
解密即時通話中基於 AI 的一些語音增強技術

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-10 08:58:231645瀏覽

背景介紹
即時音視訊通訊RTC 在成為人們生活和工作中不可或缺的基礎設施後,其中所涉及的各類技術也在不斷演進以因應處理複雜多場景問題,例如音訊場景中,如何在多裝置、多人、多雜訊場景下,為使用者提供聽得清楚、聽得真的體驗。
作為語音訊號處理研究領域的旗艦國際會議,ICASSP (International Conference on Acoustics, Speech and Signal Processing) 一直代表著聲學領域技術最前沿的研究方向。 ICASSP 2023 收錄了多篇和音訊訊號語音增強演算法相關的文章,其中,火山引擎 RTC 音訊團隊共有 4 篇研究論文被大會接收,論文方向包括特定說話者語音增強、迴聲消除、多通道語音增強、音質修復主題。本文將介紹這 4 篇論文解決的核心場景問題與技術方案,分享火山引擎 RTC 音訊團隊在語音降噪、迴聲消除、幹擾人聲消除領域的思考與實踐。
《基於頻帶分割循環神經網路的特定說話者增強》
論文地址:
https ://www.php.cn/link/73740ea85c4ec25f00f9acbd859f861d
即時特定說話者語音增強任務有許多問題亟待解決。首先,採集聲音的全頻帶寬度提高了模型的處理難度。其次,相較於非即時場景,即時場景下的模型更難定位目標說話人,如何提高說話者嵌入向量和語音增強模型的資訊互動是即時處理的難點。受到人類聽覺注意力的啟發,火山引擎提出了一種引入說話者訊息的說話人注意力模組(Speaker Attentive Module,SAM),並將其和單通道語音增強模型-頻帶分割循環神經網路(Band- split Recurrent Neural Network,BSRNN) 融合,建立特定人語音增強系統來作為迴聲消除模型的後處理模組,並對兩個模型的級聯進行最佳化。
模型框架結構
頻帶分割循環神經網路(BSRNN)

