
三維場景產生:無需任何神經網路訓練,從單一範例產生多元結果

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-06-09 20:22:03844瀏覽

多樣高質的三維場景產生結果
- ##論文網址: https://arxiv.org/abs/2304.12670
- 專案首頁:http://weiyuli.xyz/Sin3DGen/
使用人工智慧輔助內容生成(AIGC)在圖像生成領域湧現出大量的工作,從早期的變分自編碼器(VAE),到生成對抗網路(GAN),再到最近大紅大紫的擴散模型(Diffusion Model),模型的生成能力飛速提升。以 Stable Diffusion,Midjourney 等為代表的模型在產生具有高真實感影像方面取得了前所未有的成果。同時,在影片生成領域,最近也湧現出許多優秀的工作,如 Runway 公司的生成模型能夠產生充滿想像力的影片片段。這些應用程式大大降低了內容創作門檻,使得每個人都可以輕易地將自己天馬行空的想法變成現實。
但是隨著承載內容的媒介越來越豐富,人們漸漸不滿足於圖文、影片這些二維的圖形影像內容。隨著互動式電子遊戲技術的不斷發展,特別是虛擬和擴增實境等應用的逐步成熟,人們越來越希望能身臨其境地從三維視角與場景和物體進行互動,這帶來了對三維內容生成的更大訴求。
如何快速地產生高品質且具有精細幾何結構和高度真實感外觀的三維內容,一直以來都是電腦圖形社群研究者們重點探索的問題。透過電腦智慧地進行三維內容生成,在實際生產應用中可以輔助遊戲、影視製作中重要數位資產的生產,大大減少了美術製作人員的開發時間,大幅降低資產獲取成本,並縮短整體的製作週期,也為使用者帶來千人千面的個人化視覺體驗提供了技術可能。而對於一般使用者來說,快速又方便的立體內容創作工具的出現,結合如桌上型三維印表機等應用,未來將為一般消費者的文娛生活帶來更無限的想像空間。
目前,雖然普通用戶可以透過便攜式相機等設備輕鬆地創建圖像和視頻等二維內容,甚至可以對三維場景進行建模掃描,但總體來說,高品質三維內容的創作往往需要有經驗的專業人員使用如3ds Max、Maya、Blender 等軟體手動建模和渲染,但這些有很高的學習成本和陡峭的成長曲線。
其中一大主要原因是,三維內容的表達十分複雜,如幾何模型、紋理貼圖或角色骨骼動畫等。即使就幾何表達而言,就可以有點雲、體素和網格等多種形式。三維表達的複雜性極大地限制了後續資料收集和演算法設計。
另一方面,三維資料自然具有稀缺性,資料擷取的成本高昂,往往需要昂貴的設備和複雜的擷取流程,且難以大量收集某種統一格式的三維數據。這使得大多數資料驅動的深度生成模型難有用武之地。
在演算法層面,如何將收集到的三維資料送入計算模型,也是難以解決的問題。三維資料處理的算力開銷,比二維資料有著指數級的成長。暴力地將二維生成演算法拓展到三維,即使是最先進的平行計算處理器也難以在可接受的時間內處理。
上述原因導致了目前三維內容產生的工作大多只限於某一特定類別或只能產生較低解析度的內容,難以應用於真實的生產流程。
為了解決上述問題,北京大學陳寶權團隊聯合山東大學和騰訊AI Lab 的研究人員,提出了首個基於單樣例場景無需訓練便可產生多樣高品質三維場景的方法。演算法具有以下優點:
1,無需大規模的同類訓練資料和長時間的訓練,僅使用單一樣本便可快速產生高品質三維場景;
2,使用了基於神經輻射場的 Plenoxels 作為三維表達,場景具有高真實感外觀,能渲染出照片般真實的多視角圖片。生成的場景也完美的保留了樣本中的所有特徵,如水面的反光隨視角變化的效果等;
3,支持多種應用製作場景,如三維場景的編輯、尺寸重定向、場景結構類比和更換場景外觀等。
方法介紹
研究人員提出了一個多尺度的漸進式產生框架,如下圖所示。演算法核心思想是將樣本場景拆散為多個區塊,透過引入高斯噪聲,然後以類似拼積木的方式將其重新組合成類似的新場景。
作者使用座標映射場這種和樣本異構的表達來表示生成的場景,使得高品質的生成變得可行。為了讓演算法的最佳化過程更加穩健,該研究還提出了一種基於值和座標混合的最佳化方法。同時,為了解決三維計算的大量資源消耗問題,研究使用了精確到近似的最佳化策略,使得能在沒有任何訓練的情況下,在分鐘級的時間產生高品質的新場景。更多的技術細節請參考原始論文。
隨機場景產生

