低一點,不過訓練難度一點都不低。其次是透過Langchain和autoprompt利用本地知識庫來改善LLM能力效果不錯,對於大多數企業應用來說,只要把本地知識庫梳理好,選擇合適的向量化方案,應該都能獲得不比PTUNING/FINETUNE差的效果。第三,還是上回說的問題,LLM的能力至關重要。必須選擇一個能力較強的LLM作為基礎模型來使用。任何嵌入式模型都只能局部改善能力,不能扮演決定性的角色。第四,對於資料庫相關的知識,vicuna-13b的能力確實不錯。
今天一大早還要去客戶那邊做個交流,早上時間有限,就簡單寫幾句吧。大家對此有何心得,歡迎留言討論(討論僅你我可見),我也是在這條路上孤獨行走,希望有同路人指點一二。
以上是一篇學會本地知識庫對LLM的效能優化的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

Dreamweaver CS6
視覺化網頁開發工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