#頻帶分割循環神經網路(Band-split RNN, BSRNN )是全頻帶語音增強和音樂分離的SOTA 模型,其結構如上圖所示。 BSRNN 由三個模組組成,分別是頻帶分割模組(Band-Split Module)、頻帶序列建模模組(Band and Sequence Modeling Module)和頻帶合併模組(Band-Merge Module)。頻帶分割模組先將頻譜分割為 K 個頻帶,每個頻帶的特徵經過批歸一化(BN)後,被 K 個全連接層(FC)壓縮到相同的特徵維度 C 。隨後,所有頻帶的特徵被拼接為一個三維張量並由頻帶序列建模模組進一步處理,該模組使用 GRU 交替建模特徵張量的時間和頻帶維度。經過處理的特徵最後經過頻帶合併模組得到最後的頻譜掩蔽函數作為輸出,將頻譜掩蔽和輸入頻譜相乘即可得到增強語音。為了建立特定說話者的語音增強模型,我們在每個頻帶序列的建模模組後都添加了說話人注意力模組。
說話人注意力機制模組 (SAM)

說話人注意力模組(Speaker Attentive Module)的結構如上圖。其核心思想是使用說話者嵌入向量e 作為語音增強模型中間特徵的吸引子,計算其和中間特徵所有時間和頻帶上的相關度s,稱為注意力值。此註意力值將被用於對中間特徵 h 進行縮放規則。其具體公式如下:
首先透過全連接和卷積將e 和h 轉換為k 和q:
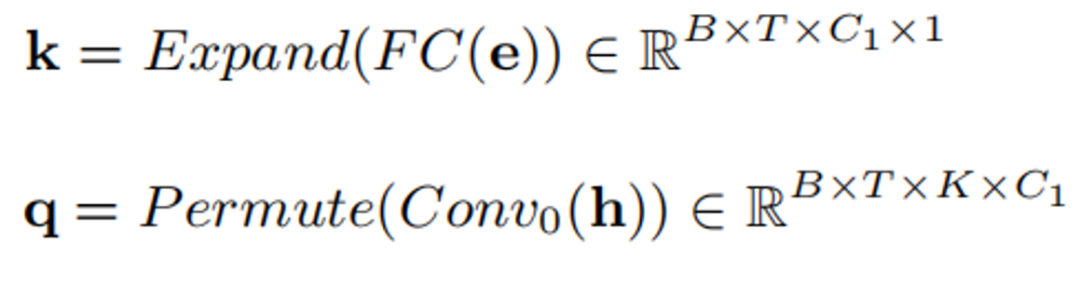
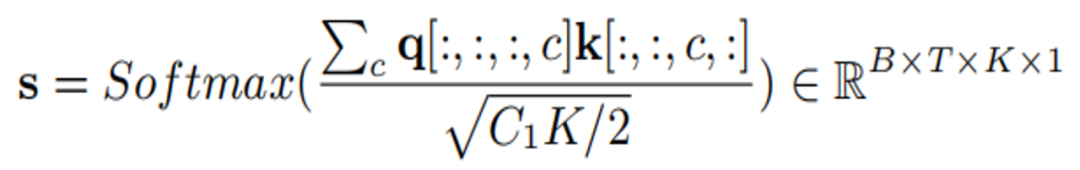
模型訓練數據
關於模型訓練數據,我們採用了第五屆DNS 特定說話人語音增強賽道的數據以及DiDispeech 的高質量語音數據,通過數據清洗,得到約3500 個說話人的清晰語音數據。在資料清洗方面,我們使用了基於ECAPA-TDNN[1]說話者辨識的預訓練模型來去除語音資料中殘留的干擾說話者語音,同時使用第四屆DNS 挑戰賽第一名的預訓練模型來去除語音資料中的殘留噪音。在訓練階段,我們產生了超過10 萬條4s 的語音數據,對這些音頻添加混響以模擬不同信道,並隨機和噪聲、幹擾人聲混合,設置成一種噪聲、兩種噪聲、噪聲和乾擾說話人以及僅有乾擾說話者4 種幹擾場景。同時,含噪語音和目標語音的電平將隨機縮放,以便模擬不同大小的輸入。
《融合特定說話者提取與迴聲消除技術方案》
論文地址:
https: //www.php.cn/link/7c7077ca5231fd6ad758b9d49a2a1eeb
迴聲消除一直是外放場景中一個極其複雜且至關重要的問題。為了能夠提取出高品質的近端乾淨語音訊號,火山引擎提出了一種結合訊號處理與深度學習技術的輕量化迴聲消除系統。在特定說話者降噪(Personalized Deep Noise Suppression, pDNS ) 基礎上,我們進一步建構了特定說話者迴聲消除(Personalized Acoustic Echo Cancellation, pAEC)系統,其包括一個基於數位訊號處理的前處理模組、一個基於深度神經網路的兩階段模型和一個基於BSRNN 和SAM 的特定說話者語音擷取模組。

特定說話人迴聲消除總體框架
基於數位訊號處理線性迴聲消除的前處理模組
前處理模組主要包含兩部分:時延補償(TDC)和線性迴聲消除(LAEC),該模組均在子帶特徵上進行。

基於訊號處理子帶線性迴聲消除演算法框架
時延補償
TDC 基於子帶互相關,其首先分別在每個子帶中估計出一個時延,然後使用投票方法來確定最終時間延遲。
線性迴聲消除
LAEC 是一種基於NLMS 的子帶自適應濾波器方法,由兩個濾波器組成:前置濾波器(Pre-filter)和後置濾波器(Post-filter),後置濾波器使用動態步長進行自適應更新參數,前置濾波器是狀態穩定的後置濾波器的備份。根據前置濾波器和後置濾波器輸出的殘餘能量進行比較,最終決定選用哪一個誤差訊號。

LAEC 處理流程圖
基於多層次卷積-循環卷積神經網路(CRN )的兩階段模型
我們建議將pAEC 任務進行解耦,拆分成「迴聲抑制」和「特定說話者提取」兩個任務,以減輕模型建模壓力。因此,後處理網路主要由兩個神經網路模組組成:用於初步迴聲消除和噪音抑制的基於CRN 的輕量級模組,以及用於更好的近端語音訊號重建的基於pDNS 的後處理模組。
第一階段:基於CRN的輕量級模組
基於CRN 的輕量級模組由一個頻帶壓縮模組、一個編碼器、兩個雙路徑GRU、一個解碼器和一個頻帶分解模組組成。同時,我們也引入了一個語音活動偵測(Voice Activity Detection, VAD)模組用於多任務學習,有助於提高對近端語音的感知。 CRN 取壓縮幅度為輸入,輸出初步的目標訊號的複數理想比掩碼(cIRM)和近場 VAD 機率。