透過如左側框內的單一三維樣本場景,可以快速地產生具有複雜幾何結構和真實外觀的新場景。該方法可以處理具有複雜拓撲結構的物體,如仙人掌,拱門和石凳等,生成的場景完美地保留了樣本場景的精細幾何和高品質外觀。目前沒有任何基於神經網路的生成模型能做到相似的品質和多樣性。 高解析度大場景產生
#此方法能有效率地產生極高解析度的三維內容。如上所示,我們可以透過輸入單一左上角解析度為512 x 512 x 200 的三維“千里江山圖” 的一部分,產生1328 x 512 x 200 解析度的“萬裡江山圖”,並渲染出4096 x 1024解析度的二維多視角圖。
真實世界無邊界場景產生
#作者在真實的自然場景上也驗證了所提出的生成方法。透過採用與 NeRF 類似的處理方法,明確的將前景和天空等背景分開後,單獨對前景內容進行生成,便可在真實世界的無邊界場景中生成新場景。
其他應用程式場景#場景編輯
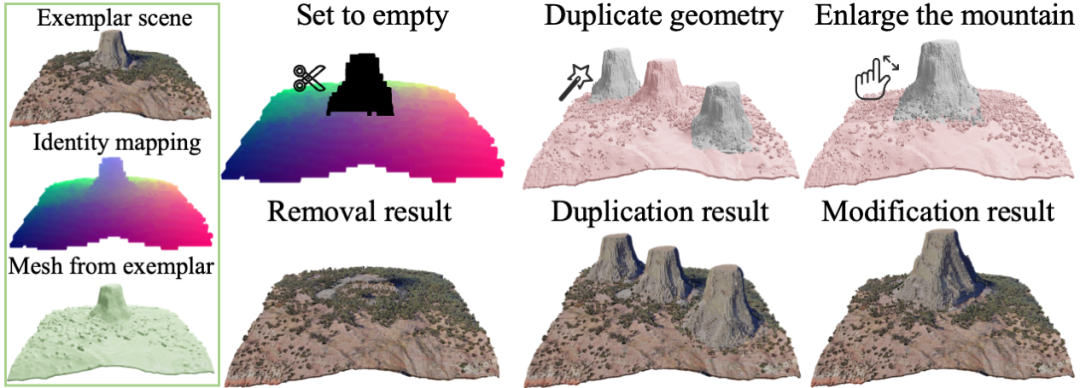
使用相同的生成演算法框架,透過加入人為指定限制,可以對三維場景內的物件進行刪除,複製和修改等編輯操作。如圖所示,可以移除場景中的山並自動補全孔洞,複製生成三座山峰或使山變得更大。
尺寸重定向
此方法也可以對三維物體進行拉伸或壓縮的同時,保持其局部的形狀。圖中綠色框線內為原始的樣本場景,將一列三維火車進行拉長的同時保持住窗戶的局部尺寸。
結構類比產生

和影像風格遷移類似,給定兩個場景A 和B,我們可以建立一個擁有A 的外觀和幾何特徵,但結構與B 相似的新場景。如我們可以參考一座雪山將另一座山變為三維雪山。
更換樣本場景
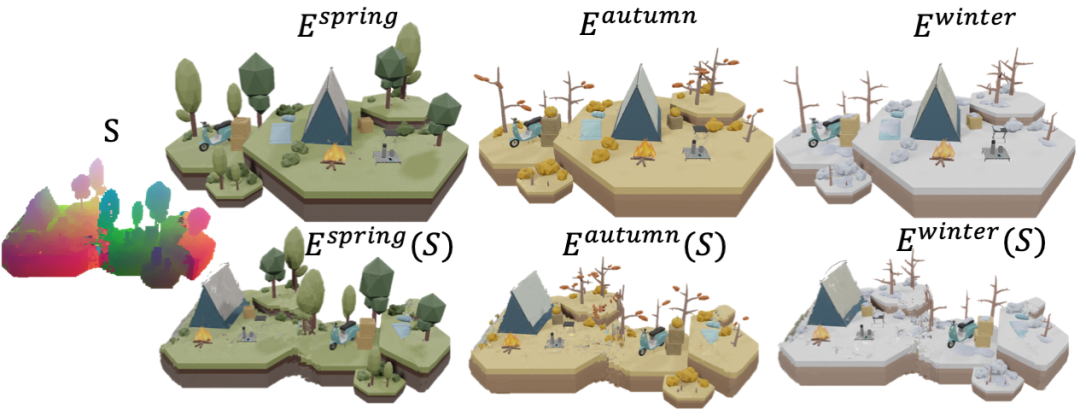
#由於該方法對生成場景採用了異質表達,透過簡單地修改其映射的樣本場景,便可產生更多樣化的新場景。如使用同一個生成場景映射場 S,映射不同時間或季節的場景,得到了更豐富的生成結果。
總結
這項工作面向三維內容生成領域,首次提出了一種基於單一樣本的三維自然場景生成模型,嘗試解決當前三維生成方法中數據需求大、算力開銷多、生成品質差等問題。這項工作聚焦於更普遍的、語意訊息較弱的自然場景,更多的關註生成內容的多樣性和品質。演算法主要受傳統電腦圖形學中與紋理影像生成相關的技術,結合近期的神經輻射場,能快速地產生高品質三維場景,並展示了多種實際應用。
未來展望
該工作有較強的通用性,不僅能結合當前的神經表達,也適用於傳統的渲染管線幾何表達,如多邊形網格(Mesh)。我們在關注大型數據和模型的同時,也應該不時回顧傳統的圖形學工具。研究人員相信,不久的未來,在3D AIGC 領域,傳統的圖形學工具結合高品質的神經表達以及強力的生成模型,將會碰撞出更絢爛的火花,進一步推進三維內容生成的質量和速度,解放人們的創造力。
這項研究得到了廣大網友的討論:
#有網友表示:(這項研究)對於遊戲開發來說十分棒,只需要建模單一模型就能產生許多新的版本。
對於上述觀點,有人表示完全同意,遊戲開發者、個人和小型公司可以從這類模型中得到幫助。

以上是三維場景產生:無需任何神經網路訓練,從單一範例產生多元結果的詳細內容。更多資訊請關注PHP中文網其他相關文章!