第二階段:基於pDNS的後處理模組
這個階段的pDNS 模組包含了上述介紹的頻帶分割循環神經網路BSRNN 和說話者註意力機制模組SAM,級聯模組以串聯的方式接在輕量級CRN 模組之後。由於我們的 pDNS 系統在特性說話者語音增強任務上達到了較為優異的性能,我們將一個預先訓練好的 pDNS 模型參數作為模型的第二階段初始化參數,對前一階段的輸出進一步處理。
級聯繫統訓練優化損失函數
我們透過級聯優化的方式來改進兩階段模型,使其在第一階段能夠預測近端語音,在第二階段能夠預測特定說話人的近端語音。我們也加入了一個靠近說話者的語音活動偵測罰項,以增強模型對近距離說話的辨識能力。具體損失函數定義如下:

其中,
分別對應模型第一階段和第二階段預測的STFT 特徵, 分別表示近端語音和近端特定說話人語音的STFT 特徵,
分別表示模型預測和目標VAD 狀態。
模型訓練資料
為了讓迴聲消除系統可以處理多設備,多混響,多噪音擷取場景的迴聲,我們透過混合迴聲和乾淨語音,得到2000 小時的訓練數據,其中,迴聲數據使用AEC Challenge 2023 遠端單講數據,乾淨語音來自DNS Challenge 2023 和LibriSpeech,用於模擬近端混響的RIR 集合來自DNS Challenge。由於AEC Challenge 2023 遠端單講數據中的迴聲存在少量噪音數據,直接使用這些數據作為迴聲容易導致近端語音失真,為了緩解這個問題,我們採用了一種簡單但有效的數據清理策略,使用預訓練的一個AEC 模型處理遠端單講數據,將具有較高殘餘能量的數據識別為噪音數據,並反覆迭代下圖清洗流程。
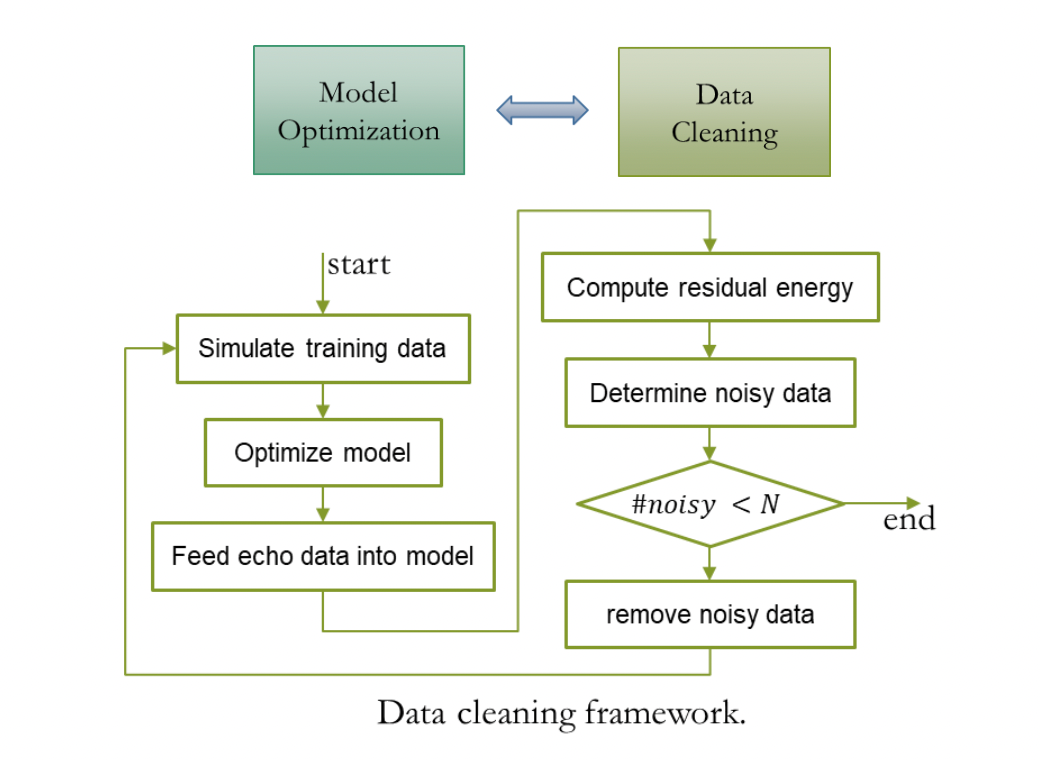
級聯優化方案系統效果
這樣的一套基於融合迴聲消除與特定說話者提取的語音增強系統在ICASSP 2023 AEC Challenge 盲測試集[2] 上驗證了它在主客觀指標上的優勢-取得了4.44 的主觀意見分(Subjective-MOS)和82.2%的語音辨識準確率(WAcc)。

《基於傅立葉卷積注意力機制的多通道語音增強》
論文網址:
https://www.php.cn/link/373cb8cd58cad5f1309b31c56e2d5a83

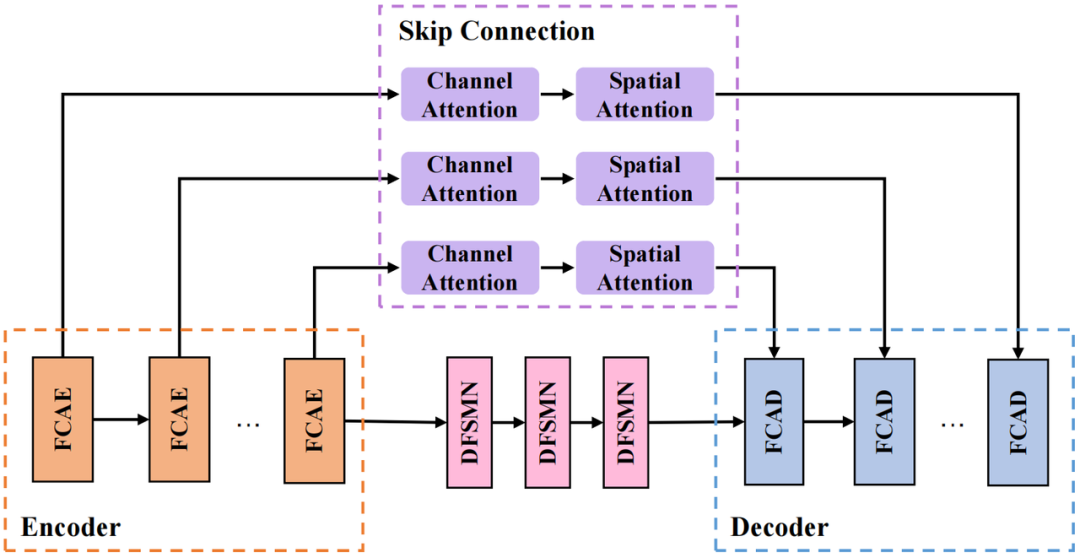
我們採用的 CRED 結構如上圖所示。其中,FCAE 為傅立葉卷積注意力編碼器,FCAD 為與FCAE 對稱的解碼器;循環模組採用深度前饋順序記憶網路(Deep Feedward Sequential Memory Network,DFSMN)對序列的時序依賴進行建模,在不影響模型性能的基礎上減小模型尺寸;跳連接部分採用串聯的通道注意力(Channel Attention)和空間注意力(Spatial Attention)模組,用來進一步提取跨通道間的空間信息,並連接深層特徵與淺層特徵,方便資訊在網路中的傳輸。
FCAE結構
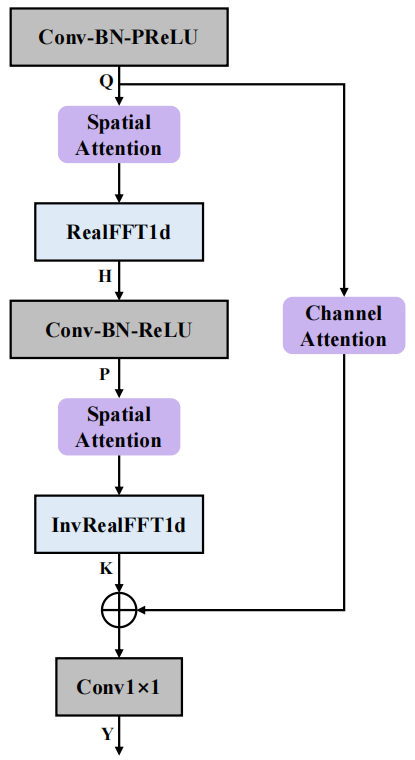
#傅立葉卷積注意力編碼器(FCAE)的結構如上圖所示。此模組受傅立葉卷積算子[3]的啟發,利用離散傅立葉變換在變換域上的任意一點的更新將對原始域的訊號產生全局影響的特點,對頻率軸特徵進行一維FFT 變換,即可在頻率軸上獲得全局感受野,進而加強對頻率軸上下文特徵的提取。此外,我們引入了空間注意力模組和通道注意力模組,進一步增強卷積表達能力,提取有利的頻譜-空間聯合訊息,增強網路對純淨語音和噪音可區分特徵的學習。在最終表現上,該網路以僅 0.74M 的參數量取得了優異的多通道語音增強效果。
模型訓練資料
資料集方面,我們採用了ConferencingSpeech 2021 比賽提供的開源資料集,純淨語音資料包含AISHELL-1、AISHELL-3、VCTK 以及LibriSpeech(train-clean -360),挑選其中訊號雜訊比大於15dB 的資料用於產生多通道混合語音,雜訊資料集採用MUSAN、AudioSet。同時,為了模擬實際多房間混響場景,透過模擬改變房間尺寸、殘響時間、發聲源,噪音源位置等方式將開源的資料與超過5,000 個房間脈衝響應進行卷積,最終產生6 萬條以上多通道訓練樣本。
《基於兩階段神經網路模型的音質修復系統》
論文地址:
https: //www.php.cn/link/e614f646836aaed9f89ce58e837e2310
火山引擎在音質修復方面也進行了一些嘗試,包括增強特定說話者的語音、消除迴聲和增強多通道音訊。在即時通訊過程中,出現的不同形式的失真都會對語音訊號的品質產生影響,導致語音訊號的清晰度和可理解性下降。火山引擎提出了一個兩階段模型,該模型採用分階段的分治策略,以修復各種影響語音品質的失真。
模型框架結構
下圖為兩階段模型整體框架構圖,其中,第一階段模型主要修復頻譜缺失的部分,第二階段模型則主要抑制雜訊、混響以及第一階段模型可能產生的偽影。

第一階段模型:Repairing Net
整體採用深度複數卷積循環神經網路(Deep Complex Convolution Recurrent Network, DCCRN)[4]架構,包括Encoder、時序建模模組和Decoder 三個部分。受影像修復的啟發,我們引入了 Gate 複值卷積和 Gate 複值轉置卷積代替 Encoder 和 Decoder 中的複值卷積和復值轉置卷積。為了進一步提升音訊修補部分的自然度,我們引入了 Multi-Period Discriminator和 Multi-Scale Discriminator 用於輔助訓練。
第二階段模型:Denoising Net
整體採用S-DCCRN 架構,包括Encoder、兩個輕量級DCCRN 子模組和Decoder 三個部分,其中兩個輕量級DCCRN子模組分別進行子帶和全帶建模。為了提升模型在時域建模上的能力,我們將 DCCRN子 模組中的 LSTM 替換為 Squeezed Temporal Convolutional Module(STCM)。
模型訓練資料
這裡用來訓練來音質修復的乾淨音訊、雜訊、殘響皆來自2023 DNS 競賽資料集,其中乾淨音訊總時長為750 小時,雜訊總時長為170 小時。在第一階段模型的資料增廣時,我們一方面利用全帶音頻與隨機生成的濾波器進行卷積, 20ms 為窗長將音頻採樣點隨機置零和對音頻隨機進行降採樣來模擬頻譜缺失缺陷,另一方面在音頻幅度頻與音頻採集點上分別乘以隨機尺度;在第二階段的數據增廣時,我們利用第一階段已經產生的數據,再卷積各種類型的房間沖激響應得到不同殘響程度的音訊資料。
音频处理效果
在 ICASSP 2023 AEC Challenge中,火山引擎 RTC 音频团队,在通用回声消除 (Non-personalized AEC) 与特定说话人回声消除 (Personalized AEC) 两个赛道上荣获冠军,并在双讲回声抑制,双讲近端语音保护、近端单讲背景噪声抑制、综合主观音频质量打分及最终语音识别准确率等多项指标上显著优于其他参赛队伍,达到国际领先水平。
我们来看一下经过上述技术方案后,火山引擎 RTC 在不同场景下的语音增强处理效果。
不同信噪回声比场景下的回声消除
下面两个例子分别展示了回声消除算法在不同信号回声能量比例场景下处理前后的对比效果。
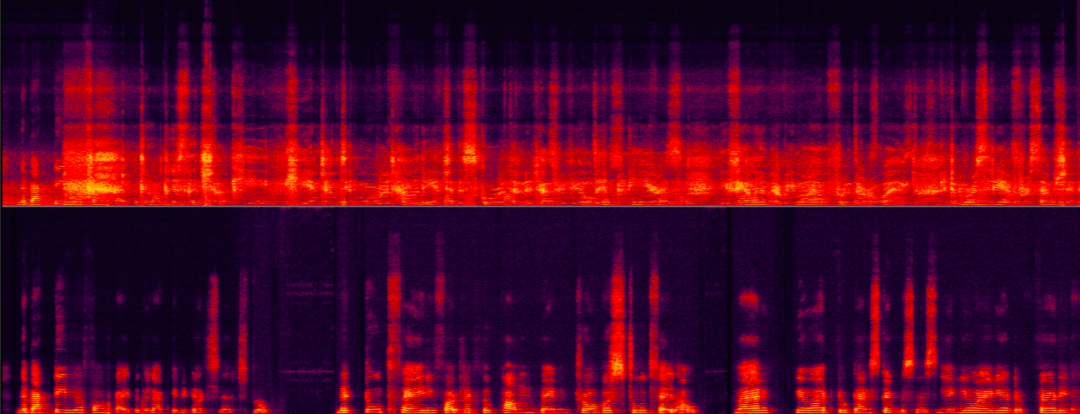
中等信回声比场景
超低信回比场景对回声消除的挑战性最大,此时我们不仅需要有效去除大能量的回声,还需要同时最大程度保留微弱的目标语音。非目标说话人语音(回声)几乎完全盖过了目标说话人(女声)的语音,使其难以识别。
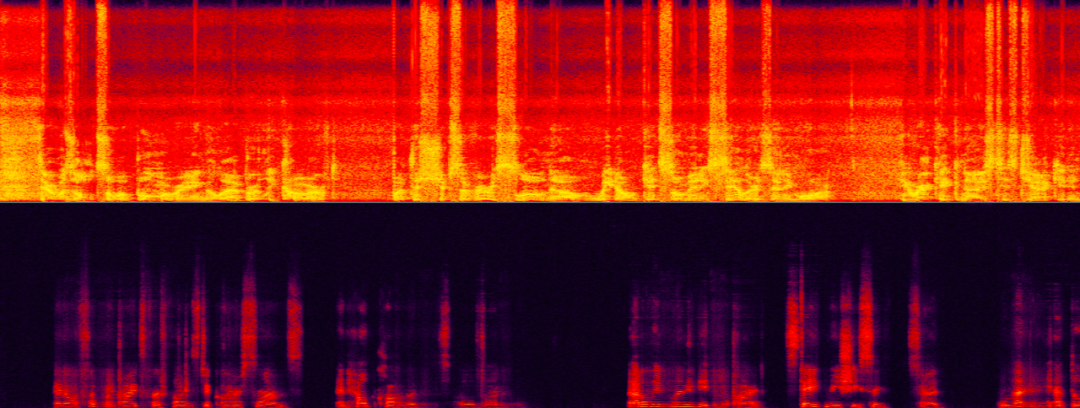
超低信回声比场景
不同背景干扰说话人场景下的说话人提取
下面两个例子分别展示了特定说话人提取算法在噪音与背景人干扰场景下处理前后的对比效果。
如下样本中,特定说话人既有类似门铃的噪声干扰,又有背景人说话噪声干扰,仅使用 AI 降噪只能去除门铃噪声,因此还需要针对特定说话人进行人声消除。
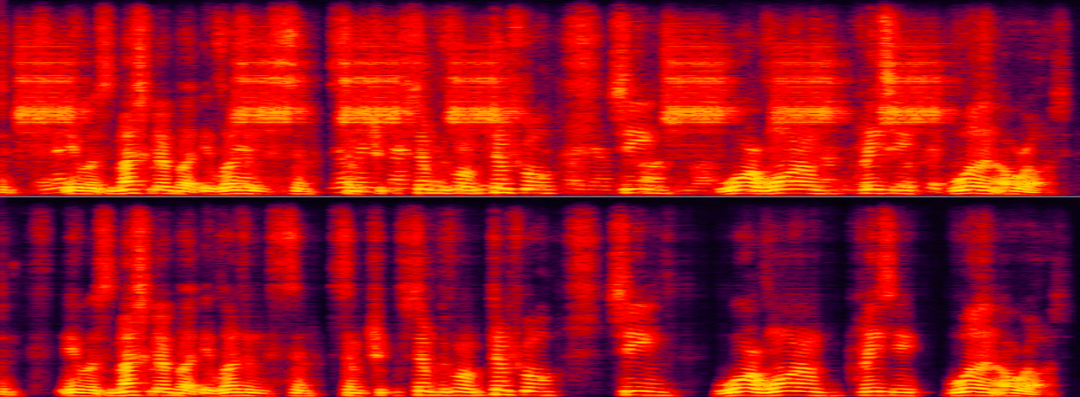
目标说话人与背景干扰人声及噪音
当目标说话人声和背景干扰人声的声纹特征很接近时,此时对于特定说话人提取算法的挑战更大,更能考验特定说话人提取算法鲁棒性。如下样本中,目标说话人和背景干扰人声是两个相似的女声。

目标女声与干扰女声混合
总结与展望
上述介绍了火山引擎 RTC 音频团队基于深度学习在特定说话人降噪,回声消除,多通道语音增强等方向做出的一些方案及效果,未来场景依然面临着多个方向的挑战,如语音降噪如何自适应噪音场景,音质修复如何在更广范围对音频信号进行多类型修复以及怎么样各类终端上运行轻量低复杂度模型,这些挑战点也将会是我们后续重点的研究方向。
以上是解密即時通話中基於 AI 的一些語音增強技術的詳細內容。更多資訊請關注PHP中文網其他相關文章!